Ankerbokse
Stryg for at vise menuen
Anchor box er en foruddefineret afgrænsningsboks med en fast størrelse og et fast størrelsesforhold, placeret på specifikke positioner i et billede.
Hvorfor Anchor Boxes bruges i objektdetektion
Anchor boxes er et grundlæggende koncept i moderne objektdetektionsmodeller såsom Faster R-CNN og YOLO. De fungerer som foruddefinerede referencebokse, der hjælper med at detektere objekter af forskellige størrelser og størrelsesforhold, hvilket gør detektionen hurtigere og mere pålidelig.
I stedet for at detektere objekter fra bunden bruger modeller anchor boxes som udgangspunkt og justerer dem for bedre at tilpasse sig de detekterede objekter. Denne tilgang forbedrer effektivitet og nøjagtighed, især ved detektion af objekter i varierende skalaer.
Forskel mellem Anchor Box og Bounding Box
- Anchor Box: en foruddefineret skabelon, der fungerer som reference under objektdetektion;
- Bounding Box: den endelige forudsagte boks efter justeringer af en anchor box for at matche det faktiske objekt.

I modsætning til afgrænsningsbokse, som justeres dynamisk under forudsigelse, er ankerbokse fastlagt på specifikke positioner, før nogen objektdetektion finder sted. Modeller lærer at forfine ankerbokse ved at justere deres størrelse, position og størrelsesforhold, hvilket til sidst omdanner dem til endelige afgrænsningsbokse, der nøjagtigt repræsenterer detekterede objekter.
Hvordan et netværk genererer ankerbokse
Ankerbokse anvendes ikke direkte på et billede, men derimod på feature maps, der er udtrukket fra billedet. Efter feature extraction placeres et sæt ankerbokse på disse feature maps, varierende i størrelse og størrelsesforhold. Valget af ankerboksformer er afgørende og indebærer en balance mellem detektion af små og store objekter.
For at definere ankerboksstørrelser anvender modeller typisk en kombination af manuel udvælgelse og klyngealgoritmer som K-Means til at analysere datasættet og bestemme de mest almindelige objektformer og -størrelser. Disse foruddefinerede ankerbokse anvendes derefter på forskellige placeringer på feature maps. For eksempel kan en objektdetektionsmodel anvende ankerbokse i størrelserne (16x16), (32x32), (64x64), med størrelsesforhold som 1:1, 1:2, and 2:1.
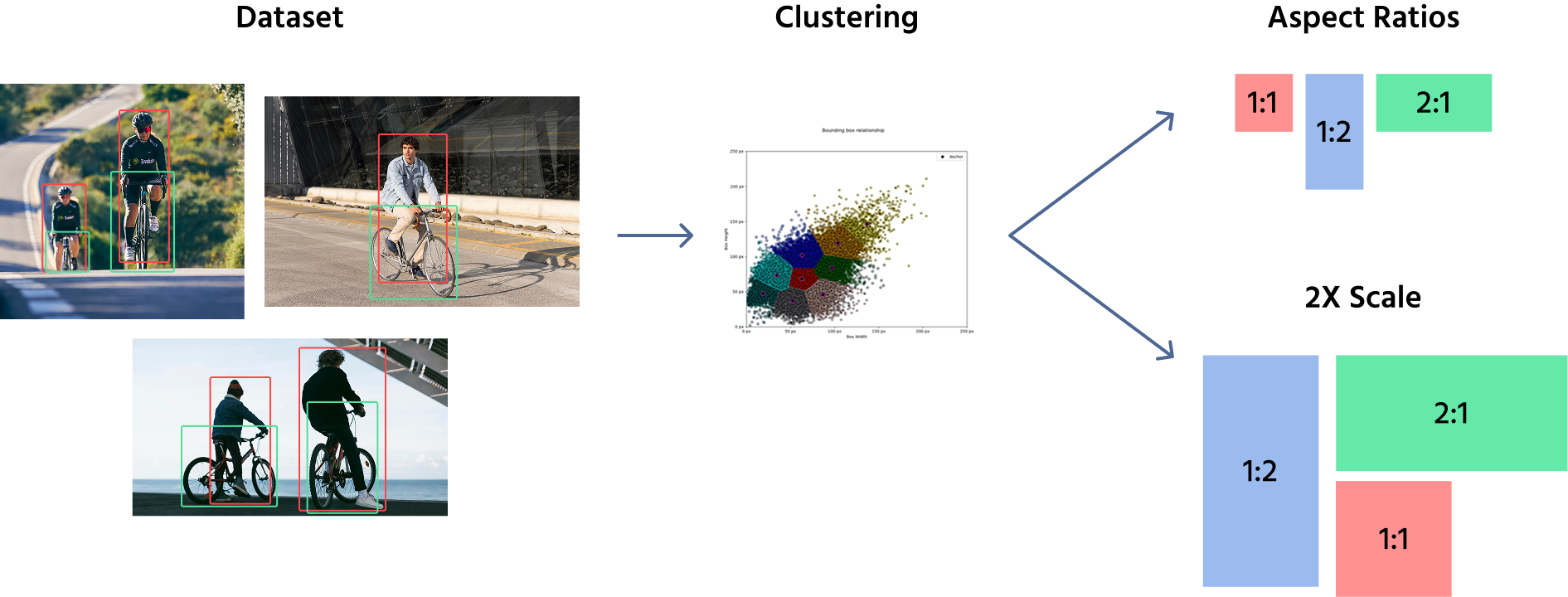
Når disse anchor boxes er defineret, anvendes de på feature maps, ikke det originale billede. Modellen tildeler flere anchor boxes til hver position i feature mappet, hvilket dækker forskellige former og størrelser. Under træning justerer netværket anchor boxes ved at forudsige forskydninger, hvilket forfiner deres størrelse og position for bedre at tilpasse sig objekterne.
