Implementering af Word2Vec
Stryg for at vise menuen
Efter at have forstået, hvordan Word2Vec fungerer, fortsætter vi med at implementere det ved hjælp af Python. Gensim-biblioteket, et robust open source-værktøj til behandling af naturligt sprog, tilbyder en ligetil implementering gennem sin Word2Vec-klasse i gensim.models.
Forberedelse af data
Word2Vec kræver, at tekstdata tokeniseres, dvs. opdeles i en liste af lister, hvor hver indre liste indeholder ord fra en bestemt sætning. I dette eksempel bruger vi romanen Emma af den engelske forfatter Jane Austen som vores korpus. Vi indlæser en CSV-fil med forbehandlede sætninger og opdeler derefter hver sætning i ord:
12345678import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') # Split each sentence into words sentences = emma_df['Sentence'].str.split() # Print the fourth sentence (list of words) print(sentences[3])
emma_df['Sentence'].str.split() anvender .split()-metoden på hver sætning i kolonnen 'Sentence', hvilket resulterer i en liste af ord for hver sætning. Da sætningerne allerede var forbehandlet, med ord adskilt af mellemrum, er .split()-metoden tilstrækkelig til denne tokenisering.
Træning af Word2Vec-modellen
Fokus på træning af Word2Vec-modellen ved brug af de tokeniserede data. Word2Vec-klassen tilbyder en række parametre til tilpasning. De mest anvendte parametre er:
vector_size(standard 100): dimensionalitet eller størrelse på word embeddings;window(standard 5): kontekstvinduestørrelse;min_count(standard 5): ord, der forekommer færre gange end denne værdi, ignoreres;sg(standard 0): valg af modelarkitektur (1 for Skip-gram, 0 for CBoW).cbow_mean(standard 1): angiver om CBoW inputkonteksten summeres (0) eller gennemsnittes (1)
Med hensyn til modelarkitekturer er CBoW velegnet til større datasæt og situationer, hvor beregningseffektivitet er afgørende. Skip-gram foretrækkes til opgaver, der kræver detaljeret forståelse af ordkontekster, særligt effektiv ved mindre datasæt eller ved håndtering af sjældne ord.
12345678from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() # Initialize the model model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0)
Her sætter vi embedding-størrelsen til 200, kontekstvinduesstørrelsen til 5, og inkluderer alle ord ved at sætte min_count=1. Ved at sætte sg=0 valgte vi at bruge CBoW-modellen.
Valg af den rette embedding-størrelse og kontekstvindue indebærer kompromiser. Større embeddings fanger mere betydning, men øger beregningsomkostningerne og risikoen for overfitting. Mindre kontekstvinduer er bedre til at fange syntaks, mens større er bedre til at fange semantik.
Find lignende ord
Når ord er repræsenteret som vektorer, kan vi sammenligne dem for at måle lighed. Selvom det er muligt at bruge afstand, bærer retningen af en vektor ofte mere semantisk betydning end dens størrelse, især i word embeddings.
Det er dog ikke så praktisk at bruge vinklen som et lighedsmetrik direkte. I stedet kan vi bruge cosinus til vinklen mellem to vektorer, også kendt som cosinus-lighed. Den varierer fra -1 til 1, hvor højere værdier indikerer stærkere lighed. Denne tilgang fokuserer på, hvor ens vektorerne er orienteret, uanset deres længde, hvilket gør den ideel til at sammenligne ords betydning. Her er en illustration:
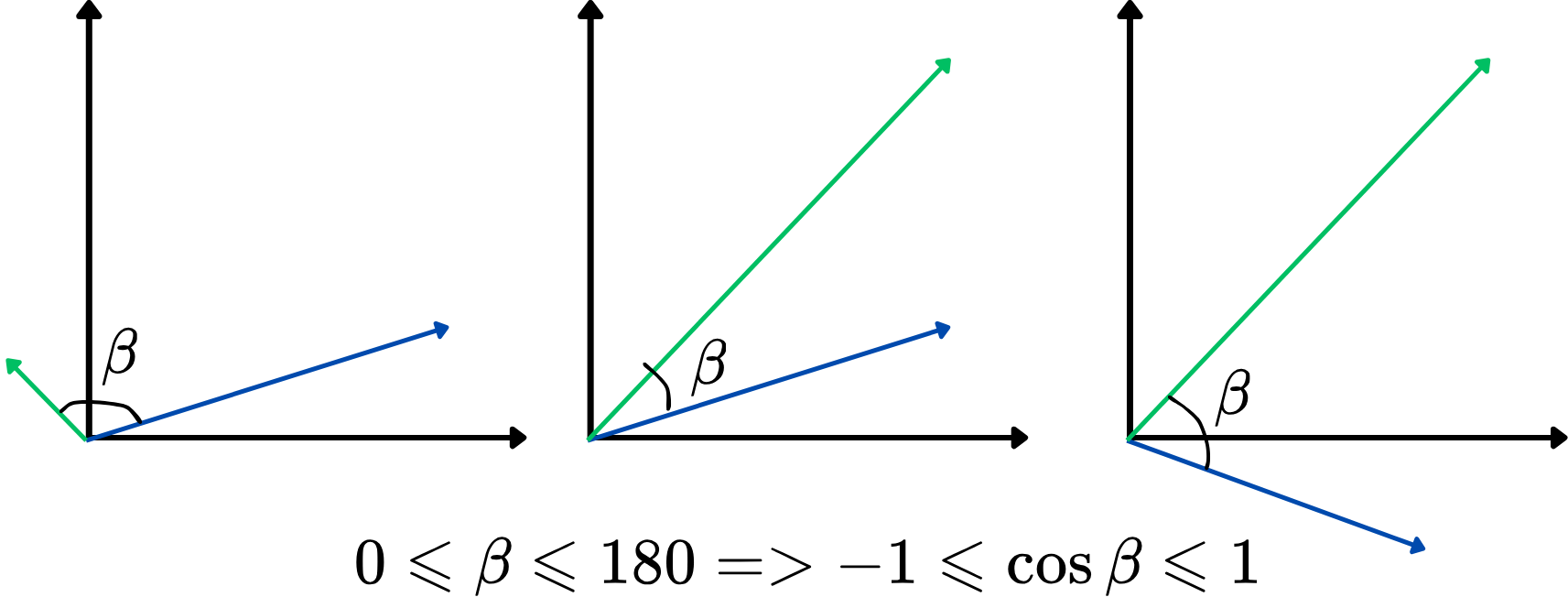
Jo højere cosinus-lighed, desto mere ligner de to vektorer hinanden, og omvendt. For eksempel, hvis to ordvektorer har en cosinus-lighed tæt på 1 (vinklen tæt på 0 grader), indikerer det, at de er nært beslægtede eller ligner hinanden i kontekst inden for vektorrummet.
Lad os nu finde de fem mest lignende ord til ordet "man" ved hjælp af cosinus-lighed:
12345678910from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0) # Retrieve the top-5 most similar words to 'man' similar_words = model.wv.most_similar('man', topn=5) print(similar_words)
model.wv giver adgang til ordvektorerne i den trænede model, mens metoden .most_similar() finder de ord, hvis indlejringer ligger tættest på indlejringen af det angivne ord, baseret på cosinus-lighed. Parameteren topn bestemmer antallet af top-N lignende ord, der returneres.
Tak for dine kommentarer!
Spørg AI
Spørg AI

Spørg om hvad som helst eller prøv et af de foreslåede spørgsmål for at starte vores chat
