single
Implementering af Neurale Netværk
Stryg for at vise menuen
Grundlæggende oversigt over neurale netværk
Du er nu nået til et punkt, hvor du har den nødvendige viden om TensorFlow til selv at oprette neurale netværk. Selvom de fleste neurale netværk i virkeligheden er komplekse og typisk bygges ved hjælp af høj-niveau biblioteker som Keras, vil vi konstruere et grundlæggende netværk ved brug af fundamentale TensorFlow-værktøjer. Denne tilgang giver praktisk erfaring med lav-niveau tensor-manipulation, hvilket hjælper med at forstå de underliggende processer.
I tidligere kurser som Introduktion til neurale netværk, husker du måske, hvor meget tid og arbejde det krævede at bygge selv et simpelt neuralt netværk, hvor hver neuron blev behandlet individuelt.

TensorFlow forenkler denne proces betydeligt. Ved at udnytte tensorer kan du indkapsle komplekse beregninger, hvilket reducerer behovet for indviklet kodning. Vores primære opgave er at opsætte en sekventiel pipeline af tensor-operationer.
Her er en kort genopfriskning af trinnene for at få en træningsproces for et neuralt netværk i gang:
Dataklargøring og modeloprettelse
Den indledende fase af træningen af et neuralt netværk omfatter klargøring af data, hvilket indebærer både input og output, som netværket skal lære fra. Derudover fastlægges modellens hyperparametre – disse er parametre, der forbliver uændrede gennem hele træningsprocessen. Vægtene initialiseres, typisk trukket fra en normalfordeling, og biaserne sættes ofte til nul.
