Aktiveringsfunktioner
Stryg for at vise menuen
Hvorfor aktiveringsfunktioner er afgørende i CNN'er
Aktiveringsfunktioner introducerer ikke-linearitet i CNN'er, hvilket gør det muligt for dem at lære komplekse mønstre, som en simpel lineær model ikke kan opfange. Uden aktiveringsfunktioner ville CNN'er have svært ved at identificere indviklede sammenhænge i data, hvilket begrænser deres effektivitet i billedgenkendelse og klassificering. Valget af aktiveringsfunktion påvirker træningshastighed, stabilitet og den samlede ydeevne.
Almindelige aktiveringsfunktioner
- ReLU (rectified linear unit): den mest anvendte aktiveringsfunktion i CNN'er. Den tillader kun positive værdier og sætter alle negative input til nul, hvilket gør den beregningseffektiv og forhindrer forsvindende gradienter. Dog kan nogle neuroner blive inaktive på grund af "dying ReLU"-problemet;

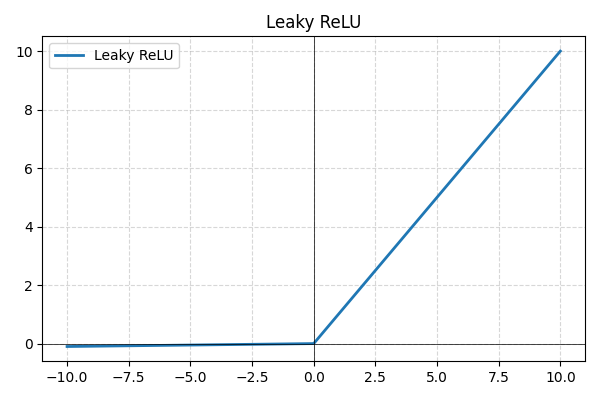
- Leaky ReLU: en variation af ReLU, der tillader små negative værdier i stedet for at sætte dem til nul, hvilket forhindrer inaktive neuroner og forbedrer gradientflow;
- Sigmoid: komprimerer inputværdier til et interval mellem 0 og 1, hvilket gør den nyttig til binær klassifikation. Dog lider den af forsvindende gradienter i dybe netværk;

- Tanh: ligner Sigmoid, men returnerer værdier mellem -1 og 1, hvilket centrerer aktiveringer omkring nul;

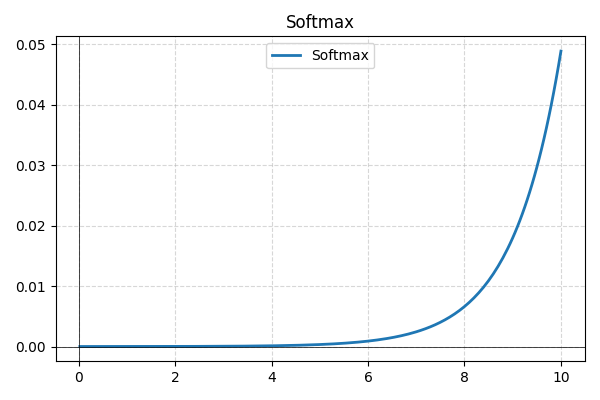
- Softmax: typisk anvendt i det sidste lag til multi-klasse klassifikation, konverterer Softmax netværkets rå output til sandsynligheder, hvilket sikrer, at de summerer til én for bedre fortolkning.
Valg af den rette aktiveringsfunktion
ReLU er standardvalget til skjulte lag på grund af dens effektivitet og stærke ydeevne, mens Leaky ReLU er et bedre valg, når inaktive neuroner bliver et problem. Sigmoid og Tanh undgås generelt i dybe CNN'er, men kan stadig være nyttige i specifikke anvendelser. Softmax forbliver essentiel til multi-klasse klassifikationsopgaver og sikrer tydelige, sandsynlighedsbaserede forudsigelser.
Valget af den rette aktiveringsfunktion er afgørende for at optimere CNN-ydeevnen, balancere effektivitet og forhindre problemer som forsvindende eller eksploderende gradienter. Hver funktion bidrager unikt til, hvordan et netværk behandler og lærer af visuelle data.
1. Hvorfor foretrækkes ReLU frem for Sigmoid i dybe CNN'er?
2. Hvilken aktiveringsfunktion anvendes ofte i det sidste lag af et multi-klasse klassifikations-CNN?
3. Hvad er den primære fordel ved Leaky ReLU i forhold til standard ReLU?
Tak for dine kommentarer!
Spørg AI
Spørg AI

Spørg om hvad som helst eller prøv et af de foreslåede spørgsmål for at starte vores chat
