Forudsigelser af Afgrænsningsbokse
Stryg for at vise menuen
Afgrænsningsbokse er afgørende for objektdetektion og giver en metode til at markere objekters placeringer. Objektdetektionsmodeller anvender disse bokse til at definere position og dimensioner af detekterede objekter i et billede. Præcis forudsigelse af afgrænsningsbokse er grundlæggende for at sikre pålidelig objektdetektion.
Hvordan CNN'er forudsiger koordinater for afgrænsningsbokse
Convolutional Neural Networks (CNN'er) behandler billeder gennem lag af konvolutioner og pooling for at udtrække træk. Til objektdetektion genererer CNN'er feature maps, der repræsenterer forskellige dele af et billede. Forudsigelse af afgrænsningsbokse opnås typisk ved:
- Udtrækning af trækrepræsentationer fra billedet;
- Anvendelse af en regressionsfunktion til at forudsige koordinater for afgrænsningsbokse;
- Klassificering af de detekterede objekter inden for hver boks.
Forudsigelser af afgrænsningsbokse repræsenteres som numeriske værdier svarende til:
- (x, y): koordinaterne for midten af boksen;
- (w, h): bredden og højden af boksen.
Eksempel: Forudsigelse af afgrænsningsbokse ved brug af en prætrænet model
I stedet for at træne en CNN fra bunden kan man anvende en prætrænet model såsom Faster R-CNN fra TensorFlows model zoo til at forudsige afgrænsningsbokse på et billede. Nedenfor ses et eksempel på indlæsning af en prætrænet model, indlæsning af et billede, udførelse af forudsigelser og visualisering af afgrænsningsbokse med klasselabels.
Importér biblioteker
import cv2
import tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
from tensorflow.image import draw_bounding_boxes
Indlæs model og billede
# Load a pretrained Faster R-CNN model from TensorFlow Hub
model = hub.load("https://www.kaggle.com/models/tensorflow/faster-rcnn-resnet-v1/TensorFlow2/faster-rcnn-resnet101-v1-1024x1024/1")
# Load and preprocess the image
img_path = "../../../Documents/Codefinity/CV/Pictures/Section 4/object_detection/bikes_n_persons.png"
img = cv2.imread(img_path)
Forbehandl billedet
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_resized = tf.image.resize(img, (1024, 1024))
# Convert to uint8
img_resized = tf.cast(img_resized, dtype=tf.uint8)
# Convert to tensor
img_tensor = tf.convert_to_tensor(img_resized)[tf.newaxis, ...]
Lav forudsigelse og udtræk bounding box-egenskaber
# Make predictions
output = model(img_tensor)
# Extract bounding box coordinates
num_detections = int(output['num_detections'][0])
bboxes = output['detection_boxes'][0][:num_detections].numpy()
class_names = output['detection_classes'][0][:num_detections].numpy().astype(int)
scores = output['detection_scores'][0][:num_detections].numpy()
# Example labels from COCO dataset
labels = {1: "Person", 2: "Bike"}
Tegn bounding boxes
# Draw bounding boxes with labels
for i in range(num_detections):
# Confidence threshold
if scores[i] > 0.5:
y1, x1, y2, x2 = bboxes[i]
start_point = (int(x1 * img.shape[1]), int(y1 * img.shape[0]))
end_point = (int(x2 * img.shape[1]), int(y2 * img.shape[0]))
cv2.rectangle(img, start_point, end_point, (0, 255, 0), 2)
# Get label or 'Unknown'
label = labels.get(class_names[i], "Unknown")
cv2.putText(img, f"{label} ({scores[i]:.2f})", (start_point[0], start_point[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
Visualisering
# Display image with bounding boxes and labels
plt.figure()
plt.imshow(img)
plt.axis("off")
plt.title("Object Detection with Bounding Boxes and Labels")
plt.show()
Resultat:

Regressionsbaserede forudsigelser af afgrænsningsbokse
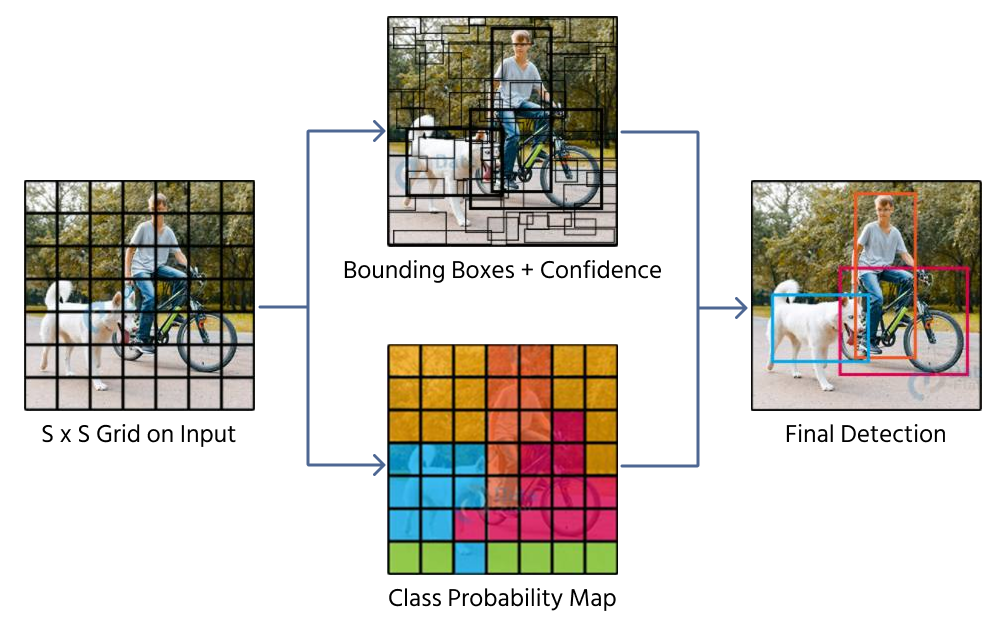
En metode til at forudsige afgrænsningsbokse er direkte regression, hvor et CNN returnerer fire numeriske værdier, der repræsenterer boksens position og størrelse. Modeller som YOLO (You Only Look Once) anvender denne teknik ved at opdele et billede i et gitter og tildele forudsigelser af afgrænsningsbokse til gitterceller.
Dog har direkte regression visse begrænsninger:
- Den har vanskeligt ved objekter med varierende størrelser og størrelsesforhold;
- Den håndterer ikke overlappende objekter effektivt;
- Afgrænsningsbokse kan flytte sig uforudsigeligt, hvilket fører til inkonsistens.
Ankerbaserede vs. ankerfrie tilgange
Ankerbaserede metoder
Ankerbokse er foruddefinerede afgrænsningsbokse med faste størrelser og størrelsesforhold. Modeller som Faster R-CNN og SSD (Single Shot MultiBox Detector) anvender ankerbokse for at forbedre prædiktionsnøjagtigheden. Modellen forudsiger justeringer til ankerboksene i stedet for at forudsige afgrænsningsbokse fra bunden. Denne metode fungerer godt til at detektere objekter i forskellige skalaer, men øger den beregningsmæssige kompleksitet.
Ankerfrie metoder
Ankerfrie metoder, såsom CenterNet og FCOS (Fully Convolutional One-Stage Object Detection), eliminerer foruddefinerede ankerbokse og forudsiger i stedet objektcentrene direkte. Disse metoder tilbyder:
- Enklere modelarkitekturer;
- Hurtigere inferenshastigheder;
- Forbedret generalisering til ukendte objektstørrelser.

A (Anchor-baseret): forudsiger forskydninger (grønne linjer) fra foruddefinerede ankre (blå) for at matche sand grund (rød). B (Anchor-fri): estimerer direkte forskydninger fra et punkt til dets grænser.
Forudsigelse af afgrænsningsbokse er en central del af objektdetektion, hvor forskellige tilgange balancerer nøjagtighed og effektivitet. Anchor-baserede metoder øger præcisionen ved at anvende foruddefinerede former, mens anchor-frie metoder forenkler detektionen ved direkte at forudsige objektplaceringer. Forståelse af disse teknikker understøtter udviklingen af bedre objektdetektionssystemer til forskellige praktiske anvendelser.
1. Hvilke oplysninger indeholder en bounding box-forudsigelse typisk?
2. Hvad er den primære fordel ved anchor-baserede metoder i objektgenkendelse?
3. Hvilken udfordring står direkte regression overfor ved forudsigelse af bounding boxes?
Tak for dine kommentarer!
Spørg AI
Spørg AI

Spørg om hvad som helst eller prøv et af de foreslåede spørgsmål for at starte vores chat
