Generative Adversarial Networks (GANs)
Swipe um das Menü anzuzeigen
Generative Adversarial Networks (GANs) sind eine Klasse generativer Modelle, die 2014 von Ian Goodfellow eingeführt wurden. Sie bestehen aus zwei neuronalen Netzwerken – dem Generator und dem Discriminator –, die gleichzeitig in einem spieltheoretischen Rahmen trainiert werden. Der Generator versucht, Daten zu erzeugen, die den echten Daten ähneln, während der Discriminator versucht, echte Daten von generierten Daten zu unterscheiden.
GANs lernen, Datensamples aus Rauschen zu generieren, indem sie ein Minimax-Spiel lösen. Im Verlauf des Trainings wird der Generator immer besser darin, realistische Daten zu erzeugen, und der Discriminator verbessert sich darin, echte von gefälschten Daten zu unterscheiden.
Architektur eines GAN
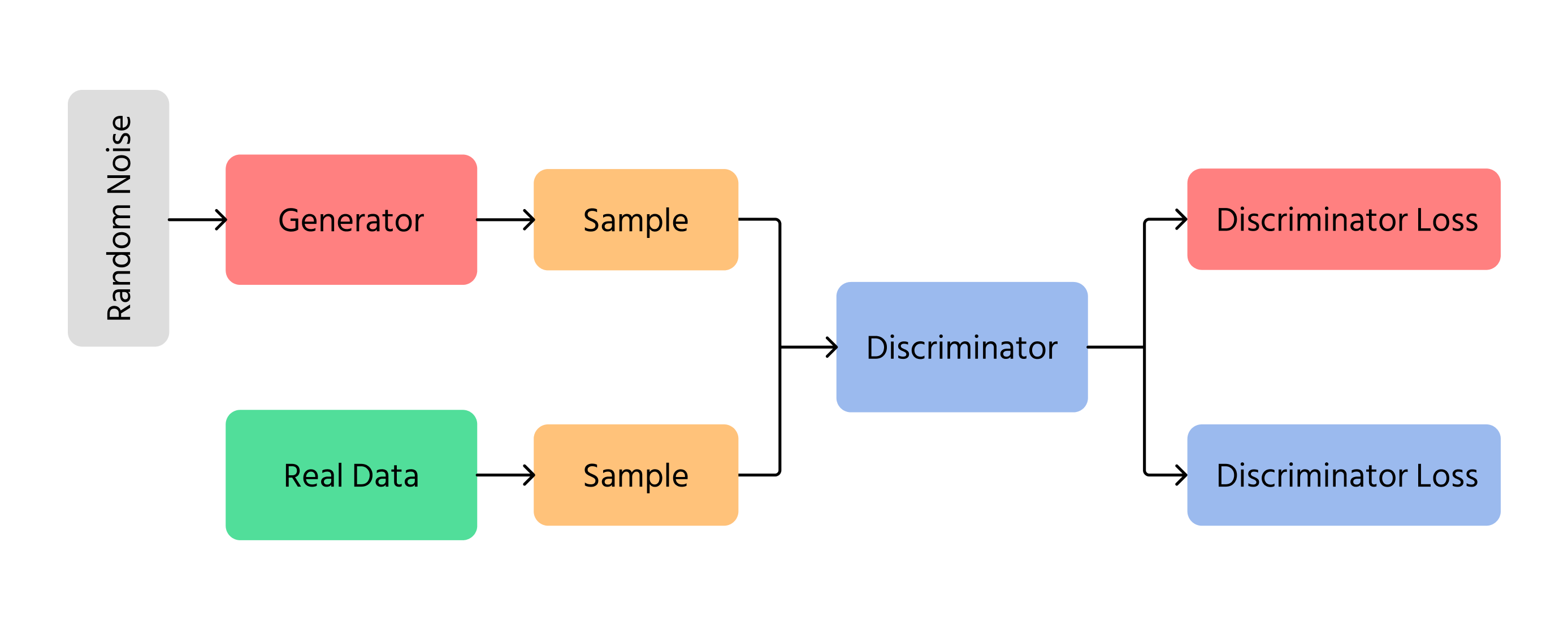
Ein grundlegendes GAN-Modell besteht aus zwei zentralen Komponenten:
1. Generator (G)
- Nimmt einen zufälligen Rauschvektor z∼pz(z) als Eingabe;
- Wandelt diesen durch ein neuronales Netzwerk in eine Datenausgabe G(z) um, die der wahren Verteilung ähneln soll.
2. Diskriminator (D)
- Nimmt entweder eine echte Datenprobe x∼px(x) oder eine generierte Probe G(z) entgegen;
- Gibt einen Skalar zwischen 0 und 1 aus, der die Wahrscheinlichkeit schätzt, dass die Eingabe echt ist.