Fremadrettet propagering
Ved fremadrettet propagering følger hvert lag i netværket typisk disse trin:
- Multiplicer lagets input med dets vægte.
- Læg en bias til resultatet.
- Anvend en aktiveringsfunktion på denne sum.
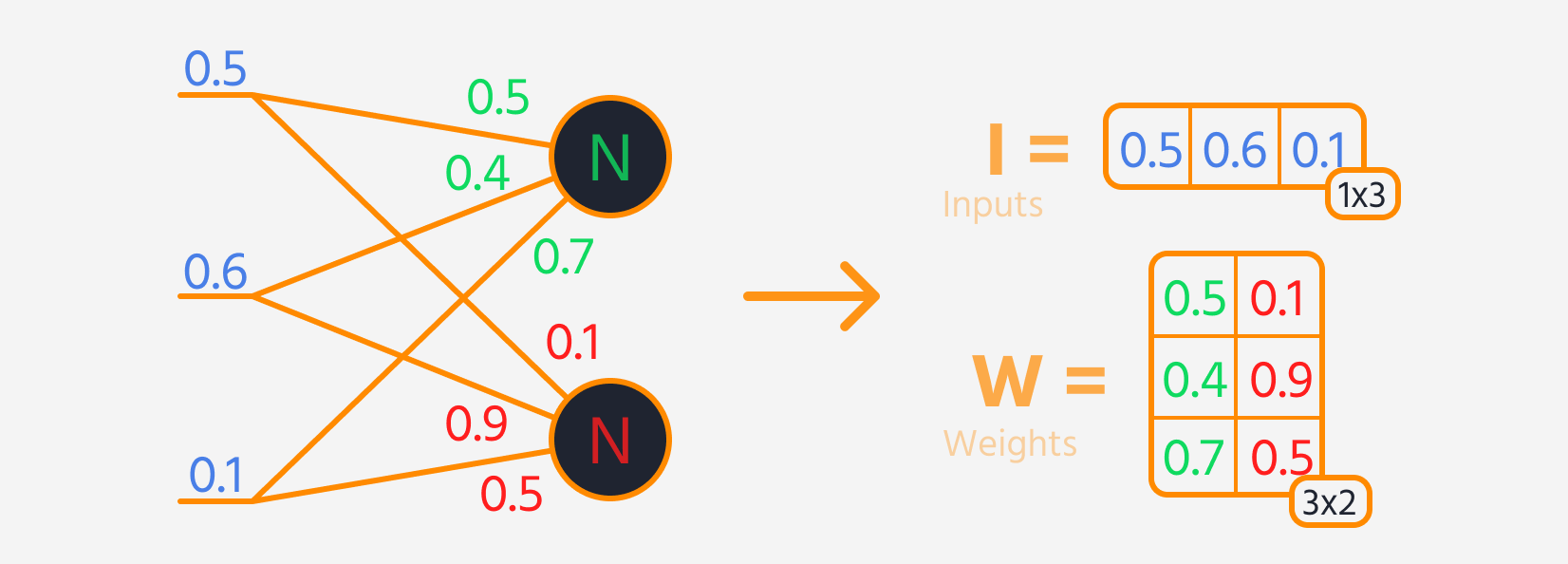
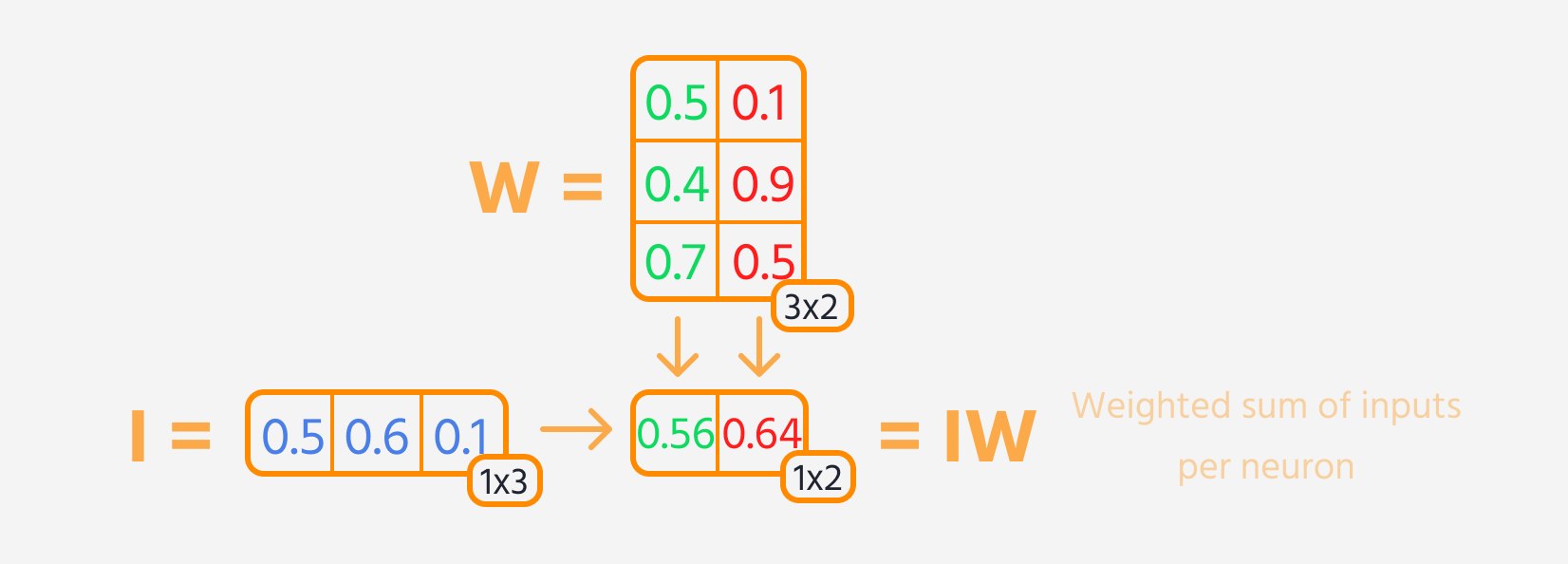
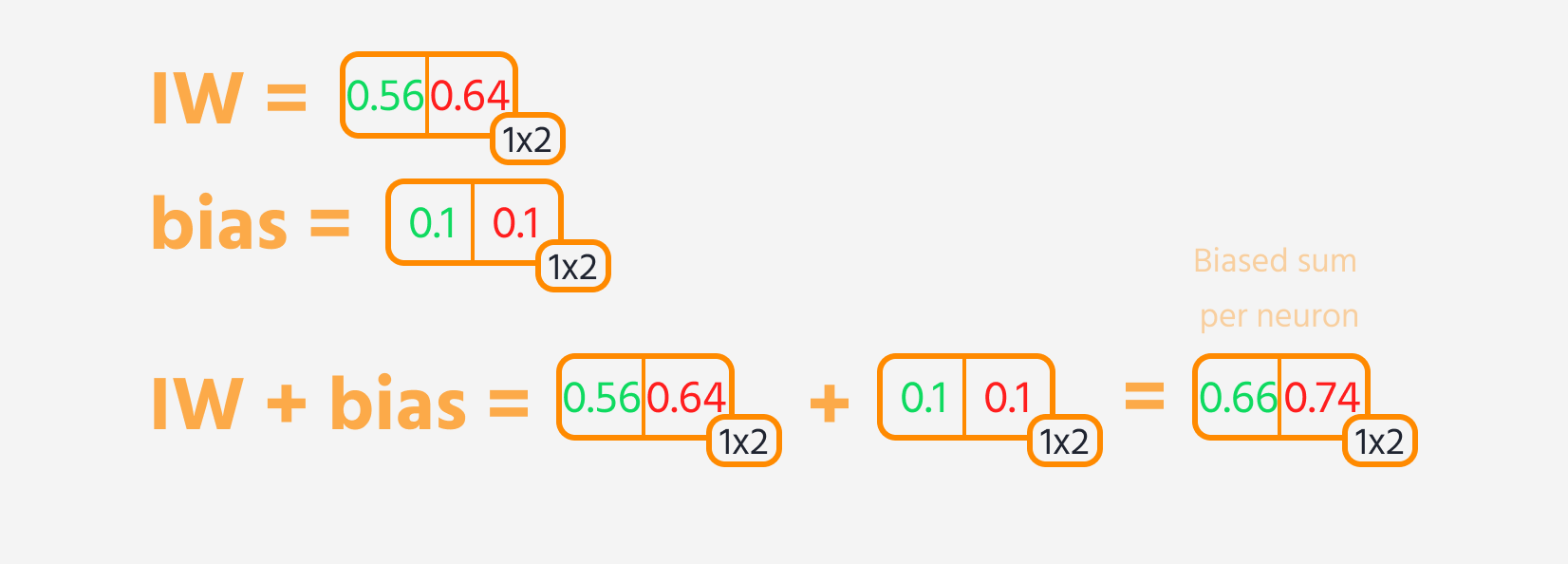


Derefter kan tab beregnes.
Baglæns propagering
Næste trin er baglæns propagering, hvor vægte og bias justeres baseret på deres indflydelse på tabet. Denne indflydelse er repræsenteret ved gradienten, som TensorFlows Gradient Tape automatisk beregner. Vægte og bias opdateres ved at trække gradienten, skaleret med læringsraten fra.
