Oversigt over Billedgenerering
Stryg for at vise menuen
AI-genererede billeder ændrer måden, hvorpå folk skaber kunst, design og digitalt indhold. Ved hjælp af kunstig intelligens kan computere nu fremstille realistiske billeder, forbedre kreativt arbejde og endda understøtte virksomheder. I dette kapitel undersøges, hvordan AI skaber billeder, forskellige typer billedgenereringsmodeller samt deres anvendelse i praksis.
Hvordan AI skaber billeder
AI-billedgenerering fungerer ved at lære fra en enorm samling af billeder. AI'en analyserer mønstre i billederne og skaber derefter nye, der ligner dem. Denne teknologi er blevet markant forbedret gennem årene og kan nu fremstille billeder, der er mere realistiske og kreative. Den anvendes i dag i videospil, film, reklamer og endda mode.
Tidlige metoder: PixelRNN og PixelCNN
Før nutidens avancerede AI-modeller udviklede forskere tidlige billedgenereringsmetoder som PixelRNN og PixelCNN. Disse modeller skabte billeder ved at forudsige én pixel ad gangen.
- PixelRNN: anvender et system kaldet et rekurrentt neuralt netværk (RNN) til at forudsige pixel-farver én efter én. Selvom det fungerede godt, var det meget langsomt;
- PixelCNN: forbedrede PixelRNN ved at bruge en anden type netværk, kaldet konvolutionslag, hvilket gjorde billedgenereringen hurtigere.
Selvom disse modeller var et godt udgangspunkt, var de ikke gode til at skabe billeder i høj kvalitet. Dette førte til udviklingen af bedre teknikker.
Autoregressive modeller
Autoregressive modeller skaber også billeder én pixel ad gangen ved at bruge tidligere pixels til at forudsige, hvad der kommer næste gang. Disse modeller var nyttige, men langsomme, hvilket gjorde dem mindre populære over tid. De har dog inspireret nyere og hurtigere modeller.