Diese beiden Komponenten werden gleichzeitig trainiert. Der Generator versucht, realistische Proben zu erzeugen, um den Diskriminator zu täuschen, während der Diskriminator darauf abzielt, echte von generierten Proben korrekt zu unterscheiden.
Minimax-Spiel der GANs
Im Zentrum der GANs steht das Minimax-Spiel, ein Konzept aus der Spieltheorie. In diesem Aufbau gilt:
- Der Generator G und der Diskriminator D sind konkurrierende Spieler;
- D versucht, seine Fähigkeit zu maximieren, echte von generierten Daten zu unterscheiden;
- G versucht, die Fähigkeit von D zu minimieren, seine gefälschten Daten zu erkennen.
Diese Dynamik definiert ein Nullsummenspiel, bei dem der Gewinn des einen Spielers der Verlust des anderen ist. Die Optimierung ist definiert als:
GminDmaxV(D,G)=Ex∼px[logD(x)]+Ez∼pz[log(1−D(G(z)))]Der Generator versucht, den Diskriminator zu täuschen, indem er Stichproben G(z) erzeugt, die den echten Daten so ähnlich wie möglich sind.
Verlustfunktionen
Während das ursprüngliche GAN-Ziel ein Minimax-Spiel definiert, werden in der Praxis alternative Verlustfunktionen verwendet, um das Training zu stabilisieren.
- Nicht-sättigender Generator-Verlust:
Dies hilft dem Generator, auch dann starke Gradienten zu erhalten, wenn der Diskriminator gut arbeitet.
- Diskriminator-Verlust:
Diese Verluste fördern, dass der Generator Stichproben erzeugt, die die Unsicherheit des Diskriminators erhöhen und die Konvergenz während des Trainings verbessern.
Wichtige Varianten von GAN-Architekturen
Mehrere Typen von GANs wurden entwickelt, um spezifische Einschränkungen zu überwinden oder die Leistung zu verbessern:

Conditional GAN (cGAN)
Conditional GANs erweitern das Standard-GAN-Framework, indem sie zusätzliche Informationen (in der Regel Labels) sowohl in den Generator als auch in den Diskriminator einführen. Anstatt Daten nur aus Zufallsrauschen zu generieren, erhält der Generator sowohl Rauschen z als auch eine Bedingung y (z. B. eine Klassenbezeichnung). Der Diskriminator erhält ebenfalls y, um zu beurteilen, ob die Probe unter dieser Bedingung realistisch ist.
- Anwendungsfälle: klassenkonditionierte Bildgenerierung, Bild-zu-Bild-Übersetzung, Text-zu-Bild-Generierung.
Deep Convolutional GAN (DCGAN)
DCGANs ersetzen die vollständig verbundenen Schichten in den ursprünglichen GANs durch Faltungs- und transponierte Faltungsschichten, wodurch sie effektiver für die Bildgenerierung werden. Sie führen außerdem architektonische Richtlinien ein, wie das Entfernen vollständig verbundener Schichten, die Verwendung von Batch-Normalisierung und den Einsatz von ReLU/LeakyReLU-Aktivierungen.
- Anwendungsfälle: fotorealistische Bildgenerierung, Erlernen visueller Repräsentationen, unüberwachtes Merkmalslernen.
CycleGAN CycleGANs lösen das Problem der unüberwachten Bild-zu-Bild-Übersetzung. Im Gegensatz zu anderen Modellen, die gepaarte Datensätze benötigen (z. B. dasselbe Foto in zwei verschiedenen Stilen), können CycleGANs Abbildungen zwischen zwei Domänen ohne gepaarte Beispiele erlernen. Sie verwenden zwei Generatoren und zwei Diskriminatoren, die jeweils für eine Richtung der Abbildung zuständig sind (z. B. Fotos zu Gemälden und umgekehrt), und erzwingen einen Zykluskonsistenzverlust, um sicherzustellen, dass eine Übersetzung von einer Domäne zur anderen und zurück das ursprüngliche Bild ergibt. Dieser Verlust ist entscheidend für die Erhaltung von Inhalt und Struktur.
Zykluskonsistenzverlust gewährleistet:
GBA(GAB(x))≈x und GAB(GBA(y))≈ywobei:
- GAB Bilder von Domäne A nach Domäne B abbildet;
- GBA von Domäne B nach Domäne A abbildet.
- x∈A,y∈B.
Anwendungsfälle: Umwandlung von Fotos in Kunstwerke, Übersetzung von Pferd zu Zebra, Stimmkonvertierung zwischen Sprechern.
StyleGAN
StyleGAN, entwickelt von NVIDIA, führt eine stilbasierte Steuerung im Generator ein. Anstatt einen Rauschvektor direkt in den Generator einzuspeisen, wird dieser durch ein Mapping-Netzwerk geleitet, um "Style-Vektoren" zu erzeugen, die jede Schicht des Generators beeinflussen. Dies ermöglicht eine feine Kontrolle über visuelle Merkmale wie Haarfarbe, Gesichtsausdruck oder Beleuchtung.
