single
Implementierung Neuronaler Netzwerke
Swipe um das Menü anzuzeigen
Überblick über grundlegende neuronale Netzwerke
Sie haben nun einen Stand erreicht, an dem Sie über das notwendige Wissen zu TensorFlow verfügen, um eigene neuronale Netzwerke zu erstellen. Während die meisten neuronalen Netzwerke in der Praxis komplex sind und typischerweise mit High-Level-Bibliotheken wie Keras entwickelt werden, werden wir ein einfaches Netzwerk mit grundlegenden TensorFlow-Werkzeugen aufbauen. Dieser Ansatz ermöglicht praktische Erfahrungen mit Low-Level-Tensor-Manipulationen und hilft, die zugrunde liegenden Prozesse besser zu verstehen.
In früheren Kursen wie Einführung in neuronale Netzwerke erinnern Sie sich vielleicht daran, wie viel Zeit und Aufwand es gekostet hat, selbst ein einfaches neuronales Netzwerk zu erstellen, bei dem jedes Neuron einzeln behandelt wurde.

TensorFlow vereinfacht diesen Prozess erheblich. Durch die Nutzung von Tensors können Sie komplexe Berechnungen kapseln und den Bedarf an aufwendigem Code reduzieren. Die Hauptaufgabe besteht darin, eine sequenzielle Pipeline von Tensor-Operationen einzurichten.
Hier eine kurze Auffrischung der Schritte, um einen Trainingsprozess für ein neuronales Netzwerk zu starten:
Datenvorbereitung und Modellerstellung
Die Anfangsphase des Trainings eines neuronalen Netzwerks umfasst die Vorbereitung der Daten, einschließlich der Eingaben und Ausgaben, von denen das Netzwerk lernen soll. Zusätzlich werden