Pooling-lag
Stryg for at vise menuen
Formål med pooling
Pooling-lag spiller en afgørende rolle i konvolutionelle neurale netværk (CNN'er) ved at reducere de rumlige dimensioner af feature-maps, samtidig med at væsentlig information bevares. Dette hjælper med:
- Dimensionalitetsreduktion: mindsker beregningskompleksitet og hukommelsesforbrug;
- Bevarelse af features: fastholder de mest relevante detaljer til de efterfølgende lag;
- Forebyggelse af overfitting: reducerer risikoen for at opfange støj og irrelevante detaljer;
- Translationsinvarians: gør netværket mere robust over for variationer i objektpositioner i et billede.
Typer af pooling
Pooling-lag fungerer ved at anvende et lille vindue på tværs af feature-maps og aggregere værdier på forskellige måder. De vigtigste typer af pooling omfatter:
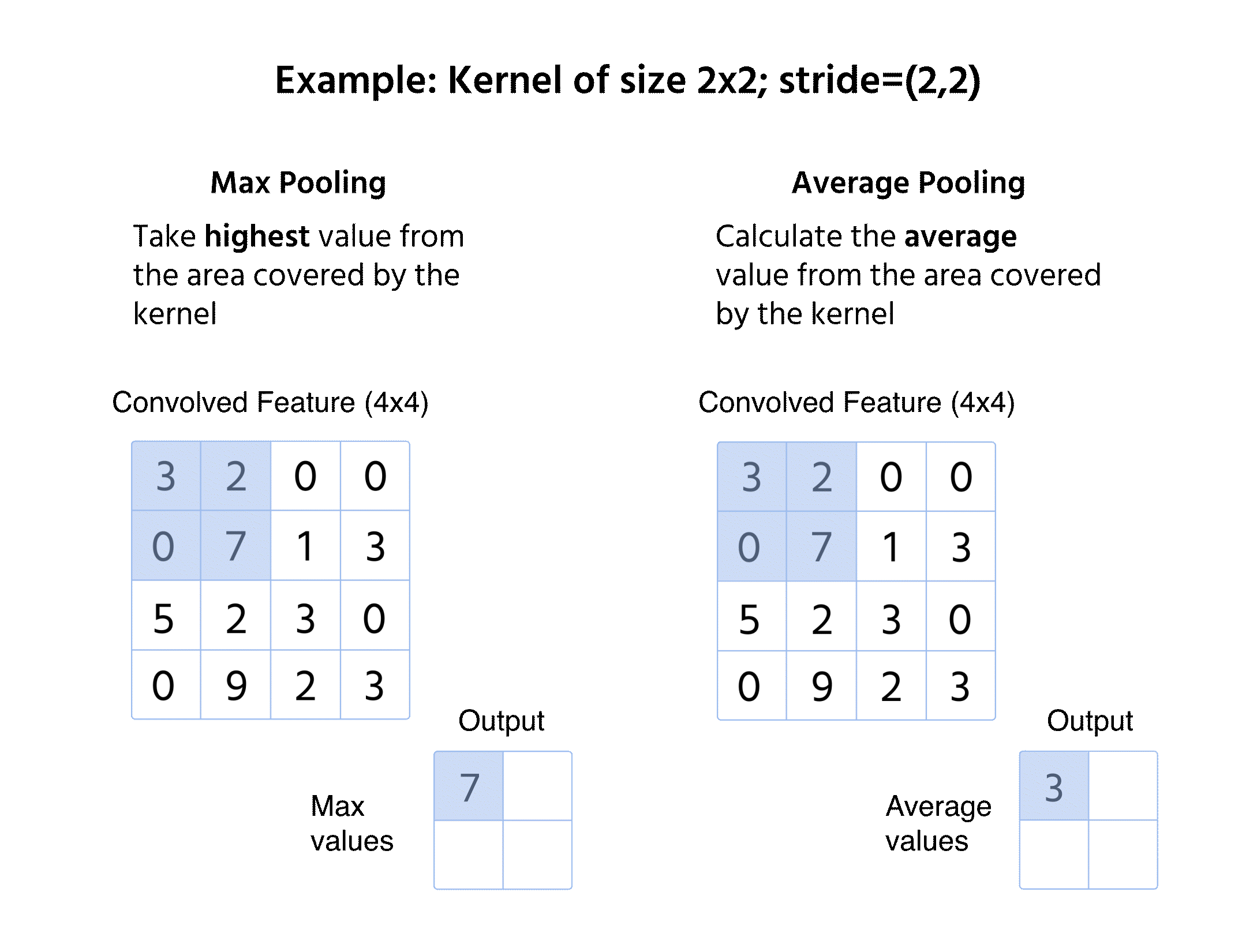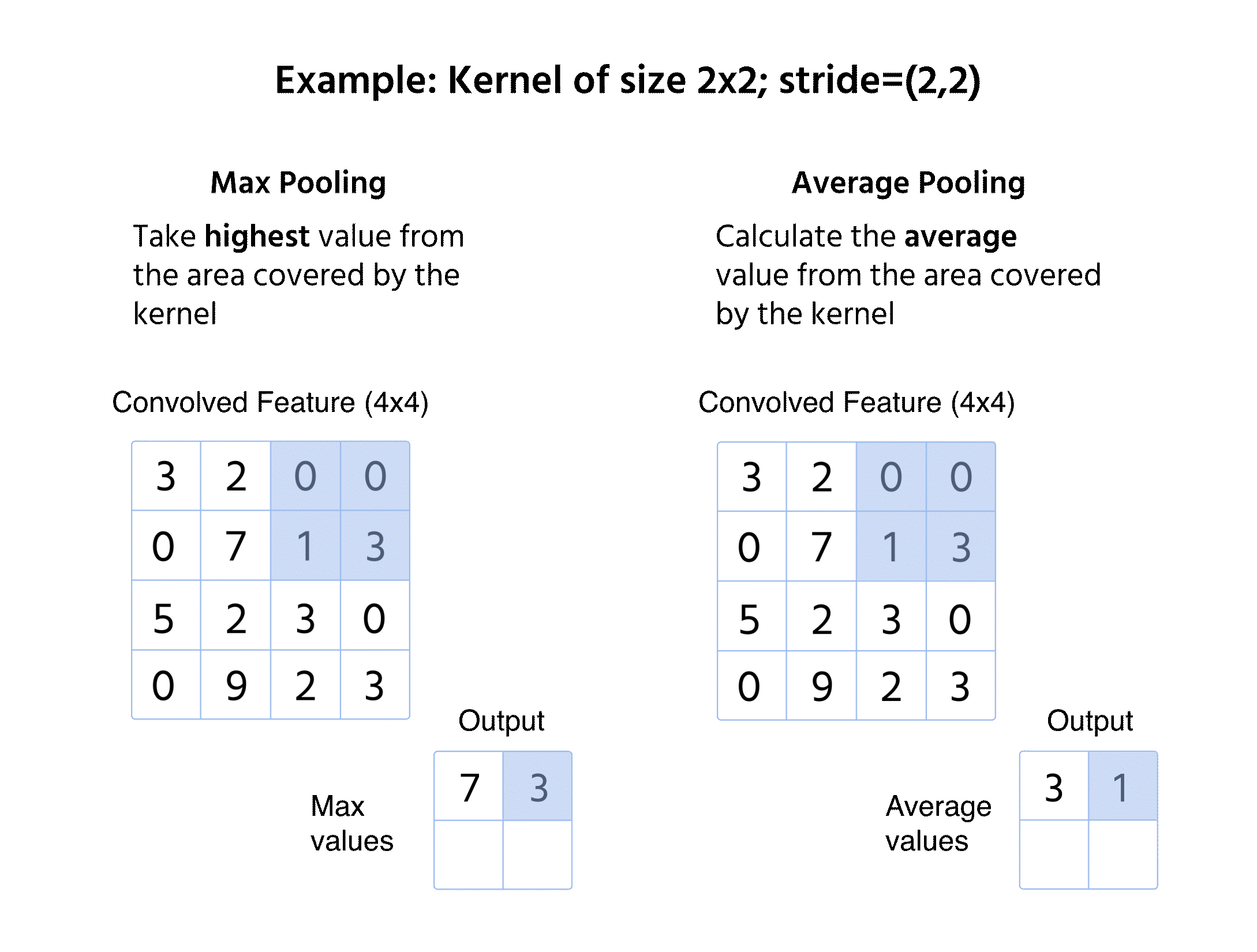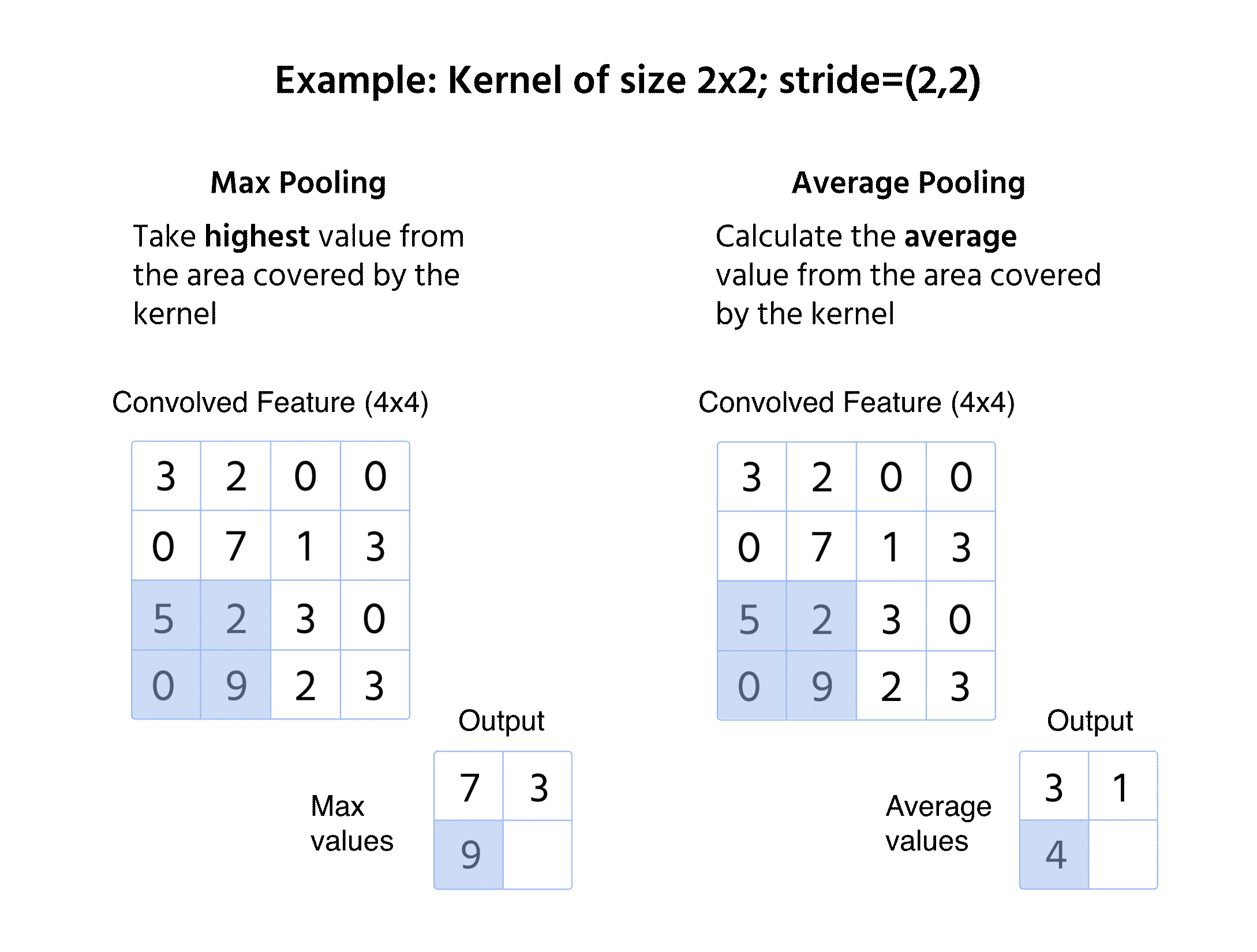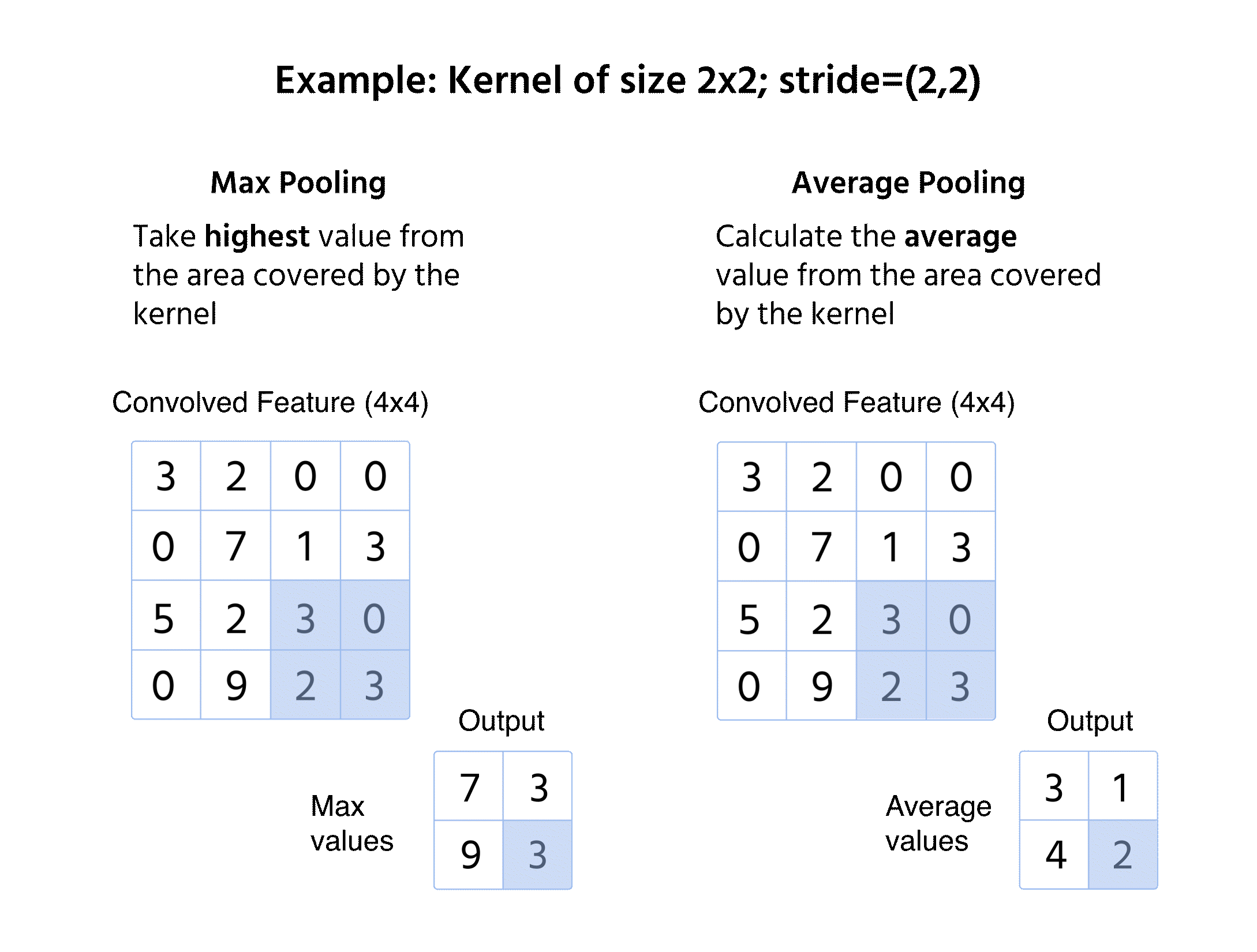
Max pooling
- Vælger den maksimale værdi fra vinduet;
- Bevarer dominerende features og fjerner mindre variationer;
- Anvendes ofte på grund af evnen til at fastholde skarpe og fremtrædende kanter.
Gennemsnitspooling
- Beregner den gennemsnitlige værdi inden for vinduet;
- Giver et mere jævnt feature-map ved at reducere ekstreme variationer;
- Mindre anvendt end max pooling, men fordelagtig i visse anvendelser som objektdetektion.
Global Pooling