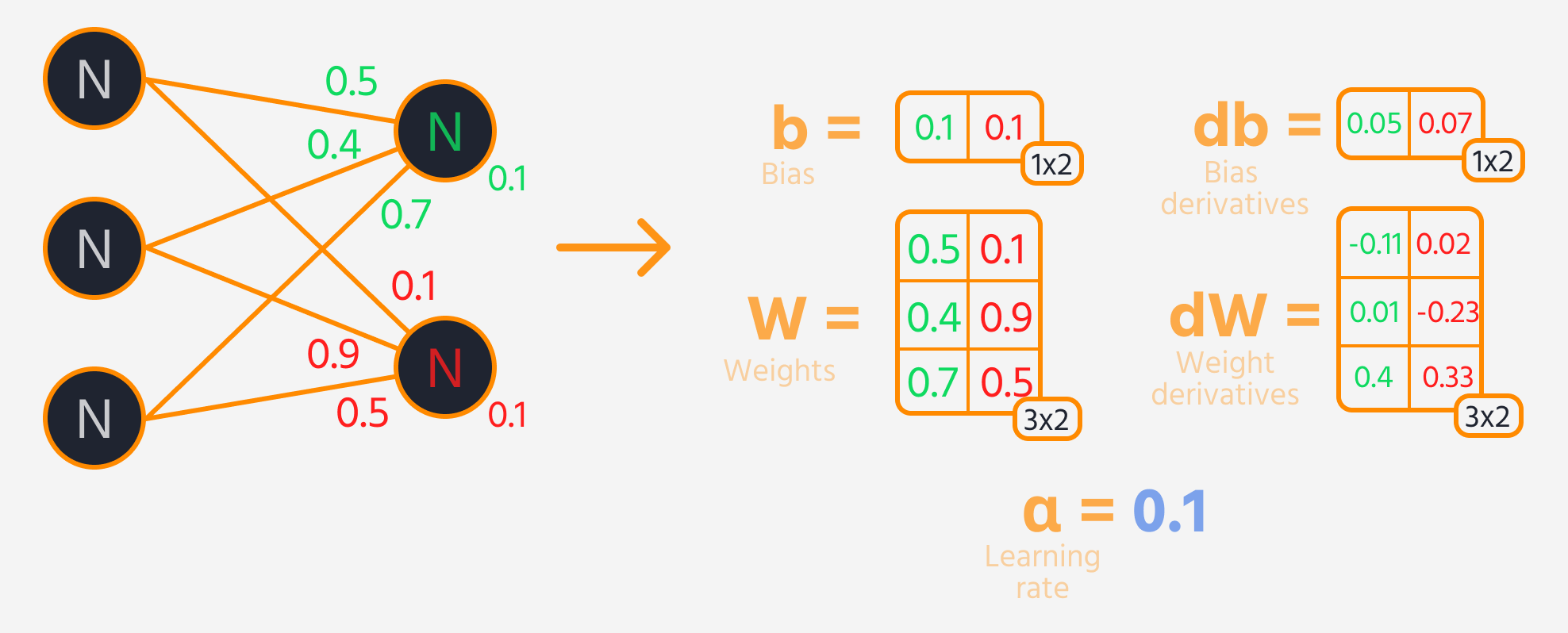
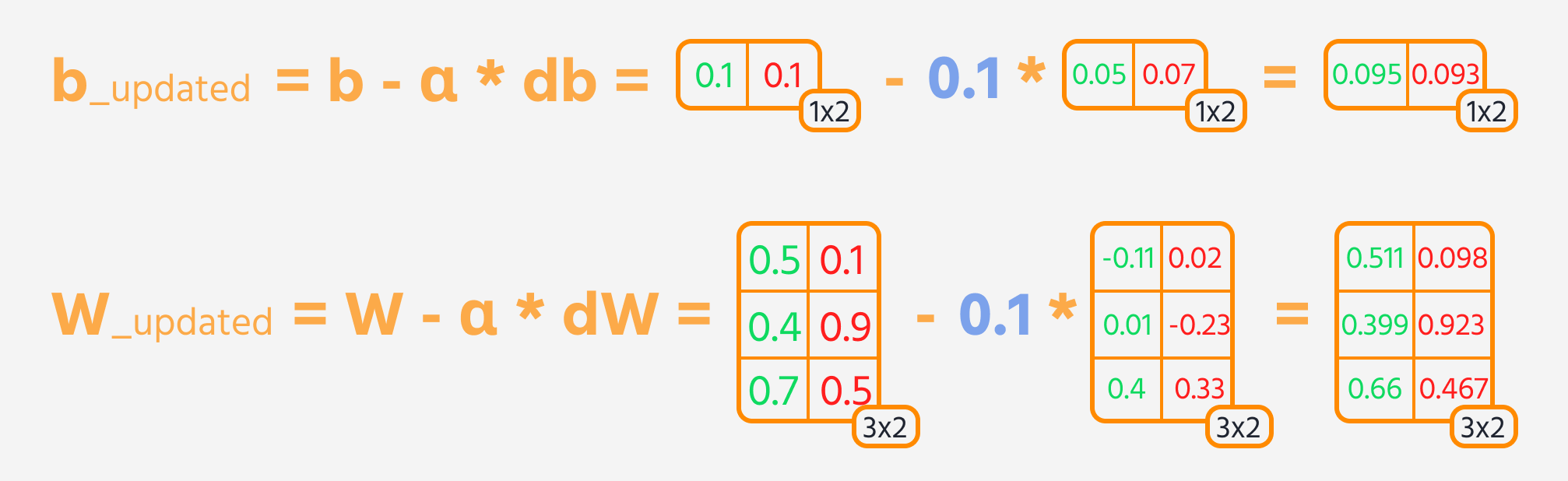
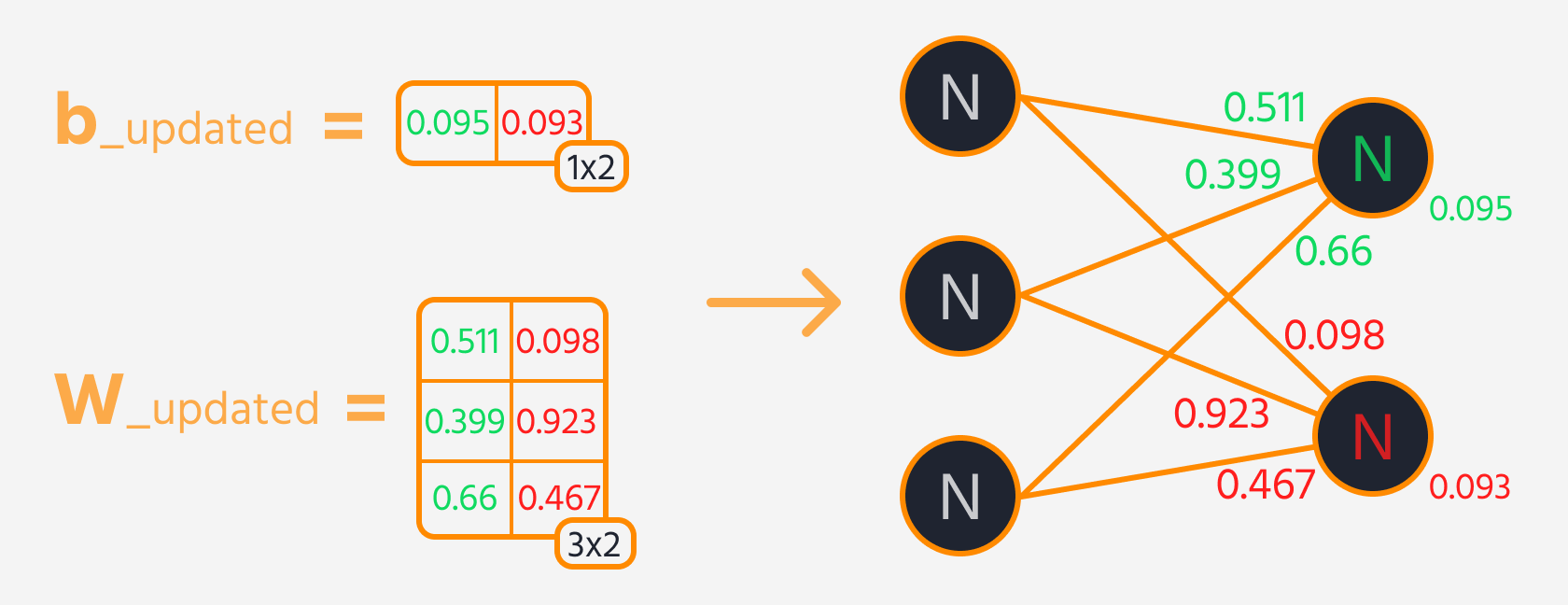
Træningssløjfe
For effektivt at træne det neurale netværk gentages træningstrinnene flere gange, mens modellens ydeevne overvåges. Ideelt set bør tabet falde over epokerne.
Swipe to start coding
Opret et neuralt netværk designet til at forudsige resultaterne af XOR-operationen. Netværket skal bestå af 2 inputneuroner, et skjult lag med 2 neuroner og 1 outputneuron.
