Oversigt Over YOLO-Modellen
Stryg for at vise menuen
YOLO (You Only Look Once) algoritmen er en hurtig og effektiv model til objektdetektion. I modsætning til traditionelle metoder som R-CNN, der anvender flere trin, behandler YOLO hele billedet i én enkelt gennemgang, hvilket gør den ideel til realtidsapplikationer.
Hvordan YOLO adskiller sig fra R-CNN-metoder
Traditionelle objektdetektionsmetoder, såsom R-CNN og dens varianter, benytter en to-trins pipeline: først genereres region proposals, derefter klassificeres hver foreslået region. Selvom denne tilgang er effektiv, er den beregningsmæssigt krævende og forlænger inferenstiden, hvilket gør den mindre egnet til realtidsapplikationer.
YOLO (You Only Look Once) anvender en radikalt anderledes tilgang. Den opdeler inputbilledet i et gitter og forudsiger bounding boxes og klasse-sandsynligheder for hver celle i én enkelt fremadrettet gennemgang. Denne udformning behandler objektdetektion som et enkelt regressionsproblem, hvilket gør det muligt for YOLO at opnå realtidsydelse.
I modsætning til R-CNN-baserede metoder, der kun fokuserer på lokale områder, behandler YOLO hele billedet på én gang, hvilket gør det muligt at indfange global kontekstuel information. Dette fører til bedre præstation ved detektion af flere eller overlappende objekter, samtidig med at høj hastighed og nøjagtighed opretholdes.
YOLO-arkitektur og gitterbaserede forudsigelser
YOLO opdeler et inputbillede i et S × S gitter, hvor hver gittercelle er ansvarlig for at detektere objekter, hvis centrum falder inden for cellen. Hver celle forudsiger koordinater for bounding box (x, y, bredde, højde), en objekttillids-score og klasse-sandsynligheder. Da YOLO behandler hele billedet i én fremadrettet gennemgang, er den meget effektiv sammenlignet med tidligere objektdetektionsmodeller.
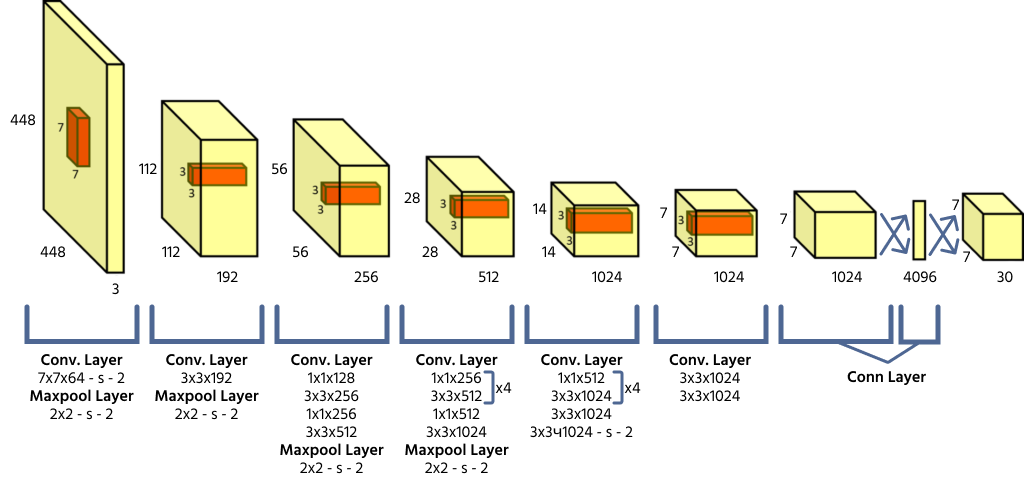
Tabsfunktion og klassens tillidsscore
YOLO optimerer detektionsnøjagtighed ved hjælp af en specialtilpasset tabsfunktion, som omfatter:
- Lokaliseringstab: måler nøjagtigheden af afgrænsningsbokse;
- Tillidstab: sikrer, at forudsigelser korrekt angiver tilstedeværelsen af objekter;
- Klassifikationstab: vurderer, hvor godt den forudsagte klasse matcher den sande klasse.
For at forbedre resultaterne anvender YOLO ankerbokse og non-max suppression (NMS) for at fjerne overflødige detektioner.
