Oversigt over Populære CNN-Modeller
Stryg for at vise menuen
Convolutional neurale netværk (CNN'er) har udviklet sig markant, hvor forskellige arkitekturer har forbedret nøjagtighed, effektivitet og skalerbarhed. Dette kapitel undersøger fem centrale CNN-modeller, der har formet deep learning: LeNet, AlexNet, VGGNet, ResNet og InceptionNet.
LeNet: Grundlaget for CNN'er
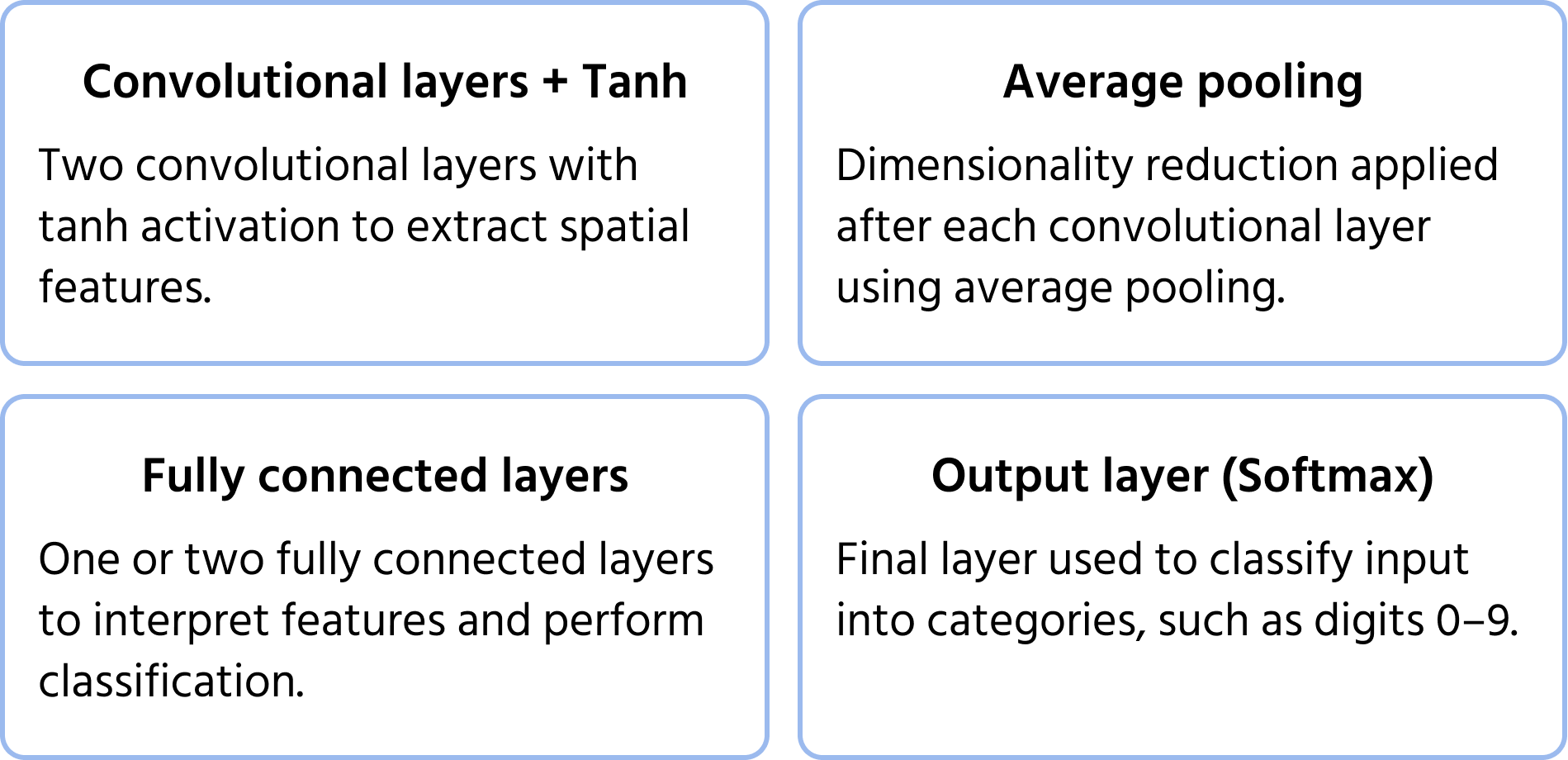
En af de første convolutional neurale netværksarkitekturer, foreslået af Yann LeCun i 1998 til håndskrevet cifergenkendelse. Den lagde grundlaget for moderne CNN'er ved at introducere nøglekomponenter som konvolutioner, pooling og fuldt forbundne lag. Du kan lære mere om modellen i dokumentationen.
