single
KDE-Diagramm
Swipe um das Menü anzuzeigen
Ein Kernel-Dichteschätzer (KDE) Plot ist eine Art Diagramm, das die geschätzte Wahrscheinlichkeitsdichtefunktion einer kontinuierlichen Variablen visualisiert. Im Gegensatz zu einem Histogramm, das Daten mit diskreten Balken in Intervallen darstellt, zeigt ein KDE-Plot die Verteilung als glatte, kontinuierliche Kurve, die auf allen Datenpunkten basiert.
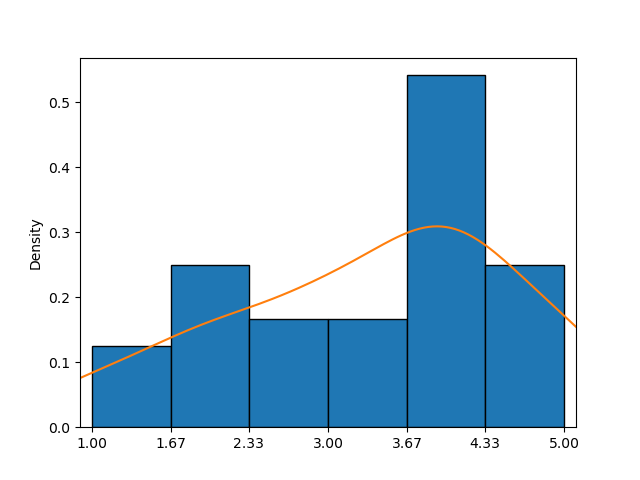
Dieses Beispiel zeigt ein Histogramm kombiniert mit einem KDE-Plot (orangefarbene Kurve), was eine klarere Annäherung an die Wahrscheinlichkeitsdichtefunktion bietet als das Histogramm allein.
In seaborn ermöglicht die Funktion kdeplot() das einfache Erstellen von KDE-Plots. Die wichtigsten Parameter—data, x und y—funktionieren genauso wie bei countplot().
Erste Option
Nur einer der Parameter kann durch Übergeben einer Wertesequenz festgelegt werden, was eine individuelle Anpassung der einzelnen Elemente ermöglicht.
123456789101112import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # Loading the dataset with the average yearly temperatures in Boston and Seattle url = 'https://content-media-cdn.codefinity.com/courses/47339f29-4722-4e72-a0d4-6112c70ff738/weather_data.csv' weather_df = pd.read_csv(url, index_col=0) # Creating a KDE plot setting only the data parameter sns.kdeplot(data=weather_df['Seattle'], fill=True) plt.show()
Der Parameter data wird durch Übergeben eines Series-Objekts gesetzt, und der Parameter fill wird verwendet, um den Bereich unter der Kurve auszufüllen, der standardmäßig nicht ausgefüllt ist.
Zweite Option
Es ist ebenfalls möglich, ein 2D-Objekt wie ein DataFrame für data zu setzen und einen Spaltennamen oder einen Schlüssel, falls data ein Dictionary ist, für x (vertikale Ausrichtung) oder y (horizontale Ausrichtung) anzugeben:
123456789101112import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # Loading the dataset with the average yearly temperatures in Boston and Seattle url = 'https://content-media-cdn.codefinity.com/courses/47339f29-4722-4e72-a0d4-6112c70ff738/weather_data.csv' weather_df = pd.read_csv(url, index_col=0) # Creating a KDE plot setting both the data and x parameters sns.kdeplot(data=weather_df, x='Seattle', fill=True) plt.show()
Das gleiche Ergebnis wurde erzielt, indem das gesamte DataFrame als data-Parameter übergeben und der Spaltenname für den x-Parameter angegeben wurde.
Das erstellte KDE-Diagramm zeigt eine charakteristische Glockenkurve, die einer Normalverteilung mit einem Mittelwert von etwa 52°F ähnelt.
Falls Sie mehr über die Funktion KDE-Plot erfahren möchten, finden Sie weitere Informationen in der kdeplot() Dokumentation.
Wischen, um mit dem Codieren zu beginnen
- Die korrekte Funktion zur Erstellung eines KDE-Plots verwenden.
countries_dfals Datensatz für den Plot nutzen (erstes Argument).- Die Spalte
'GDP per capita'auswählen und die Ausrichtung über das zweite Argument auf horizontal setzen. - Den Bereich unter der Kurve über das dritte (rechte) Argument ausfüllen.
Lösung
Danke für Ihr Feedback!
single
Fragen Sie AI
Fragen Sie AI

Fragen Sie alles oder probieren Sie eine der vorgeschlagenen Fragen, um unser Gespräch zu beginnen