- I stedet for at bruge et lille vindue, foretages pooling over hele feature-mappet;
- Der findes to typer global pooling:
- Global max pooling: Tager den maksimale værdi på tværs af hele feature-mappet;
- Global average pooling: Beregner gennemsnittet af alle værdier i feature-mappet.
- Ofte anvendt i fuldt konvolutionelle netværk til klassifikationsopgaver.
Ved pooling anvendes der ikke nogen kernel på inputdataen, men informationen forenkles blot med en matematisk operation (Max eller Gennemsnit).
Fordele ved pooling i CNN'er
Pooling forbedrer ydeevnen af CNN'er på flere måder:
- Translationsinvarians: små forskydninger i et billede ændrer ikke drastisk outputtet, da pooling fokuserer på de mest betydningsfulde træk;
- Reduktion af overfitting: forenkler feature maps og forhindrer overdreven memorering af træningsdata;
- Forbedret beregningseffektivitet: reduktion af størrelsen på feature maps øger behandlingshastigheden og mindsker hukommelseskravene.
Pooling-lag er en grundlæggende komponent i CNN-arkitekturer og sikrer, at netværkene udtrækker meningsfuld information, samtidig med at effektivitet og generaliseringsevne opretholdes.
1. Hvad er det primære formål med pooling-lag i en CNN?
2. Hvilken pooling-metode vælger den mest dominerende værdi i et givet område?
3. Hvordan hjælper pooling med at forhindre overfitting i CNN'er?
Tak for dine kommentarer!
Spørg AI
Spørg AI

Spørg om hvad som helst eller prøv et af de foreslåede spørgsmål for at starte vores chat
