Diffusionsmodeller og Probabilistiske Generative Tilgange
Stryg for at vise menuen
Forståelse af diffusionsbaseret generering
Diffusionsmodeller er en kraftfuld type AI-model, der genererer data – især billeder – ved at lære at vende en proces, hvor tilfældig støj tilføjes. Forestil dig at se et klart billede gradvist blive sløret, som statisk støj på et TV. En diffusionsmodel lærer at gøre det modsatte: den tager støjfyldte billeder og rekonstruerer det oprindelige billede ved trinvis at fjerne støjen.
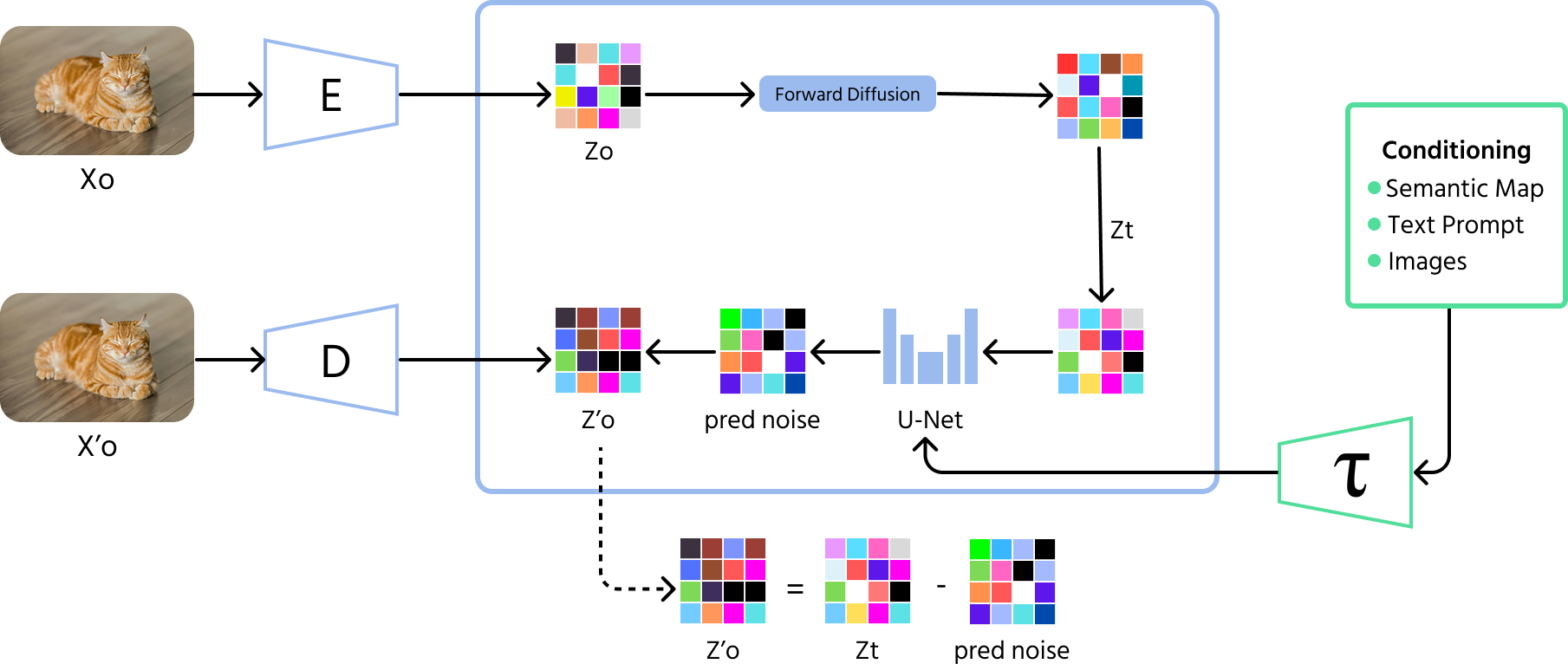
Processen involverer to hovedfaser:
- Fremadrettet proces (diffusion): tilfældig støj tilføjes gradvist til et billede over mange trin, så det til sidst bliver til ren støj;
- Omvendt proces (denoising): et neuralt netværk lærer at fjerne støjen trin for trin og rekonstruerer det oprindelige billede ud fra den støjfyldte version.
Diffusionsmodeller er kendt for deres evne til at producere billeder af høj kvalitet og realisme. Deres træning er typisk mere stabil sammenlignet med modeller som GANs, hvilket gør dem meget attraktive i moderne generativ AI.
