Generative Adversarial Networks (GANs)
Stryg for at vise menuen
Generative Adversarial Networks (GANs) er en klasse af generative modeller introduceret af Ian Goodfellow i 2014. De består af to neurale netværk — Generatoren og Diskriminatoren — som trænes samtidigt i en spilteoretisk ramme. Generatoren forsøger at producere data, der ligner de virkelige data, mens diskriminatoren forsøger at skelne mellem ægte data og genererede data.
GANs lærer at generere datasamples ud fra støj ved at løse et minimax-spil. I løbet af træningen bliver generatoren bedre til at producere realistiske data, og diskriminatoren bliver bedre til at skelne mellem ægte og falske data.
Arkitektur af en GAN
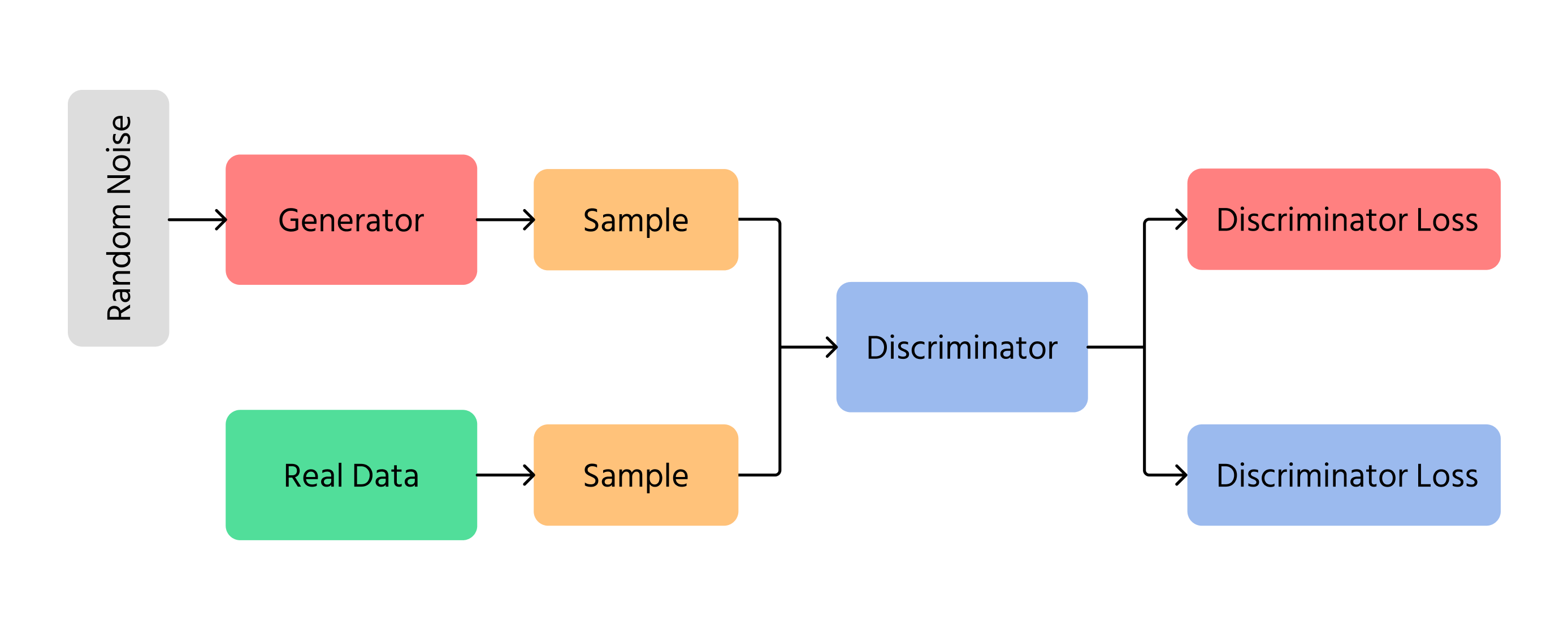
En grundlæggende GAN-model består af to kernekomponenter:
1. Generator (G)
- Modtager en tilfældig støjvektor z∼pz(z) som input;
- Transformerer den gennem et neuralt netværk til en datasample G(z), der skal ligne data fra den sande fordeling.