Bemerkenswerte Innovationen:
- Style Mixing, ermöglicht das Kombinieren mehrerer latenter Codes;
- Adaptive Instance Normalization (AdaIN), steuert die Feature-Maps im Generator;
- Progressives Wachstum, das Training beginnt mit niedriger Auflösung und steigert sich im Verlauf.
Anwendungsfälle: Ultra-hochauflösende Bildgenerierung (z. B. Gesichter), Steuerung visueller Attribute, Kunstgenerierung.
Vergleich: GANs vs VAEs
GANs sind eine leistungsstarke Klasse generativer Modelle, die durch einen adversarialen Trainingsprozess hochrealistische Daten erzeugen können. Im Kern steht ein Minimax-Spiel zwischen zwei Netzwerken, bei dem adversariale Verluste genutzt werden, um beide Komponenten iterativ zu verbessern. Ein solides Verständnis ihrer Architektur, Verlustfunktionen—einschließlich Varianten wie cGAN, DCGAN, CycleGAN und StyleGAN—sowie der Vergleich mit anderen Modellen wie VAEs vermittelt die notwendige Grundlage für Anwendungen in Bereichen wie Bildgenerierung, Videosynthese, Datenaugmentation und mehr.
1. Welche der folgenden Aussagen beschreibt die Komponenten einer grundlegenden GAN-Architektur am besten?
2. Was ist das Ziel des Minimax-Spiels in GANs?
3. Welche der folgenden Aussagen trifft den Unterschied zwischen GANs und VAEs am besten?
Danke für Ihr Feedback!
Fragen Sie AI
Fragen Sie AI

Fragen Sie alles oder probieren Sie eine der vorgeschlagenen Fragen, um unser Gespräch zu beginnen
Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) sind eine Klasse generativer Modelle, die 2014 von Ian Goodfellow eingeführt wurden. Sie bestehen aus zwei neuronalen Netzwerken – dem Generator und dem Discriminator –, die gleichzeitig in einem spieltheoretischen Rahmen trainiert werden. Der Generator versucht, Daten zu erzeugen, die den echten Daten ähneln, während der Discriminator versucht, echte Daten von generierten Daten zu unterscheiden.
GANs lernen, Datensamples aus Rauschen zu generieren, indem sie ein Minimax-Spiel lösen. Im Verlauf des Trainings wird der Generator immer besser darin, realistische Daten zu erzeugen, und der Discriminator verbessert sich darin, echte von gefälschten Daten zu unterscheiden.
Architektur eines GAN
Ein grundlegendes GAN-Modell besteht aus zwei zentralen Komponenten:
1. Generator (G)
- Nimmt einen zufälligen Rauschvektor z∼pz(z) als Eingabe;
- Wandelt diesen durch ein neuronales Netzwerk in eine Datenausgabe G(z) um, die der wahren Verteilung ähneln soll.
2. Diskriminator (D)
- Nimmt entweder eine echte Datenprobe x∼px(x) oder eine generierte Probe G(z) entgegen;
- Gibt einen Skalar zwischen 0 und 1 aus, der die Wahrscheinlichkeit schätzt, dass die Eingabe echt ist.
Diese beiden Komponenten werden gleichzeitig trainiert. Der Generator versucht, realistische Proben zu erzeugen, um den Diskriminator zu täuschen, während der Diskriminator darauf abzielt, echte von generierten Proben korrekt zu unterscheiden.
Minimax-Spiel der GANs
Im Zentrum der GANs steht das Minimax-Spiel, ein Konzept aus der Spieltheorie. In diesem Aufbau gilt:
- Der Generator G und der Diskriminator D sind konkurrierende Spieler;
- D versucht, seine Fähigkeit zu maximieren, echte von generierten Daten zu unterscheiden;
- G versucht, die Fähigkeit von D zu minimieren, seine gefälschten Daten zu erkennen.
Diese Dynamik definiert ein Nullsummenspiel, bei dem der Gewinn des einen Spielers der Verlust des anderen ist. Die Optimierung ist definiert als:
GminDmaxV(D,G)=Ex∼px[logD(x)]+Ez∼pz[log(1−D(G(z)))]Der Generator versucht, den Diskriminator zu täuschen, indem er Stichproben G(z) erzeugt, die den echten Daten so ähnlich wie möglich sind.
Verlustfunktionen
Während das ursprüngliche GAN-Ziel ein Minimax-Spiel definiert, werden in der Praxis alternative Verlustfunktionen verwendet, um das Training zu stabilisieren.
- Nicht-sättigender Generator-Verlust:
Dies hilft dem Generator, auch dann starke Gradienten zu erhalten, wenn der Diskriminator gut arbeitet.