Hvordan AI forstår tekst til billedgenerering
Nogle AI-modeller kan omdanne skrevne ord til billeder. Disse modeller bruger Large Language Models (LLMs) til at forstå beskrivelser og generere tilsvarende billeder. For eksempel, hvis du skriver “a cat sitting on a beach at sunset,” vil AI'en skabe et billede baseret på den beskrivelse.
AI-modeller som OpenAI's DALL-E og Googles Imagen anvender avanceret sprogforståelse for at forbedre, hvor godt tekstbeskrivelser matcher de billeder, de genererer. Dette er muligt gennem Natural Language Processing (NLP), som hjælper AI med at omsætte ord til tal, der guider billedgenereringen.
Generative Adversarial Networks (GANs)
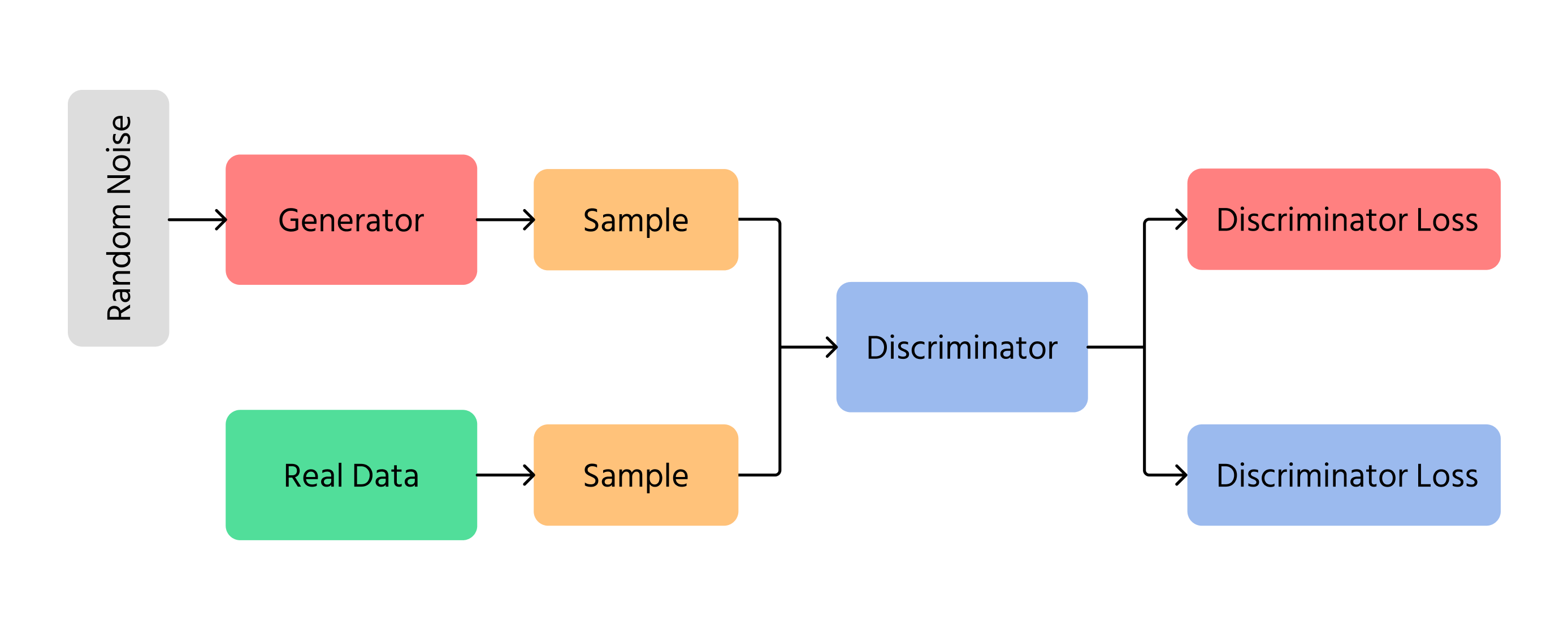
En af de vigtigste gennembrud inden for AI-billedgenerering var Generative Adversarial Networks (GANs). GANs fungerer ved at bruge to forskellige neurale netværk:
- Generator: skaber nye billeder fra bunden;
- Discriminator: vurderer, om billederne ser ægte eller falske ud.
Generatoren forsøger at lave billeder, der er så realistiske, at diskriminatoren ikke kan se, at de er falske. Over tid bliver billederne bedre og ligner mere rigtige fotografier. GANs bruges i deepfake-teknologi, kunstværksgenerering og forbedring af billedkvalitet.
Variationsautoencodere (VAE'er)
VAE'er er en anden metode, hvorpå AI kan generere billeder. I stedet for at bruge konkurrence som GAN'er, koder og afkoder VAE'er billeder ved hjælp af sandsynlighed. De fungerer ved at lære de underliggende mønstre i et billede og derefter rekonstruere det med små variationer. Det probabilistiske element i VAE'er sikrer, at hvert genereret billede er en smule forskelligt, hvilket tilføjer variation og kreativitet.