2. Discriminator (D)
- Modtager enten en ægte datasample x∼px(x) eller en genereret sample G(z);
- Returnerer en skalar mellem 0 og 1, som estimerer sandsynligheden for, at inputtet er ægte.
Disse to komponenter trænes samtidigt. Generatoren har til formål at producere realistiske samples for at narre diskriminatoren, mens diskriminatoren har til formål at identificere ægte versus genererede samples korrekt.
Minimax-spil i GANs
Kernen i GANs er minimax-spillet, et begreb fra spilteori. I denne opsætning:
- Generatoren G og diskriminatoren D er konkurrerende spillere;
- D har til formål at maksimere sin evne til at skelne mellem ægte og genererede data;
- G har til formål at minimere D's evne til at opdage dens falske data.
Denne dynamik definerer et nulsumsspil, hvor den ene spillers gevinst er den andens tab. Optimeringen er defineret som:
GminDmaxV(D,G)=Ex∼px[logD(x)]+Ez∼pz[log(1−D(G(z)))]Generatoren forsøger at narre diskriminatoren ved at generere prøver G(z), der er så tæt på ægte data som muligt.
Tabsfunktioner
Selvom det oprindelige GAN-mål definerer et minimax-spil, anvendes der i praksis alternative tabsfunktioner for at stabilisere træningen.
- Ikke-mættende generator-tab:
Dette hjælper generatoren med at modtage stærke gradienter, selv når diskriminatoren klarer sig godt.
- Diskriminator-tab:
Disse tab opmuntrer generatoren til at producere prøver, der øger diskriminatorens usikkerhed og forbedrer konvergensen under træning.
Centrale varianter af GAN-arkitekturer
Flere typer af GANs er opstået for at håndtere specifikke begrænsninger eller for at forbedre ydeevnen:

Betinget GAN (cGAN)
Betingede GANs udvider den standard GAN-ramme ved at introducere yderligere information (typisk labels) til både generatoren og diskriminatoren. I stedet for kun at generere data ud fra tilfældig støj, modtager generatoren både støj z og en betingelse y (f.eks. en klasse-label). Diskriminatoren modtager også y for at vurdere, om eksemplet er realistisk under den givne betingelse.
- Anvendelsesområder: klassebetinget billedgenerering, billede-til-billede-oversættelse, tekst-til-billede-generering.
Deep Convolutional GAN (DCGAN)
DCGANs erstatter de fuldt forbundne lag i de oprindelige GANs med konvolutions- og transponerede konvolutionslag, hvilket gør dem mere effektive til billedgenerering. De introducerer også arkitektoniske retningslinjer som at fjerne fuldt forbundne lag, anvende batch-normalisering og benytte ReLU/LeakyReLU-aktiveringer.
- Anvendelsesområder: fotorealistisk billedgenerering, læring af visuelle repræsentationer, uovervåget feature-læring.
CycleGAN CycleGANs løser problemet med ubundne billede-til-billede-oversættelser. I modsætning til andre modeller, der kræver parvise datasæt (f.eks. det samme foto i to forskellige stilarter), kan CycleGANs lære at oversætte mellem to domæner uden parvise eksempler. De introducerer to generatorer og to diskriminatorer, hvor hver er ansvarlig for at mappe i én retning (f.eks. fotos til malerier og omvendt), og håndhæver et cyklisk konsistens-tab for at sikre, at oversættelse fra ét domæne og tilbage returnerer det oprindelige billede. Dette tab er afgørende for at bevare indhold og struktur.
Cycle-Consistency Loss sikrer:
GBA(GAB(x))≈x og GAB(GBA(y))≈yhvor:
- GAB mapper billeder fra domæne A til domæne B;
- GBA mapper fra domæne B til domæne A.
- x∈A,y∈B.
Anvendelsesområder: konvertering af fotos til kunstværker, oversættelse fra hest til zebra, stemmekonvertering mellem talere.