Denoising Diffusion Probabilistiske Modeller (DDPMs)
Denoising diffusion probabilistiske modeller (DDPMs) er en populær type diffusionsmodel, der anvender probabilistiske principper og dyb læring til at fjerne støj fra billeder trin for trin.
Fremadrettet proces
I den fremadrettede proces starter vi med et rigtigt billede x0 og tilføjer gradvist Gaussisk støj over T tidsintervaller:
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)Hvor:
- xt: støjfyldt version af input ved tidsinterval;
- βt: lille variansplan, der styrer hvor meget støj der tilføjes;
- N: Gaussisk fordeling.
Den samlede støj tilføjet op til trin kan også udtrykkes som:
q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)Hvor:
- αˉt=∏s=1t(1−βs)
Omvendt proces
Målet med modellen er at lære den omvendte proces. Et neuralt netværk parameteriseret af θ forudsiger middelværdi og varians for den afstøjede fordeling:
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))hvor:
- xt: støjfyldt billede ved tidssteg t;
- xt−1: forudsagt mindre støjfyldt billede ved steg t−1;
- μθ: forudsagt middelværdi fra det neurale netværk;
- Σθ: forudsagt varians fra det neurale netværk.
Tabsfunktion
Træning indebærer at minimere forskellen mellem den faktiske støj og modellens forudsagte støj ved hjælp af følgende objektiv:
Lsimple=Ex0,ϵ,t[∣∣ϵ−ϵ0(αˉtx0+1−αˉtϵ,t)∣∣2]hvor:
- xt: oprindeligt inputbillede;
- ϵ: tilfældig Gaussisk støj;
- t: tidssteg under diffusion;
- ϵθ: neuralt netværks forudsigelse af støj;
- αˉt: Produkt af støjskema-parametre op til steg t.
Dette hjælper modellen med at blive bedre til at fjerne støj, hvilket forbedrer dens evne til at generere realistiske data.
Score-baseret generativ modellering
Score-baserede modeller er en anden klasse af diffusionsmodeller. I stedet for at lære den omvendte støjproces direkte, lærer de scorefunktionen:
∇xlogp(x)hvor:
- ∇xlogp(x): gradienten af log-sandsynlighedstætheden med hensyn til input x. Denne peger i retning af stigende sandsynlighed under datadistributionen;
- p(x): sandsynlighedsfordelingen for dataene.
Denne funktion angiver for modellen, i hvilken retning billedet skal bevæge sig for at blive mere lig de rigtige data. Disse modeller anvender derefter en samplingmetode som Langevin-dynamik til gradvist at flytte støjfyldte data mod områder med høj sandsynlighed.
Score-baserede modeller arbejder ofte i kontinuerlig tid ved hjælp af stokastiske differentialligninger (SDE'er). Denne kontinuerlige tilgang giver fleksibilitet og kan producere høj kvalitet på tværs af forskellige datatyper.
Anvendelser inden for højopløselig billedgenerering
Diffusionsmodeller har revolutioneret generative opgaver, især inden for højopløselig visuel generering. Bemærkelsesværdige anvendelser inkluderer:
- Stable Diffusion: en latent diffusionsmodel, der genererer billeder ud fra tekstprompter. Den kombinerer en U-Net-baseret denoising-model med en variational autoencoder (VAE) for at operere i latent rum;
- DALL·E 2: kombinerer CLIP-embedding og diffusionsbaseret dekodning for at generere meget realistiske og semantiske billeder ud fra tekst;
- MidJourney: en diffusionsbaseret billedgenereringsplatform kendt for at producere visuelt høj kvalitet og kunstnerisk stilede billeder ud fra abstrakte eller kreative prompts.
Disse modeller anvendes til kunstgenerering, fotorealistisk syntese, inpainting, superopløsning og meget mere.
Sammenfatning
Diffusionsmodeller definerer en ny æra inden for generativ modellering ved at behandle datagenerering som en omvendt stokastisk proces over tid. Gennem DDPM'er og score-baserede modeller opnår de robust træning, høj prøve-kvalitet og overbevisende resultater på tværs af forskellige modaliteter. Deres forankring i sandsynligheds- og termodynamiske principper gør dem både matematisk elegante og praktisk kraftfulde.
1. Hvad er hovedideen bag generative modeller baseret på diffusion?
2. Hvad bruger DDPM's fremadrettede proces til at tilføje støj ved hvert trin?
3. Hvilken af følgende beskriver bedst scorefunktionens rolle ∇xlogp(x) i score-baseret generativ modellering?
Tak for dine kommentarer!
Spørg AI
Spørg AI

Spørg om hvad som helst eller prøv et af de foreslåede spørgsmål for at starte vores chat