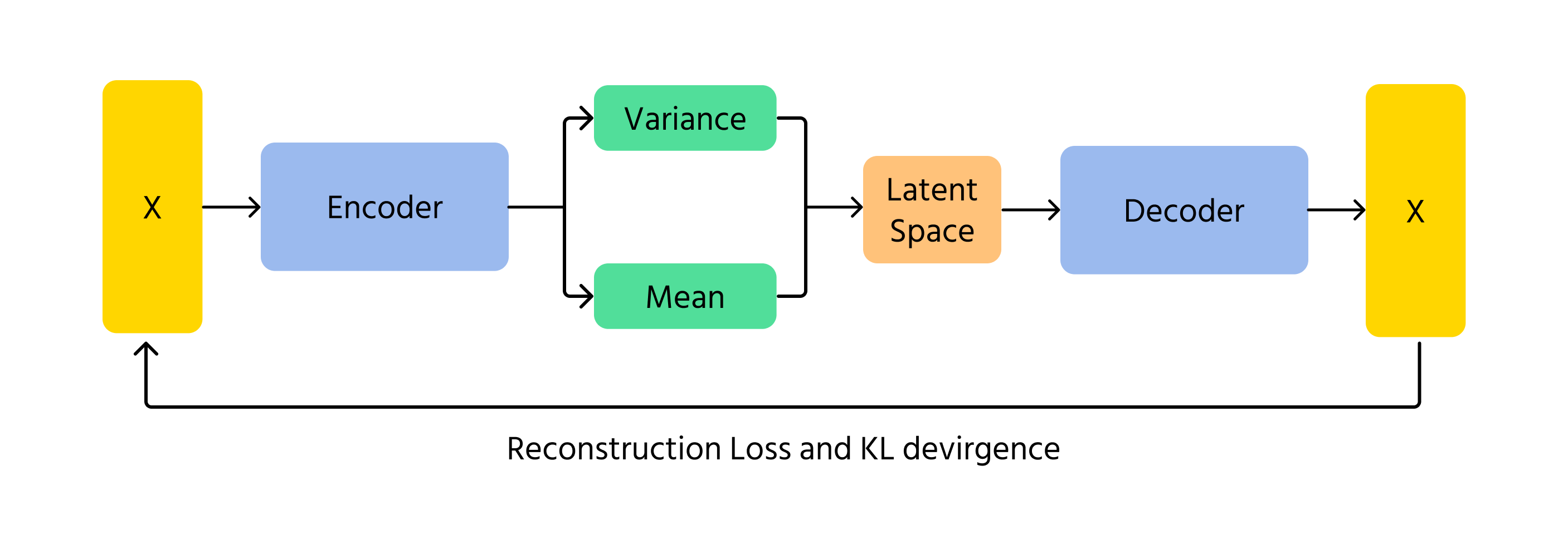
Et centralt begreb i VAE'er er Kullback-Leibler (KL) divergens, som måler forskellen mellem den lærte fordeling og en standard normalfordeling. Ved at minimere KL-divergens sikrer VAE'er, at genererede billeder forbliver realistiske, samtidig med at der tillades kreative variationer.
Sådan fungerer VAE'er
- Kodning: inputdata x føres ind i koderen, som udgiver parametrene for den latente rumsfordeling q(z∣x) (middelværdi μ og varians σ²);
- Sampling i latent rum: latente variable z samples fra fordelingen q(z∣x) ved hjælp af teknikker som reparameteriseringstricket;
- Dekodning & rekonstruktion: den samplede z sendes gennem dekoderen for at producere de rekonstruerede data x̂, som bør ligne det oprindelige input x.
VAE'er er nyttige til opgaver som rekonstruktion af ansigter, generering af nye versioner af eksisterende billeder og endda glidende overgange mellem forskellige billeder.
Diffusionsmodeller
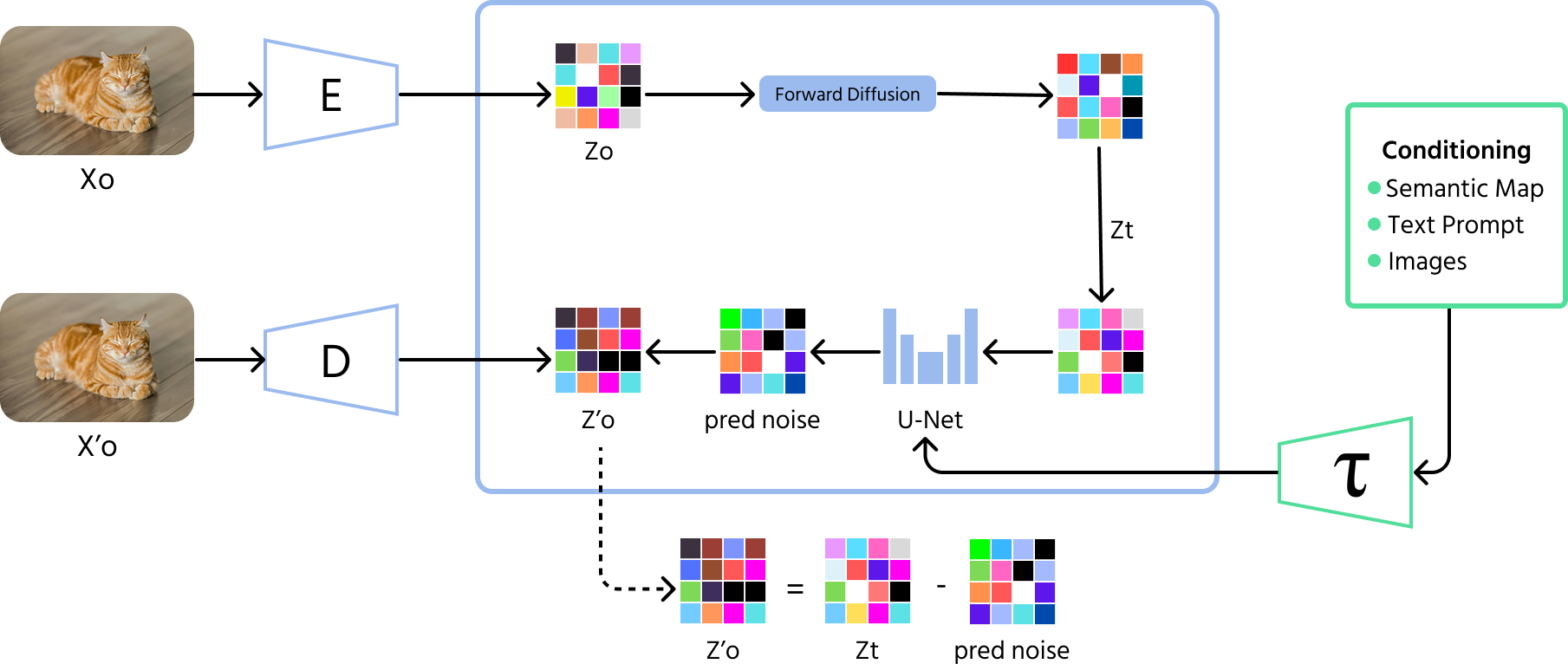
Diffusionsmodeller er det nyeste gennembrud inden for AI-genererede billeder. Disse modeller starter med tilfældig støj og forbedrer gradvist billedet trin for trin, ligesom at fjerne statisk støj fra et sløret foto. I modsætning til GAN'er, som nogle gange skaber begrænsede variationer, kan diffusionsmodeller producere et bredere udvalg af billeder i høj kvalitet.
Sådan fungerer diffusionsmodeller
- Fremadrettet proces (tilføjelse af støj): modellen starter med at tilføje tilfældig støj til et billede over mange trin, indtil det bliver fuldstændigt uigenkendeligt;
- Omvendt proces (fjernelse af støj): modellen lærer derefter at vende denne proces, hvor støjen gradvist fjernes trin for trin for at genskabe et meningsfuldt billede;
- Træning: diffusionsmodeller trænes til at forudsige og fjerne støj ved hvert trin, hvilket hjælper dem med at generere klare og højopløselige billeder ud fra tilfældig støj.
Et populært eksempel er MidJourney, DALL-E og Stable Diffusion, som er kendt for at skabe realistiske og kunstneriske billeder. Diffusionsmodeller anvendes bredt til AI-genereret kunst, højopløselig billedsyntese og kreative designapplikationer.
Eksempler på billeder genereret af diffusionsmodeller

Realistisk billede af en basketballspiller med skæg i en gul-lilla uniform, der laver et dunk og besejrer dæmoner i en basketballkamp; al handling foregår i helvede.