Centrale arkitekturegenskaber
AlexNet: Gennembrud inden for dyb læring
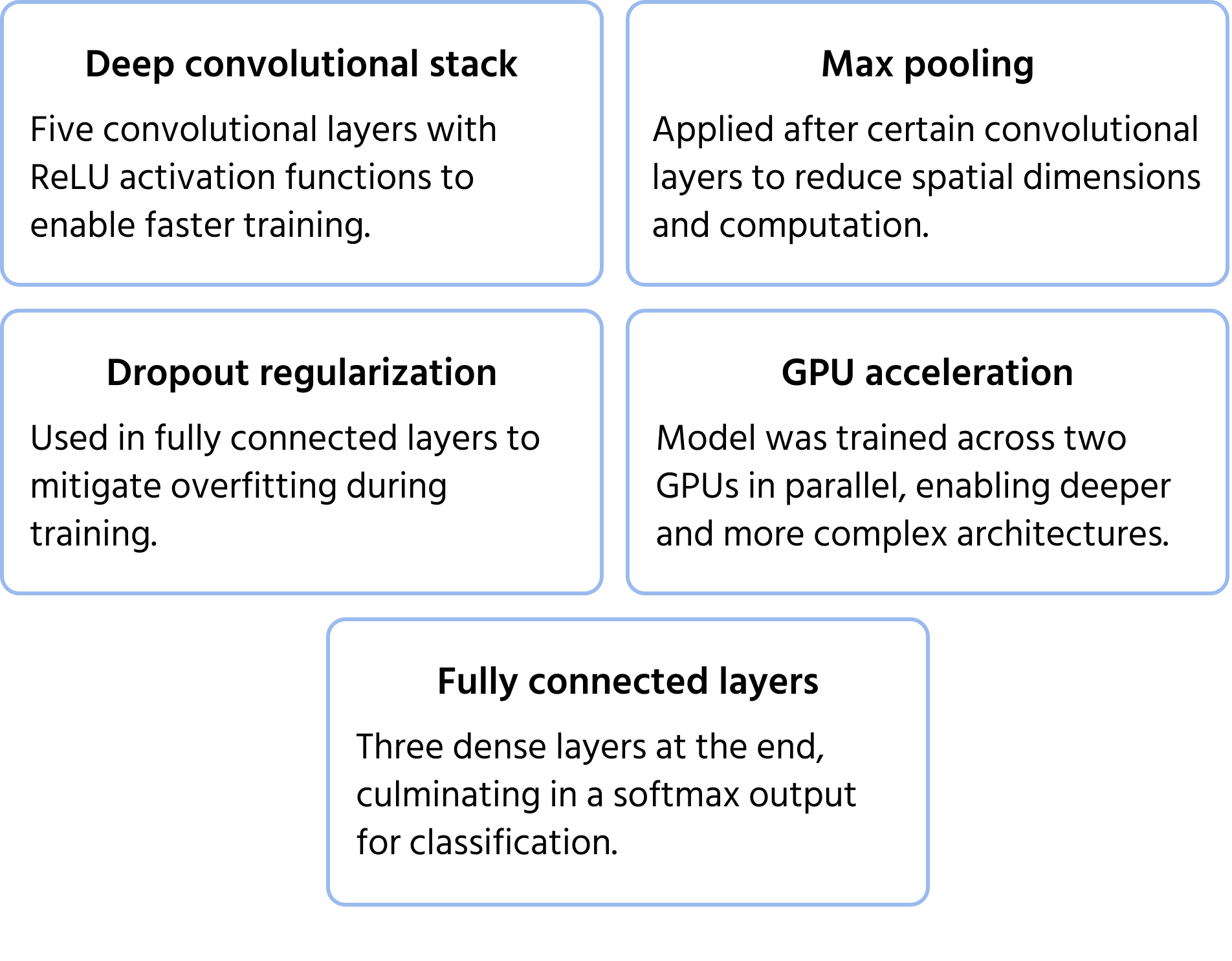
Et banebrydende CNN-arkitektur, der vandt ImageNet-konkurrencen i 2012. AlexNet demonstrerede, at dybe konvolutionsnetværk markant kunne overgå traditionelle maskinlæringsmetoder til billedklassificering i stor skala. Modellen introducerede innovationer, der er blevet standard i moderne dyb læring. Du kan læse mere om modellen i dokumentationen.
