Introduktion til konvolutionelle neurale netværk
Stryg for at vise menuen
Hvad er et CNN, og hvorfor adskiller det sig fra traditionelle neurale netværk?
Et convolutional neural network (CNN) er en type kunstig intelligens, der hjælper computere med at "se" og forstå billeder. I modsætning til almindelige neurale netværk, der behandler billeder som en liste af tal, analyserer CNN'er billeder i sektioner og genkender mønstre som kanter, former og teksturer. Dette gør dem langt bedre til at håndtere billeder og videoer.
Hvordan CNN'er er inspireret af det menneskelige øje
CNN'er fungerer på en måde, der ligner, hvordan den menneskelige hjerne behandler billeder. Når vi ser på noget, sender vores øjne information til hjernen, som først genkender simple former som kanter og farver. Derefter samler dybere lag i hjernen disse dele for at forstå objekter, ansigter eller hele scener. CNN'er følger samme princip, hvor de starter med simple træk og bygger op til at genkende komplekse objekter.
Ligesom vores øjne fokuserer på bestemte områder, behandler CNN'er også billeder i små sektioner, hvilket hjælper dem med at genkende mønstre uanset, hvor de optræder. Men i modsætning til mennesker har CNN'er brug for tusindvis af mærkede billeder for at lære, mens mennesker kan genkende objekter, selvom de kun har set dem få gange.
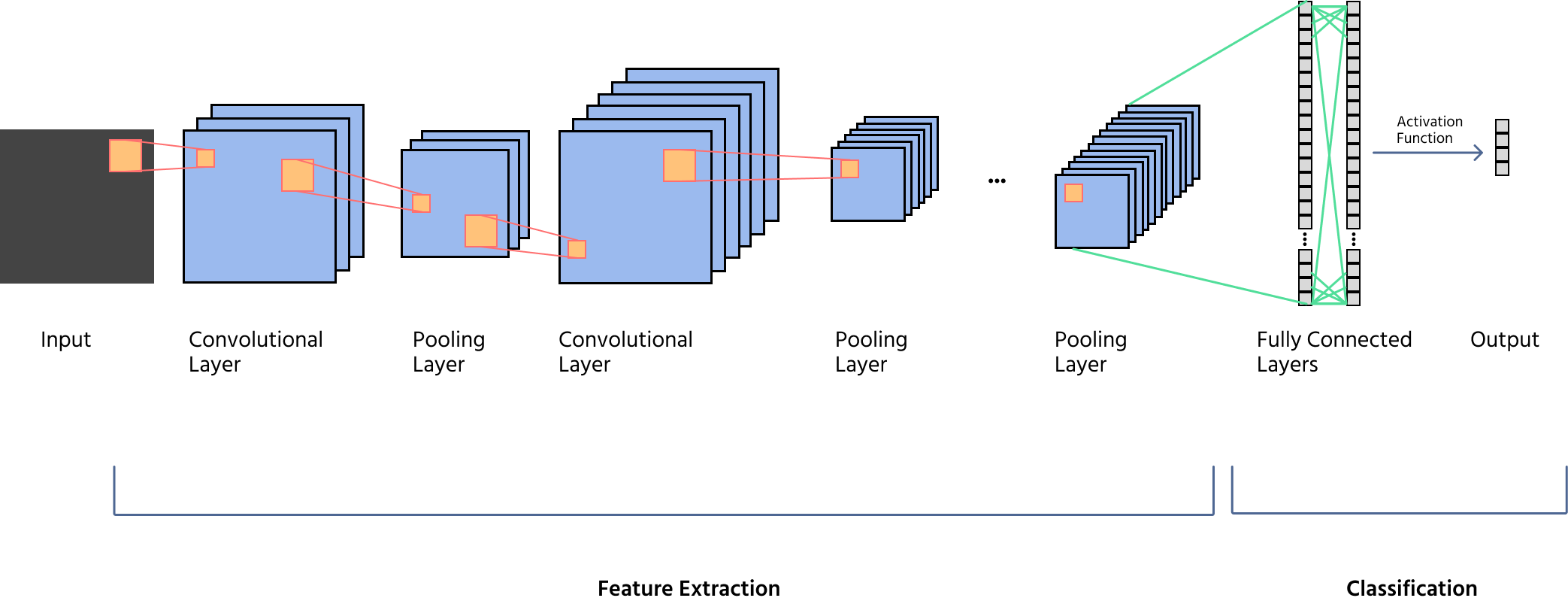
Oversigt over nøglekomponenter: Konvolution, pooling, aktivering og fuldt forbundne lag
Et CNN består af flere lag, hvor hvert lag har en særskilt rolle i behandlingen af billeder:
- Anvendelse af filtre (kerner) til at detektere mønstre såsom kanter, teksturer og former;
- Brug af stride og padding til at kontrollere dimensionsstørrelsen på feature maps;
- Generering af flere feature maps for dybdegående feature-ekstraktion.
- Introduktion af ikke-linearitet, hvilket gør det muligt for CNN'er at lære komplekse repræsentationer;
- Almindelige funktioner inkluderer ReLU (Rectified Linear Unit), Leaky ReLU og Sigmoid.
- Reduktion af de rumlige dimensioner af feature maps, mens vigtig information bevares;
- Typer inkluderer max pooling (fanger dominerende træk) og average pooling (udglatter repræsentationer);
- Bidrager til translationsinvarians og beregningseffektivitet.
- Udfladning af feature maps til en 1D-vektor til klassificering;
- Forbindelse til et endeligt outputlag ved brug af Softmax (til multi-klasse klassificering) eller Sigmoid (til binær klassificering).
CNN'er er kraftfulde, fordi de automatisk kan lære funktioner fra billeder i stedet for at kræve, at mennesker programmerer alle detaljer. Derfor bruges de i selvkørende biler, ansigtsgenkendelse, medicinsk billedbehandling og mange andre virkelige applikationer.
1. Hvad er den største fordel ved CNN'er i forhold til traditionelle neurale netværk ved billedbehandling?
2. Match elementet i CNN med dets funktion.
Tak for dine kommentarer!
Spørg AI
Spørg AI

Spørg om hvad som helst eller prøv et af de foreslåede spørgsmål for at starte vores chat