Et surrealistisk smukt kunstnerisk foto af en hvid 1990 Volkswagen Golf GTI i en endeløs mark af hvide blomster i harmoni med naturen midt i endeløse bakker fulde af blomster, botanisk, naturligt lys, kunstnerisk, tåget fotorealistisk surrealistisk ultra-detaljeret, kodak film, naturligt lys, vidvinkelobjektiv, f 1.20

Maleri af beige puddelhund liggende på grøn sofa med grøn- og hvidstribet pude i stil med Fairfield Porter, abstrakt ekspressionisme, med dristige penselstrøg på beige baggrund

Ekstremt nærbillede af en middelhavs- eller latinamerikansk kvindes hud, der fremhæver en kombineret hudtype med synlig olieagtighed på panden og næsen, mens kinderne fremstår tørrere og let skællende. Porerne er mere synlige i T-zonen, og der er en naturlig glans, der afspejler olieproduktionen. Huden har en blanding af varme og gyldne undertoner med en ujævn tekstur på grund af forskellige fugtniveauer. Blødt, naturligt lys understreger den realistiske kontrast mellem de tørre og olieagtige områder. Baggrunden er sløret, så opmærksomheden forbliver på hendes teint.
Udfordringer og etiske bekymringer
Selvom AI-genererede billeder er imponerende, medfører de udfordringer:
- Manglende kontrol: AI genererer ikke altid præcis det, brugeren ønsker;
- Computerkraft: oprettelse af AI-billeder i høj kvalitet kræver dyre og kraftfulde computere;
- Bias i AI-modeller: da AI lærer af eksisterende billeder, kan den nogle gange gentage forudindtagethed fra dataene.
Der er også etiske bekymringer:
- Hvem ejer AI-kunst?: hvis en AI skaber et kunstværk, tilhører det så den person, der brugte AI'en, eller AI-virksomheden?
- Falske billeder og deepfakes: GANs kan bruges til at skabe falske billeder, der ser ægte ud, hvilket kan føre til misinformation og problemer med privatliv.
Anvendelse af AI-billedgenerering i dag
AI-genererede billeder har allerede stor indflydelse i forskellige brancher:
- Underholdning: videospil, film og animation bruger AI til at skabe baggrunde, figurer og effekter;
- Mode: designere bruger AI til at skabe nye tøjstile, og onlinebutikker tilbyder virtuelle prøver til kunderne;
- Grafisk design: AI hjælper kunstnere og designere med hurtigt at lave logoer, plakater og markedsføringsmateriale.
Fremtiden for AI-billedgenerering
Efterhånden som AI-billedgenerering fortsætter med at udvikle sig, vil det fortsat ændre måden, hvorpå folk skaber og anvender billeder. Uanset om det er inden for kunst, erhvervsliv eller underholdning, åbner AI nye muligheder og gør kreativt arbejde lettere og mere spændende.
1. Hvad er hovedformålet med AI-billedgenerering?
2. Hvordan fungerer Generative Adversarial Networks (GANs)?
3. Hvilken AI-model starter med tilfældig støj og forbedrer billedet trin for trin?
Tak for dine kommentarer!
Spørg AI
Spørg AI

Spørg om hvad som helst eller prøv et af de foreslåede spørgsmål for at starte vores chat
Oversigt over Billedgenerering
AI-genererede billeder ændrer måden, hvorpå folk skaber kunst, design og digitalt indhold. Ved hjælp af kunstig intelligens kan computere nu fremstille realistiske billeder, forbedre kreativt arbejde og endda understøtte virksomheder. I dette kapitel undersøges, hvordan AI skaber billeder, forskellige typer billedgenereringsmodeller samt deres anvendelse i praksis.
Hvordan AI skaber billeder
AI-billedgenerering fungerer ved at lære fra en enorm samling af billeder. AI'en analyserer mønstre i billederne og skaber derefter nye, der ligner dem. Denne teknologi er blevet markant forbedret gennem årene og kan nu fremstille billeder, der er mere realistiske og kreative. Den anvendes i dag i videospil, film, reklamer og endda mode.
Tidlige metoder: PixelRNN og PixelCNN
Før nutidens avancerede AI-modeller udviklede forskere tidlige billedgenereringsmetoder som PixelRNN og PixelCNN. Disse modeller skabte billeder ved at forudsige én pixel ad gangen.