Centrale arkitekturelle egenskaber
VGGNet: Dybere netværk med ensartede filtre
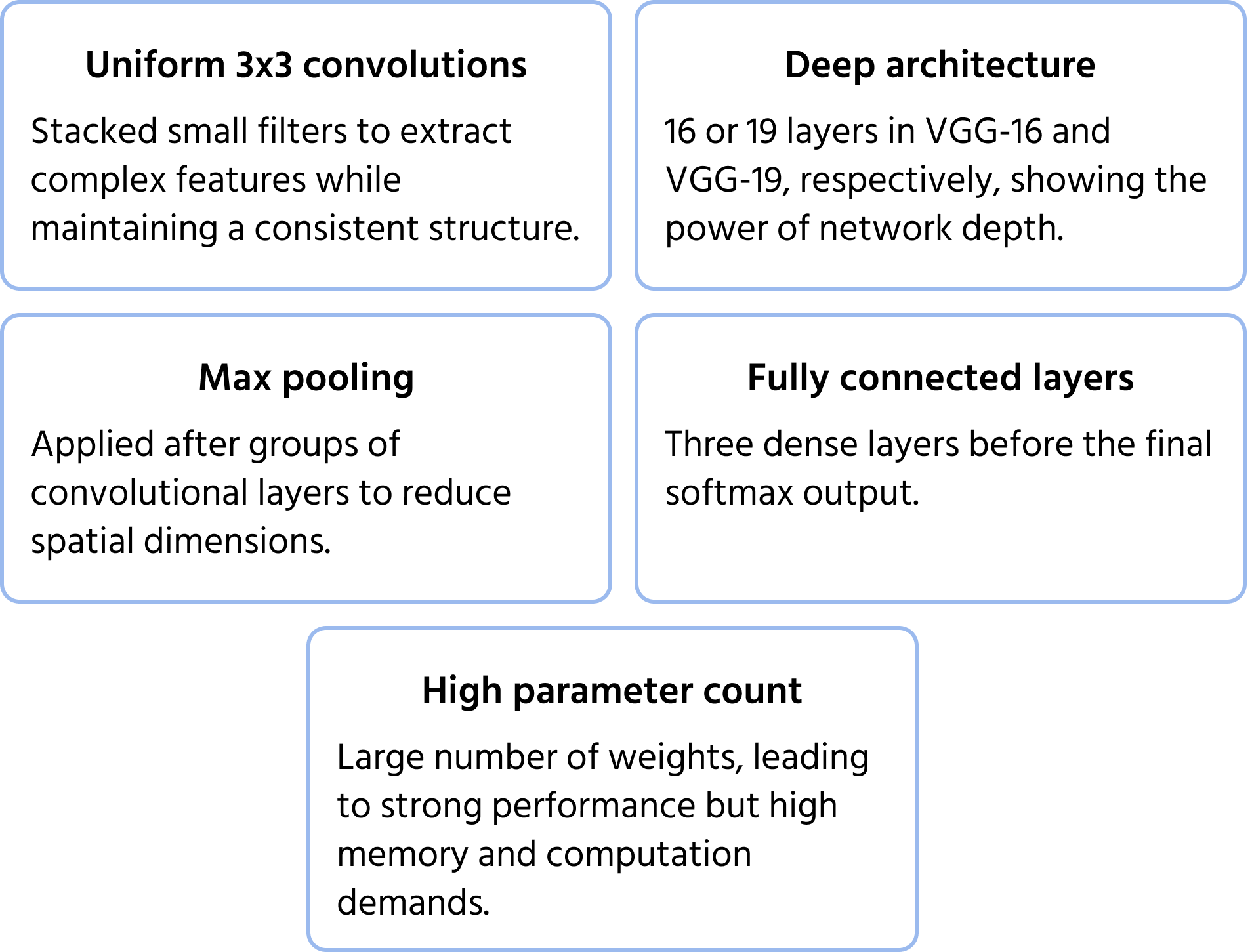
Udviklet af Visual Geometry Group ved Oxford, fremhævede VGGNet dybde og enkelhed ved at anvende ensartede 3×3 konvolutionsfiltre. Modellen demonstrerede, at stabling af små filtre i dybe netværk markant kunne forbedre ydeevnen, hvilket førte til udbredte varianter som VGG-16 og VGG-19. Du kan læse mere om modellen i dokumentationen.
Centrale arkitekturelle egenskaber
ResNet: Løsning på dybdeproblemet
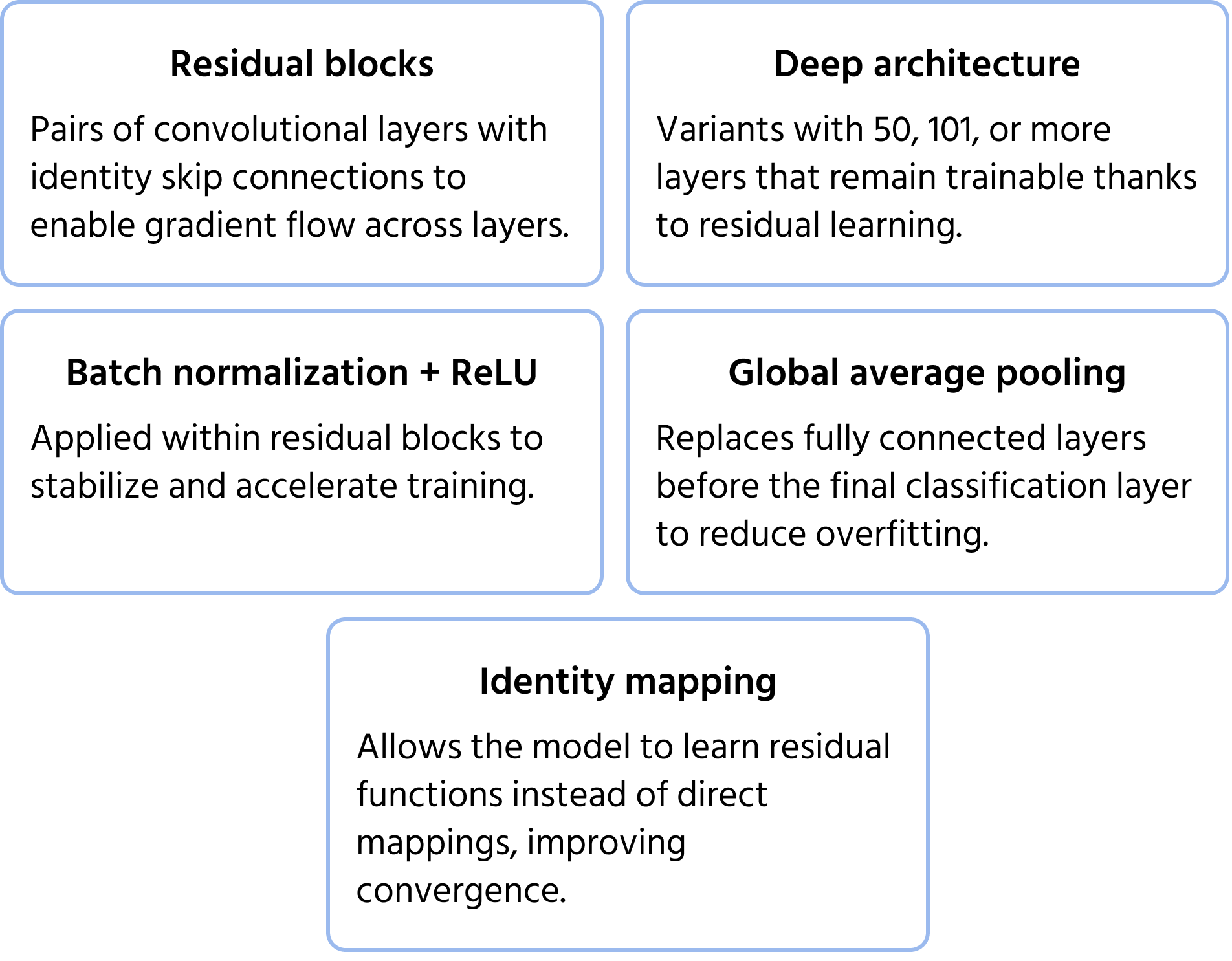