die Hyperparameter des Modells festgelegt – dies sind die Parameter, die während des gesamten Trainingsprozesses konstant bleiben. Die Gewichte werden initialisiert, typischerweise aus einer Normalverteilung gezogen, und die Biases werden häufig auf Null gesetzt.
Vorwärtsausbreitung
Bei der Vorwärtsausbreitung durchläuft jede Schicht des Netzwerks typischerweise folgende Schritte:
- Multiplikation des Schichteingangs mit den Gewichten.
- Addition eines Bias zum Ergebnis.
- Anwendung einer Aktivierungsfunktion auf diese Summe.
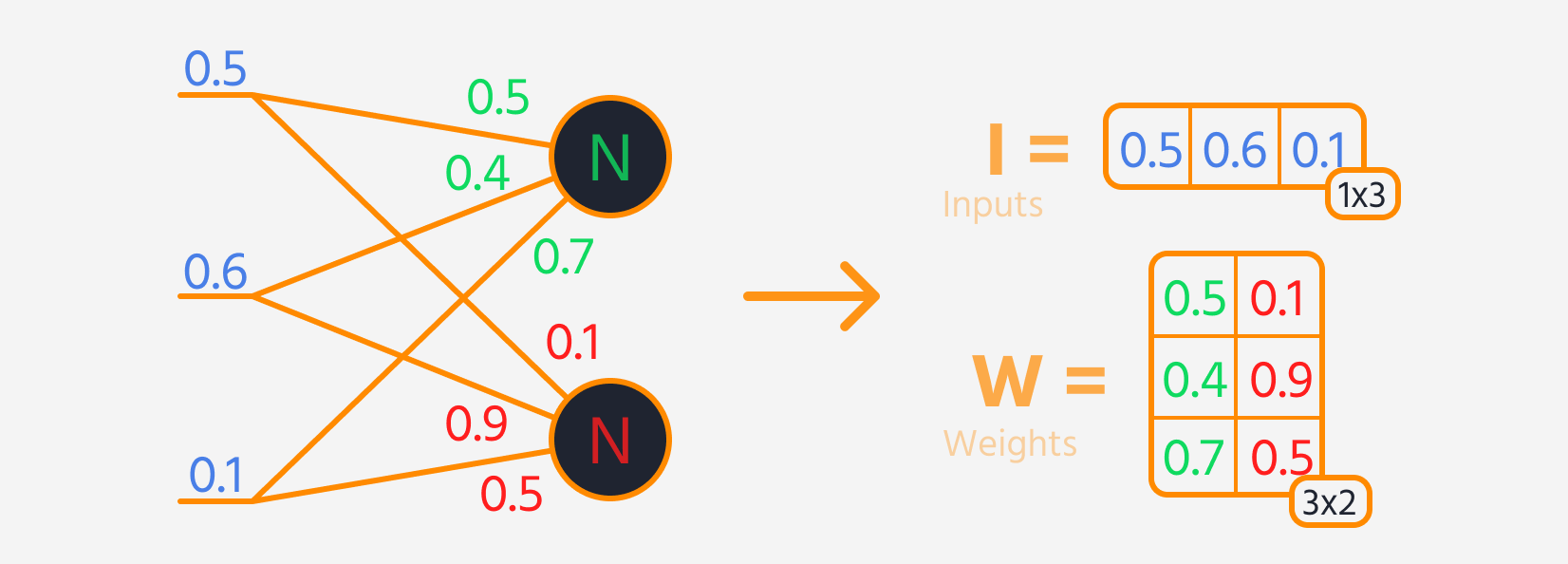
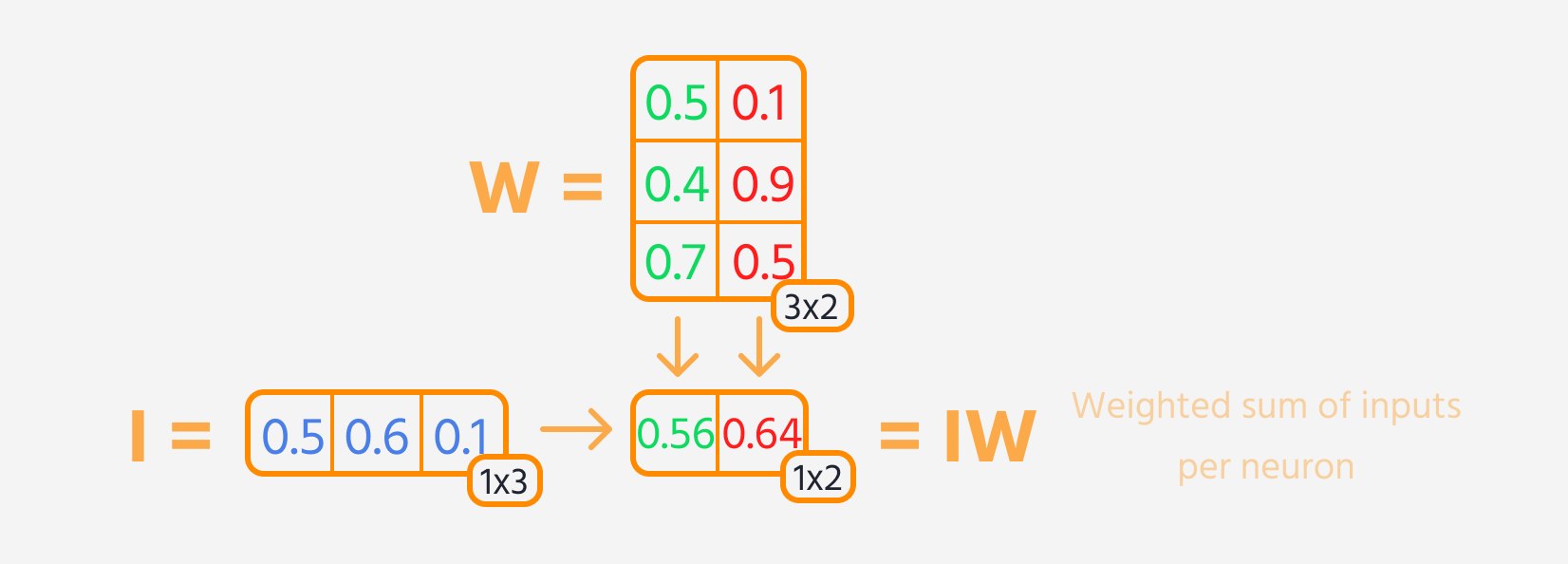
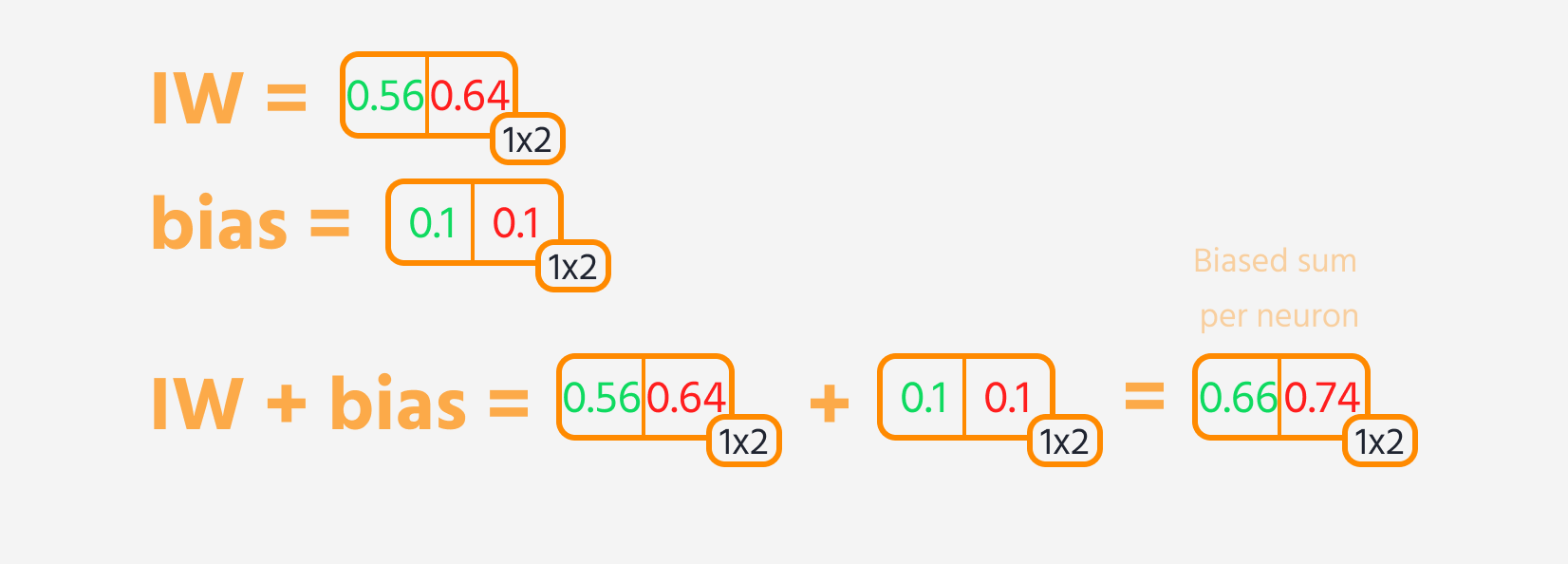


Dann kann der Verlust berechnet werden.
Rückwärtspropagation