- PixelRNN: anvender et system kaldet et rekurrentt neuralt netværk (RNN) til at forudsige pixel-farver én efter én. Selvom det fungerede godt, var det meget langsomt;
- PixelCNN: forbedrede PixelRNN ved at bruge en anden type netværk, kaldet konvolutionslag, hvilket gjorde billedgenereringen hurtigere.
Selvom disse modeller var et godt udgangspunkt, var de ikke gode til at skabe billeder i høj kvalitet. Dette førte til udviklingen af bedre teknikker.
Autoregressive modeller
Autoregressive modeller skaber også billeder én pixel ad gangen ved at bruge tidligere pixels til at forudsige, hvad der kommer næste gang. Disse modeller var nyttige, men langsomme, hvilket gjorde dem mindre populære over tid. De har dog inspireret nyere og hurtigere modeller.
Hvordan AI forstår tekst til billedgenerering
Nogle AI-modeller kan omdanne skrevne ord til billeder. Disse modeller bruger Large Language Models (LLMs) til at forstå beskrivelser og generere tilsvarende billeder. For eksempel, hvis du skriver “a cat sitting on a beach at sunset,” vil AI'en skabe et billede baseret på den beskrivelse.
AI-modeller som OpenAI's DALL-E og Googles Imagen anvender avanceret sprogforståelse for at forbedre, hvor godt tekstbeskrivelser matcher de billeder, de genererer. Dette er muligt gennem Natural Language Processing (NLP), som hjælper AI med at omsætte ord til tal, der guider billedgenereringen.
Generative Adversarial Networks (GANs)
En af de vigtigste gennembrud inden for AI-billedgenerering var Generative Adversarial Networks (GANs). GANs fungerer ved at bruge to forskellige neurale netværk:
- Generator: skaber nye billeder fra bunden;
- Discriminator: vurderer, om billederne ser ægte eller falske ud.
Generatoren forsøger at lave billeder, der er så realistiske, at diskriminatoren ikke kan se, at de er falske. Over tid bliver billederne bedre og ligner mere rigtige fotografier. GANs bruges i deepfake-teknologi, kunstværksgenerering og forbedring af billedkvalitet.
Variationsautoencodere (VAE'er)
VAE'er er en anden metode, hvorpå AI kan generere billeder. I stedet for at bruge konkurrence som GAN'er, koder og afkoder VAE'er billeder ved hjælp af sandsynlighed. De fungerer ved at lære de underliggende mønstre i et billede og derefter rekonstruere det med små variationer. Det probabilistiske element i VAE'er sikrer, at hvert genereret billede er en smule forskelligt, hvilket tilføjer variation og kreativitet.
Et centralt begreb i VAE'er er Kullback-Leibler (KL) divergens, som måler forskellen mellem den lærte fordeling og en standard normalfordeling. Ved at minimere KL-divergens sikrer VAE'er, at genererede billeder forbliver realistiske, samtidig med at der tillades kreative variationer.
Sådan fungerer VAE'er
- Kodning: inputdata x føres ind i koderen, som udgiver parametrene for den latente rumsfordeling q(z∣x) (middelværdi μ og varians σ²);
- Sampling i latent rum: latente variable z samples fra fordelingen q(z∣x) ved hjælp af teknikker som reparameteriseringstricket;
- Dekodning & rekonstruktion: den samplede z sendes gennem dekoderen for at producere de rekonstruerede data x̂, som bør ligne det oprindelige input x.
VAE'er er nyttige til opgaver som rekonstruktion af ansigter, generering af nye versioner af eksisterende billeder og endda glidende overgange mellem forskellige billeder.
Diffusionsmodeller
Diffusionsmodeller er det nyeste gennembrud inden for AI-genererede billeder. Disse modeller starter med tilfældig støj og forbedrer gradvist billedet trin for trin, ligesom at fjerne statisk støj fra et sløret foto. I modsætning til GAN'er, som nogle gange skaber begrænsede variationer, kan diffusionsmodeller producere et bredere udvalg af billeder i høj kvalitet.