ResNet (Residual Networks), introduceret af Microsoft i 2015, løste problemet med forsvindende gradient, som opstår under træning af meget dybe netværk. Traditionelle dybe netværk har udfordringer med træningseffektivitet og præstationsforringelse, men ResNet overvandt dette problem med skip connections (residual learning). Disse genveje tillader information at omgå visse lag, hvilket sikrer, at gradienter fortsat kan forplante sig effektivt. ResNet-arkitekturer som ResNet-50 og ResNet-101 muliggjorde træning af netværk med hundreder af lag, hvilket markant forbedrede nøjagtigheden af billedklassificering. Du kan læse mere om modellen i dokumentationen.
Centrale arkitekturelle egenskaber
InceptionNet: Multi-skala feature-ekstraktion
InceptionNet (også kendt som GoogLeNet) bygger videre på inception-modulet for at skabe en dyb, men effektiv arkitektur. I stedet for at stable lag sekventielt, anvender InceptionNet parallelle veje til at udtrække features på forskellige niveauer. Du kan læse mere om modellen i dokumentationen.
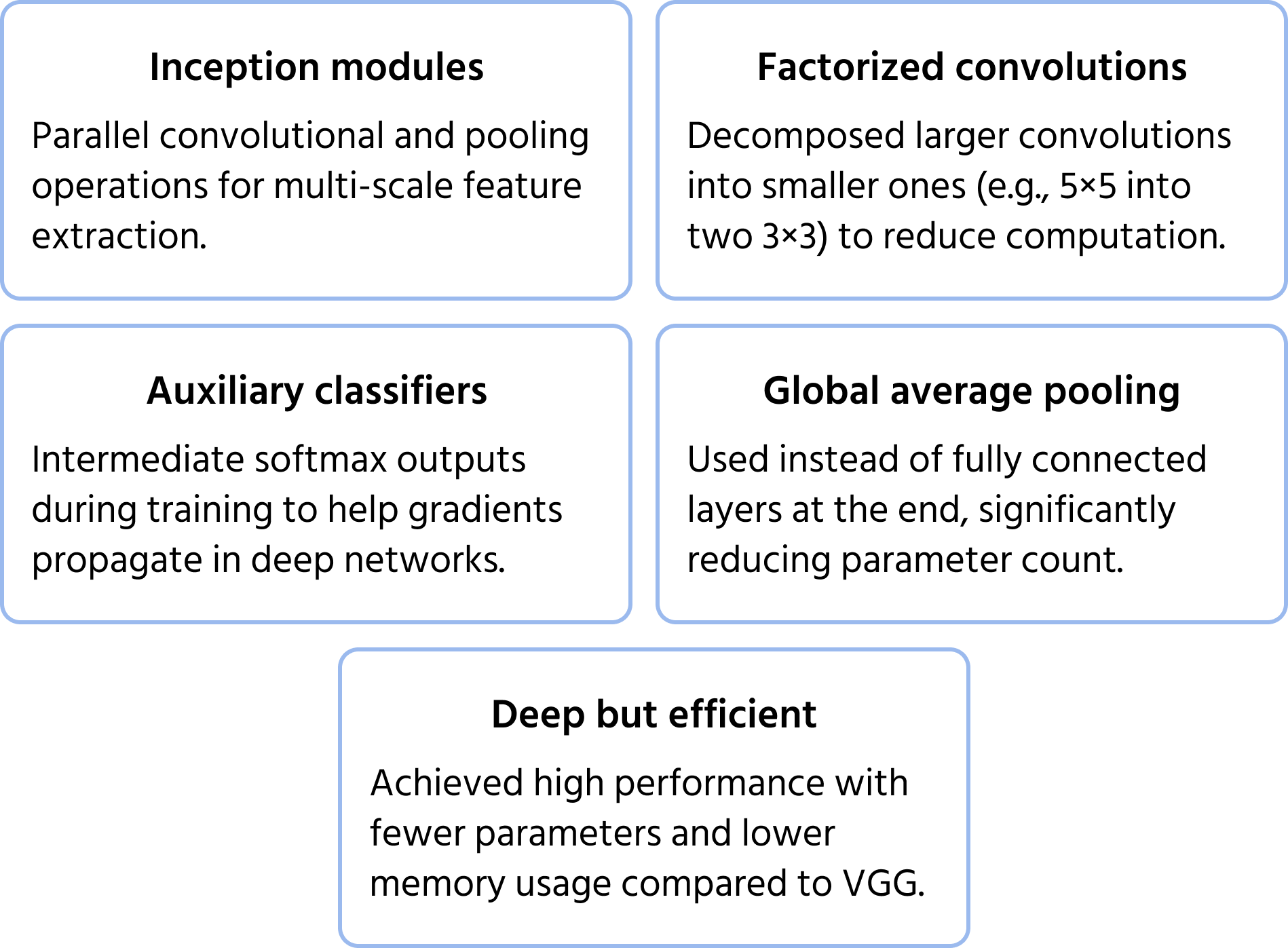
Centrale optimeringer omfatter:
- Faktorerede konvolutioner for at reducere beregningsomkostninger;
- Hjælpeklassifikatorer i mellemliggende lag for at forbedre træningsstabilitet;