- Diskriminator-Verlust:
Diese Verluste fördern, dass der Generator Stichproben erzeugt, die die Unsicherheit des Diskriminators erhöhen und die Konvergenz während des Trainings verbessern.
Wichtige Varianten von GAN-Architekturen
Mehrere Typen von GANs wurden entwickelt, um spezifische Einschränkungen zu überwinden oder die Leistung zu verbessern:
Conditional GAN (cGAN)
Conditional GANs erweitern das Standard-GAN-Framework, indem sie zusätzliche Informationen (in der Regel Labels) sowohl in den Generator als auch in den Diskriminator einführen. Anstatt Daten nur aus Zufallsrauschen zu generieren, erhält der Generator sowohl Rauschen z als auch eine Bedingung y (z. B. eine Klassenbezeichnung). Der Diskriminator erhält ebenfalls y, um zu beurteilen, ob die Probe unter dieser Bedingung realistisch ist.
- Anwendungsfälle: klassenkonditionierte Bildgenerierung, Bild-zu-Bild-Übersetzung, Text-zu-Bild-Generierung.
Deep Convolutional GAN (DCGAN)
DCGANs ersetzen die vollständig verbundenen Schichten in den ursprünglichen GANs durch Faltungs- und transponierte Faltungsschichten, wodurch sie effektiver für die Bildgenerierung werden. Sie führen außerdem architektonische Richtlinien ein, wie das Entfernen vollständig verbundener Schichten, die Verwendung von Batch-Normalisierung und den Einsatz von ReLU/LeakyReLU-Aktivierungen.
- Anwendungsfälle: fotorealistische Bildgenerierung, Erlernen visueller Repräsentationen, unüberwachtes Merkmalslernen.
CycleGAN CycleGANs lösen das Problem der unüberwachten Bild-zu-Bild-Übersetzung. Im Gegensatz zu anderen Modellen, die gepaarte Datensätze benötigen (z. B. dasselbe Foto in zwei verschiedenen Stilen), können CycleGANs Abbildungen zwischen zwei Domänen ohne gepaarte Beispiele erlernen. Sie verwenden zwei Generatoren und zwei Diskriminatoren, die jeweils für eine Richtung der Abbildung zuständig sind (z. B. Fotos zu Gemälden und umgekehrt), und erzwingen einen Zykluskonsistenzverlust, um sicherzustellen, dass eine Übersetzung von einer Domäne zur anderen und zurück das ursprüngliche Bild ergibt. Dieser Verlust ist entscheidend für die Erhaltung von Inhalt und Struktur.
Zykluskonsistenzverlust gewährleistet:
GBA(GAB(x))≈x und GAB(GBA(y))≈ywobei:
- GAB Bilder von Domäne A nach Domäne B abbildet;
- GBA von Domäne B nach Domäne A abbildet.
- x∈A,y∈B.
Anwendungsfälle: Umwandlung von Fotos in Kunstwerke, Übersetzung von Pferd zu Zebra, Stimmkonvertierung zwischen Sprechern.
StyleGAN
StyleGAN, entwickelt von NVIDIA, führt eine stilbasierte Steuerung im Generator ein. Anstatt einen Rauschvektor direkt in den Generator einzuspeisen, wird dieser durch ein Mapping-Netzwerk geleitet, um "Style-Vektoren" zu erzeugen, die jede Schicht des Generators beeinflussen. Dies ermöglicht eine feine Kontrolle über visuelle Merkmale wie Haarfarbe, Gesichtsausdruck oder Beleuchtung.
Bemerkenswerte Innovationen:
- Style Mixing, ermöglicht das Kombinieren mehrerer latenter Codes;
- Adaptive Instance Normalization (AdaIN), steuert die Feature-Maps im Generator;
- Progressives Wachstum, das Training beginnt mit niedriger Auflösung und steigert sich im Verlauf.
Anwendungsfälle: Ultra-hochauflösende Bildgenerierung (z. B. Gesichter), Steuerung visueller Attribute, Kunstgenerierung.
Vergleich: GANs vs VAEs
GANs sind eine leistungsstarke Klasse generativer Modelle, die durch einen adversarialen Trainingsprozess hochrealistische Daten erzeugen können. Im Kern steht ein Minimax-Spiel zwischen zwei Netzwerken, bei dem adversariale Verluste genutzt werden, um beide Komponenten iterativ zu verbessern. Ein solides Verständnis ihrer Architektur, Verlustfunktionen—einschließlich Varianten wie cGAN, DCGAN, CycleGAN und StyleGAN—sowie der Vergleich mit anderen Modellen wie VAEs vermittelt die notwendige Grundlage für Anwendungen in Bereichen wie Bildgenerierung, Videosynthese, Datenaugmentation und mehr.
Danke für Ihr Feedback!