Sådan fungerer diffusionsmodeller
- Fremadrettet proces (tilføjelse af støj): modellen starter med at tilføje tilfældig støj til et billede over mange trin, indtil det bliver fuldstændigt uigenkendeligt;
- Omvendt proces (fjernelse af støj): modellen lærer derefter at vende denne proces, hvor støjen gradvist fjernes trin for trin for at genskabe et meningsfuldt billede;
- Træning: diffusionsmodeller trænes til at forudsige og fjerne støj ved hvert trin, hvilket hjælper dem med at generere klare og højopløselige billeder ud fra tilfældig støj.
Et populært eksempel er MidJourney, DALL-E og Stable Diffusion, som er kendt for at skabe realistiske og kunstneriske billeder. Diffusionsmodeller anvendes bredt til AI-genereret kunst, højopløselig billedsyntese og kreative designapplikationer.
Eksempler på billeder genereret af diffusionsmodeller
Realistisk billede af en basketballspiller med skæg i en gul-lilla uniform, der laver et dunk og besejrer dæmoner i en basketballkamp; al handling foregår i helvede.
Et surrealistisk smukt kunstnerisk foto af en hvid 1990 Volkswagen Golf GTI i en endeløs mark af hvide blomster i harmoni med naturen midt i endeløse bakker fulde af blomster, botanisk, naturligt lys, kunstnerisk, tåget fotorealistisk surrealistisk ultra-detaljeret, kodak film, naturligt lys, vidvinkelobjektiv, f 1.20
Maleri af beige puddelhund liggende på grøn sofa med grøn- og hvidstribet pude i stil med Fairfield Porter, abstrakt ekspressionisme, med dristige penselstrøg på beige baggrund
Ekstremt nærbillede af en middelhavs- eller latinamerikansk kvindes hud, der fremhæver en kombineret hudtype med synlig olieagtighed på panden og næsen, mens kinderne fremstår tørrere og let skællende. Porerne er mere synlige i T-zonen, og der er en naturlig glans, der afspejler olieproduktionen. Huden har en blanding af varme og gyldne undertoner med en ujævn tekstur på grund af forskellige fugtniveauer. Blødt, naturligt lys understreger den realistiske kontrast mellem de tørre og olieagtige områder. Baggrunden er sløret, så opmærksomheden forbliver på hendes teint.
Udfordringer og etiske bekymringer
Selvom AI-genererede billeder er imponerende, medfører de udfordringer:
- Manglende kontrol: AI genererer ikke altid præcis det, brugeren ønsker;
- Computerkraft: oprettelse af AI-billeder i høj kvalitet kræver dyre og kraftfulde computere;
- Bias i AI-modeller: da AI lærer af eksisterende billeder, kan den nogle gange gentage forudindtagethed fra dataene.
Der er også etiske bekymringer:
- Hvem ejer AI-kunst?: hvis en AI skaber et kunstværk, tilhører det så den person, der brugte AI'en, eller AI-virksomheden?
- Falske billeder og deepfakes: GANs kan bruges til at skabe falske billeder, der ser ægte ud, hvilket kan føre til misinformation og problemer med privatliv.
Anvendelse af AI-billedgenerering i dag
AI-genererede billeder har allerede stor indflydelse i forskellige brancher:
- Underholdning: videospil, film og animation bruger AI til at skabe baggrunde, figurer og effekter;
- Mode: designere bruger AI til at skabe nye tøjstile, og onlinebutikker tilbyder virtuelle prøver til kunderne;
- Grafisk design: AI hjælper kunstnere og designere med hurtigt at lave logoer, plakater og markedsføringsmateriale.
Fremtiden for AI-billedgenerering
Efterhånden som AI-billedgenerering fortsætter med at udvikle sig, vil det fortsat ændre måden, hvorpå folk skaber og anvender billeder. Uanset om det er inden for kunst, erhvervsliv eller underholdning, åbner AI nye muligheder og gør kreativt arbejde lettere og mere spændende.
Tak for dine kommentarer!