- Begynd med at opsætte de indledende vægte og biaser. Vægtene skal initialiseres ved hjælp af en normalfordeling, og alle biaser skal initialiseres til nul. Brug hyperparametrene
input_size,hidden_sizeogoutput_sizetil at definere de korrekte dimensioner for disse tensorer. - Udnyt en funktionsdekoration til at omdanne funktionen
train_step()til en TensorFlow graf. - Udfør fremadpropagering gennem både det skjulte og outputlaget i netværket. Brug sigmoid aktiveringsfunktion.
- Bestem gradienterne for at forstå, hvordan hver vægt og bias påvirker tabet. Sørg for, at gradienterne beregnes i den korrekte rækkefølge, svarende til navnene på outputvariablerne.
- Opdater vægte og biaser baseret på deres respektive gradienter. Inkludér
learning_ratei denne justeringsproces for at styre størrelsen af hver opdatering.
Løsning
Dataklargøring
X_data: dette er inputdataene til XOR-funktionen. Det er et NumPy-array med formen (4, 2), som repræsenterer de fire mulige kombinationer af XOR-inputtene (0,0), (0,1), (1,0) og (1,1);Y_data: dette er måloutputtet for hver inputkombination iX_data. Det er også et NumPy-array, men med formen (4, 1), som repræsenterer XOR-outputtet for hvert inputpar.
Netværksparametre
input_size: størrelsen på inputlaget, sat til 2, svarende til de to inputnoder (for de to input til XOR-funktionen);hidden_size: størrelsen på det skjulte lag, også sat til 2. Dette valg er delvist vilkårligt, men er tilstrækkeligt til at lære XOR-funktionen;output_size: størrelsen på outputlaget, sat til 1, svarende til den enkelte outputnode (resultatet af XOR-operationen);learning_rate: dette er indlæringsraten for optimeringsalgoritmen, som styrer hvor meget vægtene justeres under træningen.
Vægte og bias
W1ogb1: vægtene (W1) og bias (b1) for forbindelserne fra inputlaget til det skjulte lag.W1er en TensorFlow-variabel initialiseret med tilfældige værdier og har formen(input_size, hidden_size), dvs.(2, 2).b1er en TensorFlow-variabel initialiseret med nuller og har formen(hidden_size), dvs.(2);W2ogb2: vægtene (W2) og bias (b2) for forbindelserne fra det skjulte lag til outputlaget.W2er initialiseret med tilfældige værdier og har formen(hidden_size, output_size), dvs.(2, 1).b2er initialiseret med nuller og har formen(output_size), dvs.(1).
Træningsfunktion
train_step(): dette er den centrale træningsfunktion. Den brugertf.GradientTape()til automatisk differentiering. I forward pass beregnes aktiveringerne i det skjulte lag (a1) og outputforudsigelserne (Y_pred). Tabet beregnes som Mean Squared Error mellemY_predogY. Funktionen beregner derefter gradienterne og opdaterer vægte og bias;tf.sigmoid(): en sigmoid aktiveringsfunktion anvendes, som transformerer input til en værdi mellem0og1. Denne bruges både til det skjulte lag og outputlaget.
Træningssløjfe
- Netværket trænes i
2500epoker. I hver epoke kaldes funktionentrain_step(), og vægtene opdateres. Tabet udskrives for hver500epoker for at overvåge træningsforløbet.
Konklusion
Da XOR-funktionen er en forholdsvis enkel opgave, er der ikke behov for avancerede teknikker som hyperparametertuning, datasætopdeling eller opbygning af komplekse datapipelines på dette trin. Denne øvelse er blot et skridt på vejen mod at bygge mere avancerede neurale netværk til virkelige anvendelser.
Beherskelse af disse grundlæggende elementer er afgørende, før man går videre til avancerede teknikker til konstruktion af neurale netværk i kommende kurser, hvor vi vil bruge Keras-biblioteket og udforske metoder til at forbedre modelkvaliteten med TensorFlows mange funktioner.
Tak for dine kommentarer!
single
Spørg AI
Spørg AI

Spørg om hvad som helst eller prøv et af de foreslåede spørgsmål for at starte vores chat