StyleGAN
StyleGAN, udviklet af NVIDIA, introducerer stilbaseret kontrol i generatoren. I stedet for at tilføre en støjvektor direkte til generatoren, passerer den gennem et mapping-netværk for at producere "stilvektorer", der påvirker hvert lag i generatoren. Dette muliggør fin kontrol over visuelle egenskaber såsom hårfarve, ansigtsudtryk eller belysning.
Bemærkelsesværdige innovationer:
- Style mixing, tillader kombination af flere latente koder;
- Adaptive Instance Normalization (AdaIN), styrer feature maps i generatoren;
- Progressiv vækst, træning starter ved lav opløsning og øges over tid.
Anvendelsesområder: generering af ultrahøjopløselige billeder (f.eks. ansigter), kontrol af visuelle attributter, generering af kunst.
Sammenligning: GANs vs VAEs
GAN'er er en kraftfuld klasse af generative modeller, der kan producere meget realistiske data gennem en adversarial træningsproces. Kernen består af et minimax-spil mellem to netværk, hvor adversarial tab bruges til løbende at forbedre begge komponenter. Et solidt kendskab til deres arkitektur, tabfunktioner—inklusive varianter som cGAN, DCGAN, CycleGAN og StyleGAN—samt deres kontrast til andre modeller som VAE'er giver praktikere det nødvendige fundament til anvendelser inden for blandt andet generering af billeder, videosyntese, dataforøgelse og mere.
1. Hvilket af følgende beskriver bedst komponenterne i en grundlæggende GAN-arkitektur?
2. Hvad er målet med minimax-spillet i GANs?
3. Hvilket af følgende udsagn er sandt om forskellen mellem GANs og VAEs?
Tak for dine kommentarer!
Spørg AI
Spørg AI

Spørg om hvad som helst eller prøv et af de foreslåede spørgsmål for at starte vores chat
Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) er en klasse af generative modeller introduceret af Ian Goodfellow i 2014. De består af to neurale netværk — Generatoren og Diskriminatoren — som trænes samtidigt i en spilteoretisk ramme. Generatoren forsøger at producere data, der ligner de virkelige data, mens diskriminatoren forsøger at skelne mellem ægte data og genererede data.
GANs lærer at generere datasamples ud fra støj ved at løse et minimax-spil. I løbet af træningen bliver generatoren bedre til at producere realistiske data, og diskriminatoren bliver bedre til at skelne mellem ægte og falske data.
Arkitektur af en GAN
En grundlæggende GAN-model består af to kernekomponenter:
1. Generator (G)
- Modtager en tilfældig støjvektor z∼pz(z) som input;
- Transformerer den gennem et neuralt netværk til en datasample G(z), der skal ligne data fra den sande fordeling.
2. Discriminator (D)
- Modtager enten en ægte datasample x∼px(x) eller en genereret sample G(z);
- Returnerer en skalar mellem 0 og 1, som estimerer sandsynligheden for, at inputtet er ægte.
Disse to komponenter trænes samtidigt. Generatoren har til formål at producere realistiske samples for at narre diskriminatoren, mens diskriminatoren har til formål at identificere ægte versus genererede samples korrekt.
Minimax-spil i GANs
Kernen i GANs er minimax-spillet, et begreb fra spilteori. I denne opsætning:
- Generatoren G og diskriminatoren D er konkurrerende spillere;
- D har til formål at maksimere sin evne til at skelne mellem ægte og genererede data;
- G har til formål at minimere D's evne til at opdage dens falske data.
Denne dynamik definerer et nulsumsspil, hvor den ene spillers gevinst er den andens tab. Optimeringen er defineret som:
GminDmaxV(D,G)=Ex∼px[logD(x)]+Ez∼pz[log(1−D(G(z)))]Generatoren forsøger at narre diskriminatoren ved at generere prøver G(z), der er så tæt på ægte data som muligt.
Tabsfunktioner
Selvom det oprindelige GAN-mål definerer et minimax-spil, anvendes der i praksis alternative tabsfunktioner for at stabilisere træningen.