- Global gennemsnits-pooling i stedet for fuldt forbundne lag, hvilket reducerer antallet af parametre og bevarer ydeevnen.
Denne struktur gør det muligt for InceptionNet at være dybere end tidligere CNN'er som VGG, uden markant øgede beregningskrav.
Centrale arkitekturfunktioner
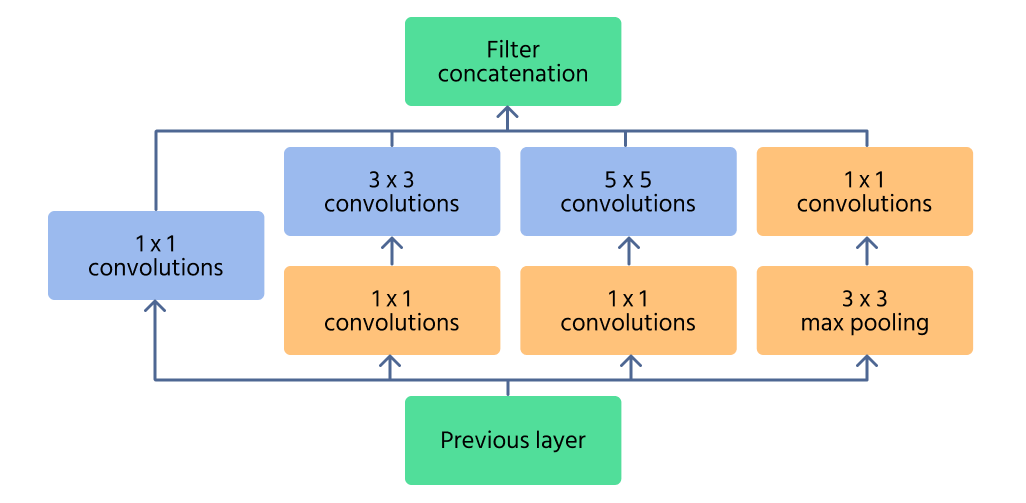
Inception-modul
Inception-modulet er den centrale komponent i InceptionNet, designet til effektivt at opfange træk på flere skalaer. I stedet for at anvende en enkelt konvolutionsoperation, behandler modulet inputtet med flere filterstørrelser (1×1, 3×3, 5×5) parallelt. Dette gør det muligt for netværket at genkende både fine detaljer og store mønstre i et billede.