Der nächste Schritt ist die Rückwärtspropagation, bei der Gewichte und Biases angepasst werden, basierend auf ihrem Einfluss auf den Verlust. Dieser Einfluss wird durch den Gradienten dargestellt, den TensorFlows Gradient Tape automatisch berechnet. Die Gewichte und Biases werden aktualisiert, indem der Gradient, skaliert mit der Lernrate, subtrahiert wird.
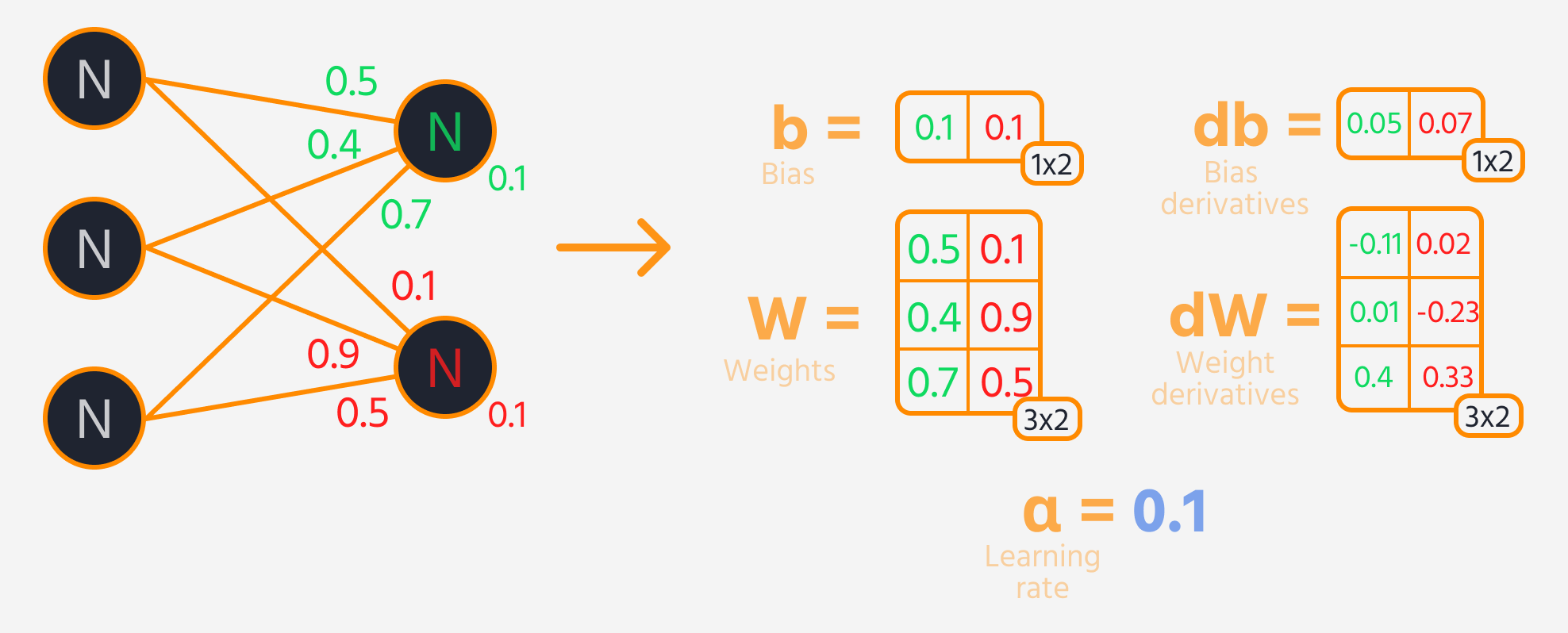
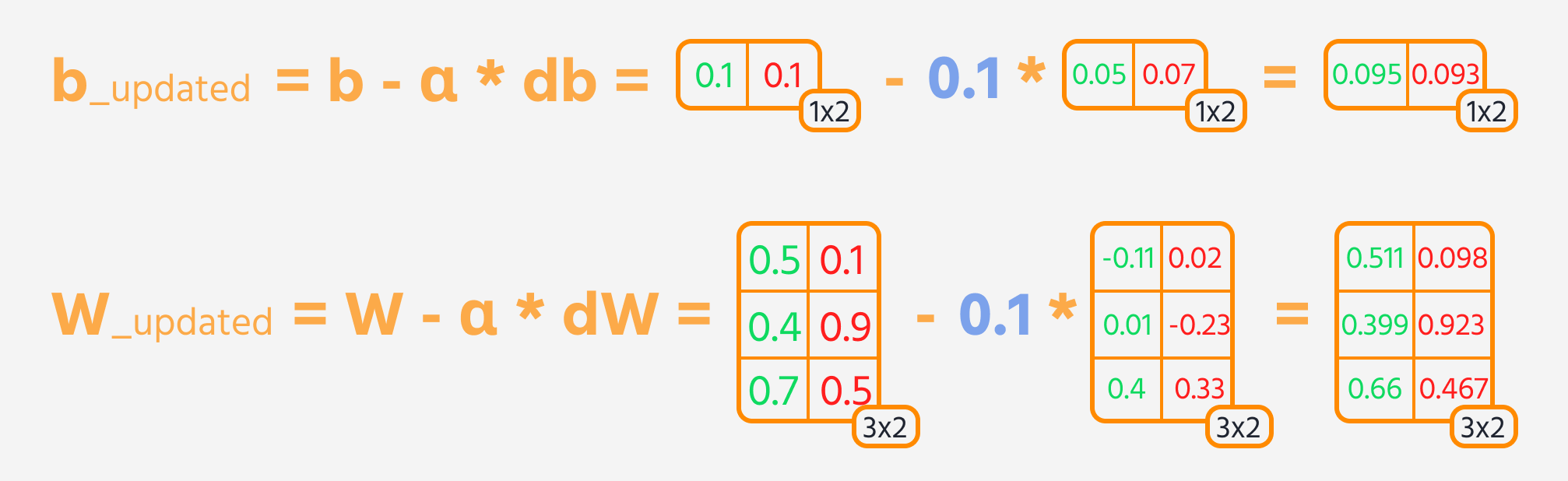
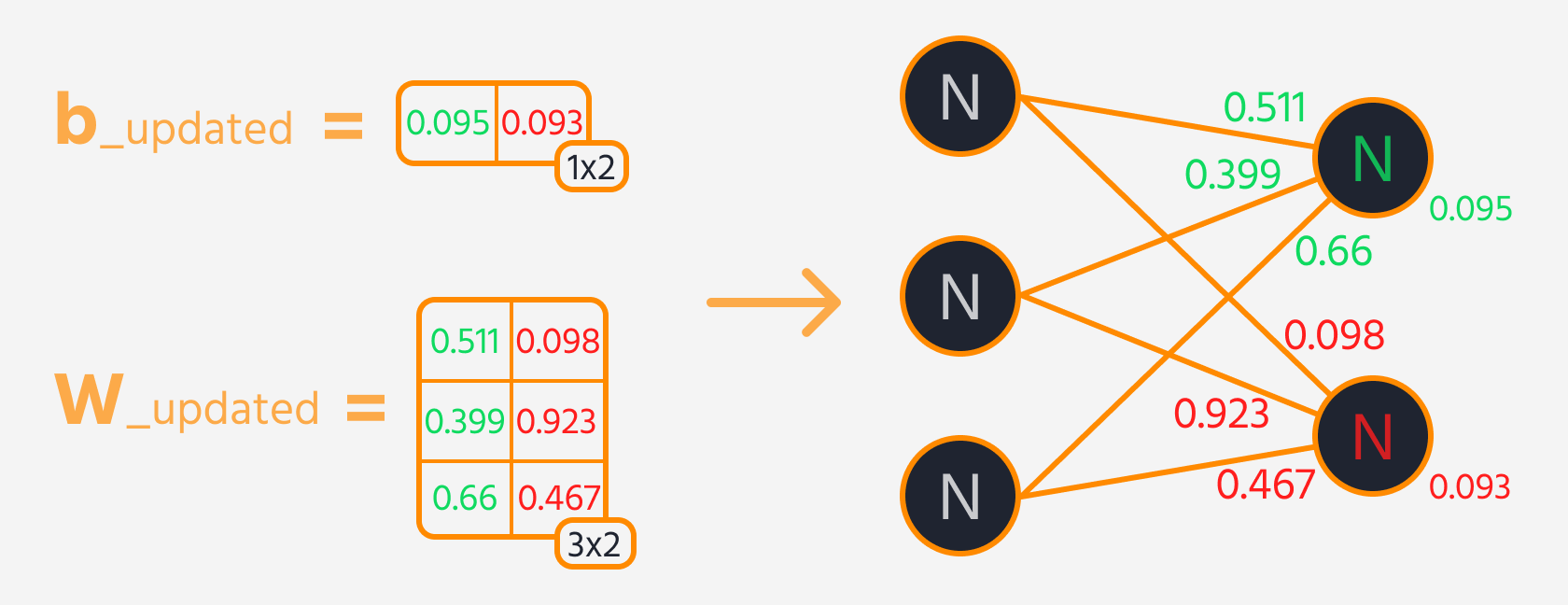
Trainingsschleife
Um das neuronale Netzwerk effektiv zu trainieren, werden die Trainingsschritte mehrfach wiederholt, während die Leistung des Modells überwacht wird. Idealerweise sollte der Loss über die Epochen hinweg abnehmen.
Wischen, um mit dem Codieren zu beginnen
Erstellung eines neuronalen Netzwerks zur Vorhersage der Ergebnisse der XOR-Operation. Das Netzwerk soll aus 2 Eingabeneuronen, einer versteckten Schicht mit 2 Neuronen und 1 Ausgabeneuron bestehen.
- Initialisierung der Gewichte und Biases: Die Gewichte werden mit einer Normalverteilung initialisiert, die Biases werden alle auf Null gesetzt. Verwenden Sie die Hyperparameter
input_size,hidden_sizeundoutput_size, um die passenden Formen für diese Tensoren zu definieren. - Verwenden Sie einen Funktions-Dekorator, um die Funktion
train_step()in einen TensorFlow-Graphen umzuwandeln. - Führen Sie die Vorwärtspropagation durch sowohl die versteckte als auch die Ausgabeschicht des Netzwerks durch. Verwenden Sie die Sigmoid-Aktivierungsfunktion.