- Ikke-mættende generator-tab:
Dette hjælper generatoren med at modtage stærke gradienter, selv når diskriminatoren klarer sig godt.
- Diskriminator-tab:
Disse tab opmuntrer generatoren til at producere prøver, der øger diskriminatorens usikkerhed og forbedrer konvergensen under træning.
Centrale varianter af GAN-arkitekturer
Flere typer af GANs er opstået for at håndtere specifikke begrænsninger eller for at forbedre ydeevnen:
Betinget GAN (cGAN)
Betingede GANs udvider den standard GAN-ramme ved at introducere yderligere information (typisk labels) til både generatoren og diskriminatoren. I stedet for kun at generere data ud fra tilfældig støj, modtager generatoren både støj z og en betingelse y (f.eks. en klasse-label). Diskriminatoren modtager også y for at vurdere, om eksemplet er realistisk under den givne betingelse.
- Anvendelsesområder: klassebetinget billedgenerering, billede-til-billede-oversættelse, tekst-til-billede-generering.
Deep Convolutional GAN (DCGAN)
DCGANs erstatter de fuldt forbundne lag i de oprindelige GANs med konvolutions- og transponerede konvolutionslag, hvilket gør dem mere effektive til billedgenerering. De introducerer også arkitektoniske retningslinjer som at fjerne fuldt forbundne lag, anvende batch-normalisering og benytte ReLU/LeakyReLU-aktiveringer.
- Anvendelsesområder: fotorealistisk billedgenerering, læring af visuelle repræsentationer, uovervåget feature-læring.
CycleGAN CycleGANs løser problemet med ubundne billede-til-billede-oversættelser. I modsætning til andre modeller, der kræver parvise datasæt (f.eks. det samme foto i to forskellige stilarter), kan CycleGANs lære at oversætte mellem to domæner uden parvise eksempler. De introducerer to generatorer og to diskriminatorer, hvor hver er ansvarlig for at mappe i én retning (f.eks. fotos til malerier og omvendt), og håndhæver et cyklisk konsistens-tab for at sikre, at oversættelse fra ét domæne og tilbage returnerer det oprindelige billede. Dette tab er afgørende for at bevare indhold og struktur.
Cycle-Consistency Loss sikrer:
GBA(GAB(x))≈x og GAB(GBA(y))≈yhvor:
- GAB mapper billeder fra domæne A til domæne B;
- GBA mapper fra domæne B til domæne A.
- x∈A,y∈B.
Anvendelsesområder: konvertering af fotos til kunstværker, oversættelse fra hest til zebra, stemmekonvertering mellem talere.
StyleGAN
StyleGAN, udviklet af NVIDIA, introducerer stilbaseret kontrol i generatoren. I stedet for at tilføre en støjvektor direkte til generatoren, passerer den gennem et mapping-netværk for at producere "stilvektorer", der påvirker hvert lag i generatoren. Dette muliggør fin kontrol over visuelle egenskaber såsom hårfarve, ansigtsudtryk eller belysning.
Bemærkelsesværdige innovationer:
- Style mixing, tillader kombination af flere latente koder;
- Adaptive Instance Normalization (AdaIN), styrer feature maps i generatoren;
- Progressiv vækst, træning starter ved lav opløsning og øges over tid.
Anvendelsesområder: generering af ultrahøjopløselige billeder (f.eks. ansigter), kontrol af visuelle attributter, generering af kunst.
Sammenligning: GANs vs VAEs
GAN'er er en kraftfuld klasse af generative modeller, der kan producere meget realistiske data gennem en adversarial træningsproces. Kernen består af et minimax-spil mellem to netværk, hvor adversarial tab bruges til løbende at forbedre begge komponenter. Et solidt kendskab til deres arkitektur, tabfunktioner—inklusive varianter som cGAN, DCGAN, CycleGAN og StyleGAN—samt deres kontrast til andre modeller som VAE'er giver praktikere det nødvendige fundament til anvendelser inden for blandt andet generering af billeder, videosyntese, dataforøgelse og mere.
Tak for dine kommentarer!