For at reducere den beregningsmæssige omkostning anvendes 1×1 convolutions før større filtre. Disse reducerer antallet af inputkanaler, hvilket gør netværket mere effektivt. Derudover hjælper max pooling-lag i modulet med at bevare væsentlige træk, samtidig med at dimensionaliteten kontrolleres.
Eksempel
Overvej et eksempel for at illustrere, hvordan reduktion af dimensioner mindsker den beregningsmæssige belastning. Antag, at vi skal konvolvere 28 × 28 × 192 input feature maps med 5 × 5 × 32 filters. Denne operation vil kræve cirka 120,42 millioner beregninger.

Number of operations = (2828192) * (5532) = 120,422,400 operations
Lad os udføre beregningerne igen, men denne gang indsætte et 1×1 convolutional layer før vi anvender 5×5 convolution på de samme input-feature-maps.

Number of operations for 1x1 convolution = (2828192) * (1116) = 2.408.448 operations
Number of operations for 5x5 convolution = (282816) * (5532) = 10.035.200 operations
Total number of operations 2.408.448 + 10.035.200 = 12.443.648 operations
Hver af disse CNN-arkitekturer har spillet en afgørende rolle i udviklingen af computer vision og har haft indflydelse på anvendelser inden for sundhedspleje, autonome systemer, sikkerhed og real-time billedbehandling. Fra LeNet's grundlæggende principper til InceptionNet's multi-skala feature-ekstraktion har disse modeller løbende udvidet grænserne for deep learning og banet vejen for endnu mere avancerede arkitekturer i fremtiden.
1. Hvad var den primære innovation, som ResNet introducerede, der gjorde det muligt at træne ekstremt dybe netværk?
2. Hvordan forbedrer InceptionNet den beregningsmæssige effektivitet sammenlignet med traditionelle CNN'er?
3. Hvilken CNN-arkitektur introducerede først konceptet med at bruge små 3×3 konvolutionsfiltre gennem hele netværket?
Tak for dine kommentarer!
Spørg AI
Spørg AI

Spørg om hvad som helst eller prøv et af de foreslåede spørgsmål for at starte vores chat
Oversigt over Populære CNN-Modeller
Convolutional neurale netværk (CNN'er) har udviklet sig markant, hvor forskellige arkitekturer har forbedret nøjagtighed, effektivitet og skalerbarhed. Dette kapitel undersøger fem centrale CNN-modeller, der har formet deep learning: LeNet, AlexNet, VGGNet, ResNet og InceptionNet.
LeNet: Grundlaget for CNN'er
En af de første convolutional neurale netværksarkitekturer, foreslået af Yann LeCun i 1998 til håndskrevet cifergenkendelse. Den lagde grundlaget for moderne CNN'er ved at introducere nøglekomponenter som konvolutioner, pooling og fuldt forbundne lag. Du kan lære mere om modellen i dokumentationen.
Centrale arkitekturegenskaber
AlexNet: Gennembrud inden for dyb læring
Et banebrydende CNN-arkitektur, der vandt ImageNet-konkurrencen i 2012. AlexNet demonstrerede, at dybe konvolutionsnetværk markant kunne overgå traditionelle maskinlæringsmetoder til billedklassificering i stor skala. Modellen introducerede innovationer, der er blevet standard i moderne dyb læring. Du kan læse mere om modellen i dokumentationen.