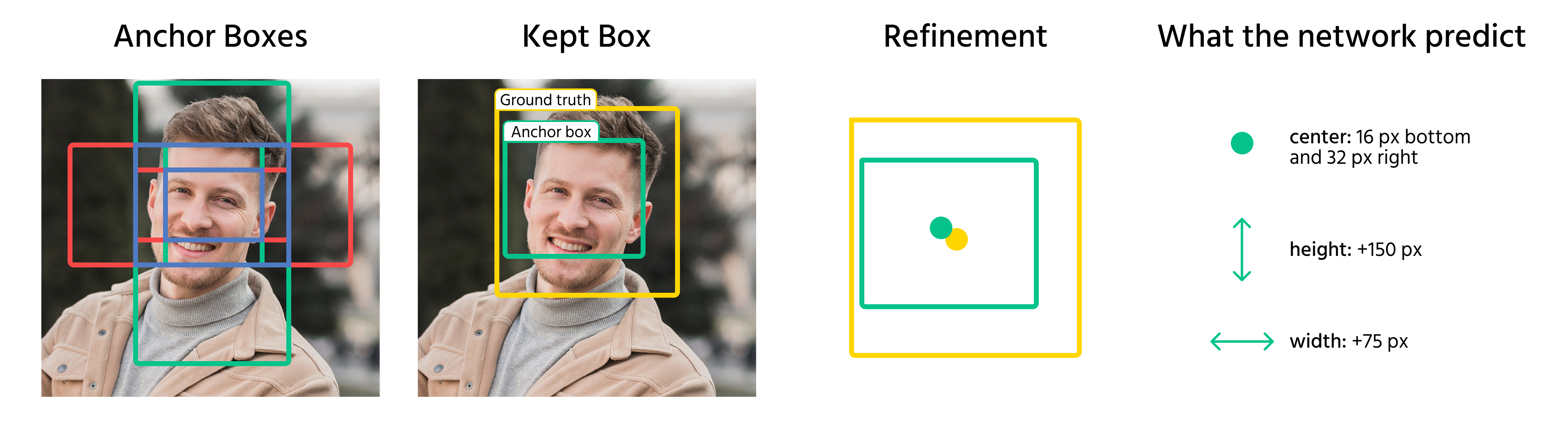
Fra Anchor Box til Bounding Box
Når anchor boxes er tildelt objekter, forudsiger modellen forskydninger for at forfine dem. Disse forskydninger omfatter:
- Justering af boksens centerkoordinater;
- Skalering af bredde og højde;
- Forskydning af boksen for bedre at tilpasse sig objektet.
Ved at anvende disse transformationer konverterer modellen anchor boxes til endelige bounding boxes, der nøje matcher objekterne i et billede.
Tilgange uden ankre eller med reduceret antal ankre
Selvom anchor boxes er udbredte, forsøger nogle modeller at mindske afhængigheden af dem eller helt fjerne dem:
- Anchor-fri metoder: Modeller som
CenterNetogFCOSforudsiger objektplaceringer direkte uden foruddefinerede ankre, hvilket reducerer kompleksiteten; - Reducerede ankre:
EfficientDetogYOLOv4optimerer antallet af anvendte anchor boxes og balancerer detektionshastighed og nøjagtighed.
Disse tilgange har til formål at forbedre effektiviteten af objektdetektion og samtidig opretholde høj ydeevne, især til realtidsapplikationer.
Sammenfattende er anchor boxes en central del af objektdetektion, da de hjælper modeller med effektivt at detektere objekter på tværs af forskellige størrelser og størrelsesforhold. Nye fremskridt undersøger dog måder at reducere eller eliminere anchor boxes for endnu hurtigere og mere fleksibel detektion.
1. Hvad er den primære rolle for anchor boxes i objektgenkendelse?
2. Hvordan adskiller anchor boxes sig fra bounding boxes?
3. Hvilken metode bruges ofte til at bestemme optimale størrelser for anchor boxes?
Tak for dine kommentarer!
Spørg AI
Spørg AI

Spørg om hvad som helst eller prøv et af de foreslåede spørgsmål for at starte vores chat