- Bestimmen Sie die Gradienten, um zu verstehen, wie jedes Gewicht und jeder Bias den Verlust beeinflusst. Achten Sie darauf, dass die Gradienten in der richtigen Reihenfolge berechnet werden, entsprechend den Namen der Ausgabewerte.
- Passen Sie die Gewichte und Biases basierend auf ihren jeweiligen Gradienten an. Integrieren Sie die
learning_ratein diesen Anpassungsprozess, um das Ausmaß jeder Aktualisierung zu steuern.
Lösung
Datenvorbereitung
X_data: Dies sind die Eingabedaten für die XOR-Funktion. Es handelt sich um ein NumPy-Array der Form (4, 2), das die vier möglichen Kombinationen der XOR-Eingaben (0,0), (0,1), (1,0) und (1,1) repräsentiert;Y_data: Dies ist die Zielausgabe für jede Eingabekombination inX_data. Es ist ebenfalls ein NumPy-Array, jedoch der Form (4, 1), das die XOR-Ausgabe für jedes Eingabepaar darstellt.
Netzwerkparameter
input_size: Die Größe der Eingabeschicht, festgelegt auf 2, entsprechend den zwei Eingabeknoten (für die beiden Eingaben der XOR-Funktion);hidden_size: Die Größe der versteckten Schicht, ebenfalls auf 2 gesetzt. Diese Wahl ist relativ willkürlich, reicht aber aus, um die XOR-Funktion zu erlernen;output_size: Die Größe der Ausgabeschicht, festgelegt auf 1, entsprechend dem einzelnen Ausgabeknoten (dem Ergebnis der XOR-Operation);learning_rate: Die Lernrate für den Optimierungsalgorithmus, steuert, wie stark die Gewichte während des Trainings angepasst werden.
Gewichte und Biases
W1undb1: Die Gewichte (W1) und Biases (b1) für die Verbindungen von der Eingabeschicht zur versteckten Schicht.W1ist eine TensorFlow-Variable, die mit Zufallswerten initialisiert wird und die Form(input_size, hidden_size), also(2, 2), hat.b1ist eine TensorFlow-Variable, die mit Nullen initialisiert wird und die Form(hidden_size), also(2), hat;W2undb2: Die Gewichte (W2) und Biases (b2) für die Verbindungen von der versteckten Schicht zur Ausgabeschicht.W2wird mit Zufallswerten initialisiert und hat die Form(hidden_size, output_size), also(2, 1).b2wird mit Nullen initialisiert und hat die Form(output_size), also(1).
Trainingsfunktion
train_step(): Dies ist die zentrale Trainingsfunktion. Sie verwendettf.GradientTape()für die automatische Differenzierung. Im Forward-Pass werden die Aktivierungen der versteckten Schicht (a1) und die Ausgabewerte (Y_pred) berechnet. Der Loss wird als mittlere quadratische Abweichung zwischenY_predundYberechnet. Anschließend werden die Gradienten berechnet und die Gewichte sowie Biases aktualisiert;tf.sigmoid(): Es wird eine Sigmoid-Aktivierungsfunktion verwendet, die den Input in einen Wert zwischen0und1transformiert. Diese wird sowohl für die versteckte Schicht als auch für die Ausgabeschicht genutzt.
Trainingsschleife
- Das Netzwerk wird für
2500Epochen trainiert. In jeder Epoche wird die Funktiontrain_step()aufgerufen und die Gewichte werden aktualisiert. Der Loss wird alle500Epochen ausgegeben, um den Trainingsfortschritt zu überwachen.
Fazit
Da die XOR-Funktion eine relativ einfache Aufgabe ist, sind fortgeschrittene Techniken wie Hyperparameter-Tuning, Datensatzaufteilung oder der Aufbau komplexer Datenpipelines an dieser Stelle nicht erforderlich. Diese Übung ist lediglich ein Schritt auf dem Weg zu komplexeren neuronalen Netzwerken für reale Anwendungen.
Das Beherrschen dieser Grundlagen ist entscheidend, bevor fortgeschrittene Techniken zum Aufbau neuronaler Netzwerke in den kommenden Kursen behandelt werden, in denen die Keras-Bibliothek verwendet und Methoden zur Verbesserung der Modellqualität mit den umfangreichen Funktionen von TensorFlow erforscht werden.
Danke für Ihr Feedback!
single
Fragen Sie AI
Fragen Sie AI

Fragen Sie alles oder probieren Sie eine der vorgeschlagenen Fragen, um unser Gespräch zu beginnen