Centrale arkitekturelle egenskaber
VGGNet: Dybere netværk med ensartede filtre
Udviklet af Visual Geometry Group ved Oxford, fremhævede VGGNet dybde og enkelhed ved at anvende ensartede 3×3 konvolutionsfiltre. Modellen demonstrerede, at stabling af små filtre i dybe netværk markant kunne forbedre ydeevnen, hvilket førte til udbredte varianter som VGG-16 og VGG-19. Du kan læse mere om modellen i dokumentationen.
Centrale arkitekturelle egenskaber
ResNet: Løsning på dybdeproblemet
ResNet (Residual Networks), introduceret af Microsoft i 2015, løste problemet med forsvindende gradient, som opstår under træning af meget dybe netværk. Traditionelle dybe netværk har udfordringer med træningseffektivitet og præstationsforringelse, men ResNet overvandt dette problem med skip connections (residual learning). Disse genveje tillader information at omgå visse lag, hvilket sikrer, at gradienter fortsat kan forplante sig effektivt. ResNet-arkitekturer som ResNet-50 og ResNet-101 muliggjorde træning af netværk med hundreder af lag, hvilket markant forbedrede nøjagtigheden af billedklassificering. Du kan læse mere om modellen i dokumentationen.
Centrale arkitekturelle egenskaber
InceptionNet: Multi-skala feature-ekstraktion
InceptionNet (også kendt som GoogLeNet) bygger videre på inception-modulet for at skabe en dyb, men effektiv arkitektur. I stedet for at stable lag sekventielt, anvender InceptionNet parallelle veje til at udtrække features på forskellige niveauer. Du kan læse mere om modellen i dokumentationen.
Centrale optimeringer omfatter:
- Faktorerede konvolutioner for at reducere beregningsomkostninger;
- Hjælpeklassifikatorer i mellemliggende lag for at forbedre træningsstabilitet;
- Global gennemsnits-pooling i stedet for fuldt forbundne lag, hvilket reducerer antallet af parametre og bevarer ydeevnen.
Denne struktur gør det muligt for InceptionNet at være dybere end tidligere CNN'er som VGG, uden markant øgede beregningskrav.
Centrale arkitekturfunktioner
Inception-modul
Inception-modulet er den centrale komponent i InceptionNet, designet til effektivt at opfange træk på flere skalaer. I stedet for at anvende en enkelt konvolutionsoperation, behandler modulet inputtet med flere filterstørrelser (1×1, 3×3, 5×5) parallelt. Dette gør det muligt for netværket at genkende både fine detaljer og store mønstre i et billede.
For at reducere den beregningsmæssige omkostning anvendes 1×1 convolutions før større filtre. Disse reducerer antallet af inputkanaler, hvilket gør netværket mere effektivt. Derudover hjælper max pooling-lag i modulet med at bevare væsentlige træk, samtidig med at dimensionaliteten kontrolleres.
Eksempel
Overvej et eksempel for at illustrere, hvordan reduktion af dimensioner mindsker den beregningsmæssige belastning. Antag, at vi skal konvolvere 28 × 28 × 192 input feature maps med 5 × 5 × 32 filters. Denne operation vil kræve cirka 120,42 millioner beregninger.
Number of operations = (2828192) * (5532) = 120,422,400 operations
Lad os udføre beregningerne igen, men denne gang indsætte et 1×1 convolutional layer før vi anvender 5×5 convolution på de samme input-feature-maps.
Number of operations for 1x1 convolution = (2828192) * (1116) = 2.408.448 operations
Number of operations for 5x5 convolution = (282816) * (5532) = 10.035.200 operations
Total number of operations 2.408.448 + 10.035.200 = 12.443.648 operations
Hver af disse CNN-arkitekturer har spillet en afgørende rolle i udviklingen af computer vision og har haft indflydelse på anvendelser inden for sundhedspleje, autonome systemer, sikkerhed og real-time billedbehandling. Fra LeNet's grundlæggende principper til InceptionNet's multi-skala feature-ekstraktion har disse modeller løbende udvidet grænserne for deep learning og banet vejen for endnu mere avancerede arkitekturer i fremtiden.
Tak for dine kommentarer!