Fordele ved YOLO: Afvejning mellem hastighed og nøjagtighed
YOLO's primære fordel er hastighed. Da detektion sker i ét gennemløb, er YOLO langt hurtigere end R-CNN-baserede metoder, hvilket gør det velegnet til realtidsapplikationer som autonom kørsel og overvågning. Tidlige versioner af YOLO havde dog udfordringer med detektion af små objekter, hvilket senere versioner har forbedret.
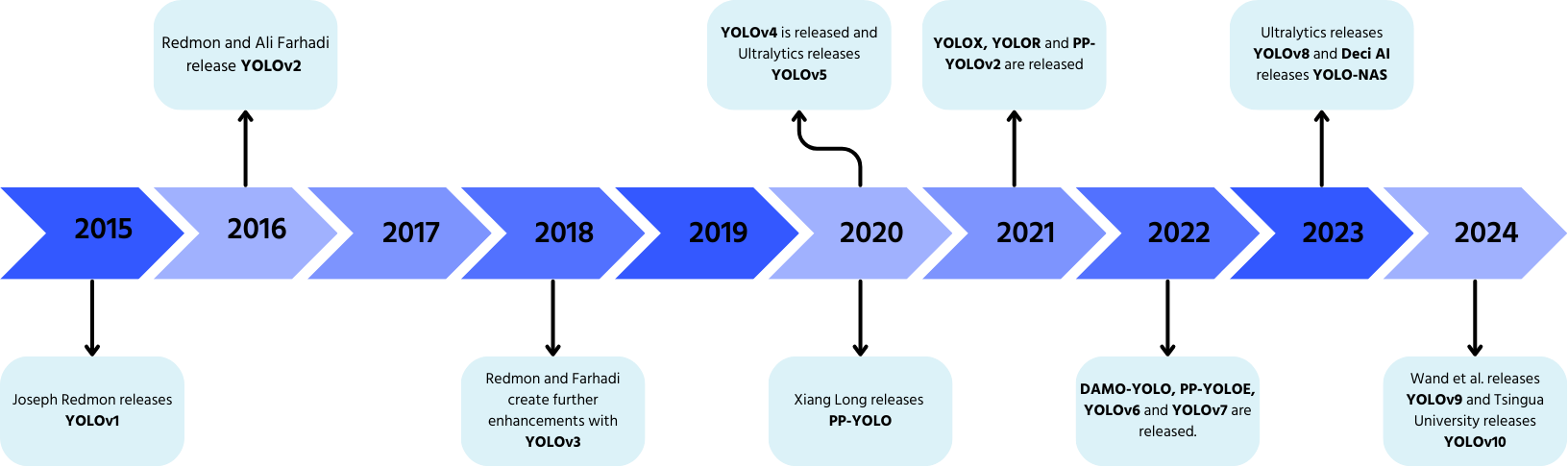
YOLO: En Kort Historie
YOLO, udviklet af Joseph Redmon og Ali Farhadi i 2015, revolutionerede objektdetektion med sin enkelt-pass behandling.
- YOLOv2 (2016): tilføjede batch-normalisering, ankerbokse og dimensionsklynger;
- YOLOv3 (2018): introducerede en mere effektiv backbone, flere ankre og spatial pyramid pooling;
- YOLOv4 (2020): tilføjede Mosaic dataforøgelse, et ankerfrit detektionshoved og en ny tab-funktion;
- YOLOv5: forbedret ydeevne med hyperparameteroptimering, eksperimentsporing og automatiske eksportfunktioner;
- YOLOv6 (2022): open-sourcet af Meituan og anvendt i autonome leveringsrobotter;
- YOLOv7: udvidede funktionalitet til også at omfatte poseestimering;
- YOLOv8 (2023): forbedret hastighed, fleksibilitet og effektivitet til vision AI-opgaver;
- YOLOv9: introducerede Programmable Gradient Information (PGI) og Generalized Efficient Layer Aggregation Network (GELAN);
- YOLOv10: udviklet af Tsinghua University, eliminerer Non-Maximum Suppression (NMS) med et End-to-End detektionshoved;
- YOLOv11: den nyeste model med banebrydende ydeevne inden for objektdetektion, segmentering og klassificering.
Tak for dine kommentarer!
Spørg AI
Spørg AI

Spørg om hvad som helst eller prøv et af de foreslåede spørgsmål for at starte vores chat
