Implementierung von Word2vec
Swipe um das Menü anzuzeigen
Nachdem Sie verstanden haben, wie Word2Vec funktioniert, fahren wir mit der Implementierung in Python fort. Die Gensim-Bibliothek, ein leistungsstarkes Open-Source-Tool für die Verarbeitung natürlicher Sprache, bietet eine unkomplizierte Implementierung über die Word2Vec-Klasse in gensim.models.
Datenvorbereitung
Word2Vec erfordert, dass die Textdaten tokenisiert werden, d. h. in eine Liste von Listen aufgeteilt werden, wobei jede innere Liste die Wörter eines bestimmten Satzes enthält. In diesem Beispiel verwenden wir den Roman Emma der englischen Autorin Jane Austen als Korpus. Wir laden eine CSV-Datei mit vorverarbeiteten Sätzen und teilen dann jeden Satz in Wörter auf:
12345678import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') # Split each sentence into words sentences = emma_df['Sentence'].str.split() # Print the fourth sentence (list of words) print(sentences[3])
emma_df['Sentence'].str.split() wendet die Methode .split() auf jeden Satz in der Spalte 'Sentence' an und erzeugt so eine Liste von Wörtern für jeden Satz. Da die Sätze bereits vorverarbeitet wurden und die Wörter durch Leerzeichen getrennt sind, reicht die Methode .split() für diese Tokenisierung aus.
Training des Word2Vec-Modells
Im Folgenden liegt der Fokus auf dem Training des Word2Vec-Modells mit den tokenisierten Daten. Die Word2Vec-Klasse bietet verschiedene Parameter zur Anpassung. Am häufigsten werden jedoch die folgenden Parameter verwendet:
vector_size(standardmäßig 100): die Dimensionalität bzw. Größe der Wort-Embeddings;window(standardmäßig 5): die Größe des Kontextfensters;min_count(standardmäßig 5): Wörter, die seltener als dieser Wert vorkommen, werden ignoriert;sg(standardmäßig 0): die zu verwendende Modellarchitektur (1 für Skip-gram, 0 für CBoW).cbow_mean(standardmäßig 1): gibt an, ob der CBoW-Kontext aufsummiert (0) oder gemittelt (1) wird
Bezüglich der Modellarchitekturen eignet sich CBoW für größere Datensätze und Szenarien, in denen Recheneffizienz entscheidend ist. Skip-gram hingegen ist vorzuziehen, wenn ein detailliertes Verständnis von Wortkontexten erforderlich ist, insbesondere bei kleineren Datensätzen oder beim Umgang mit seltenen Wörtern.
12345678from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() # Initialize the model model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0)
Hier setzen wir die Embedding-Größe auf 200, die Kontextfenstergröße auf 5 und schließen alle Wörter ein, indem wir min_count=1 setzen. Durch das Setzen von sg=0 haben wir das CBoW-Modell gewählt.
Die Wahl der richtigen Embedding-Größe und des Kontextfensters erfordert Abwägungen. Größere Embeddings erfassen mehr Bedeutung, erhöhen jedoch die Rechenkosten und das Risiko von Overfitting. Kleinere Kontextfenster eignen sich besser zur Erfassung der Syntax, während größere besser die Semantik abbilden.
Ähnliche Wörter finden
Sobald Wörter als Vektoren dargestellt werden, können wir sie vergleichen, um Ähnlichkeiten zu messen. Während die Verwendung von Distanzen eine Möglichkeit ist, trägt die Richtung eines Vektors oft mehr semantische Bedeutung als seine Länge, insbesondere bei Wort-Embeddings.
Die Verwendung eines Winkels als Ähnlichkeitsmaß ist jedoch nicht besonders praktisch. Stattdessen kann der Kosinus des Winkels zwischen zwei Vektoren verwendet werden, bekannt als Kosinus-Ähnlichkeit. Sie reicht von -1 bis 1, wobei höhere Werte auf eine stärkere Ähnlichkeit hinweisen. Dieser Ansatz konzentriert sich darauf, wie stark die Vektoren ausgerichtet sind, unabhängig von ihrer Länge, und eignet sich daher ideal zum Vergleich von Wortbedeutungen. Hier eine Illustration:
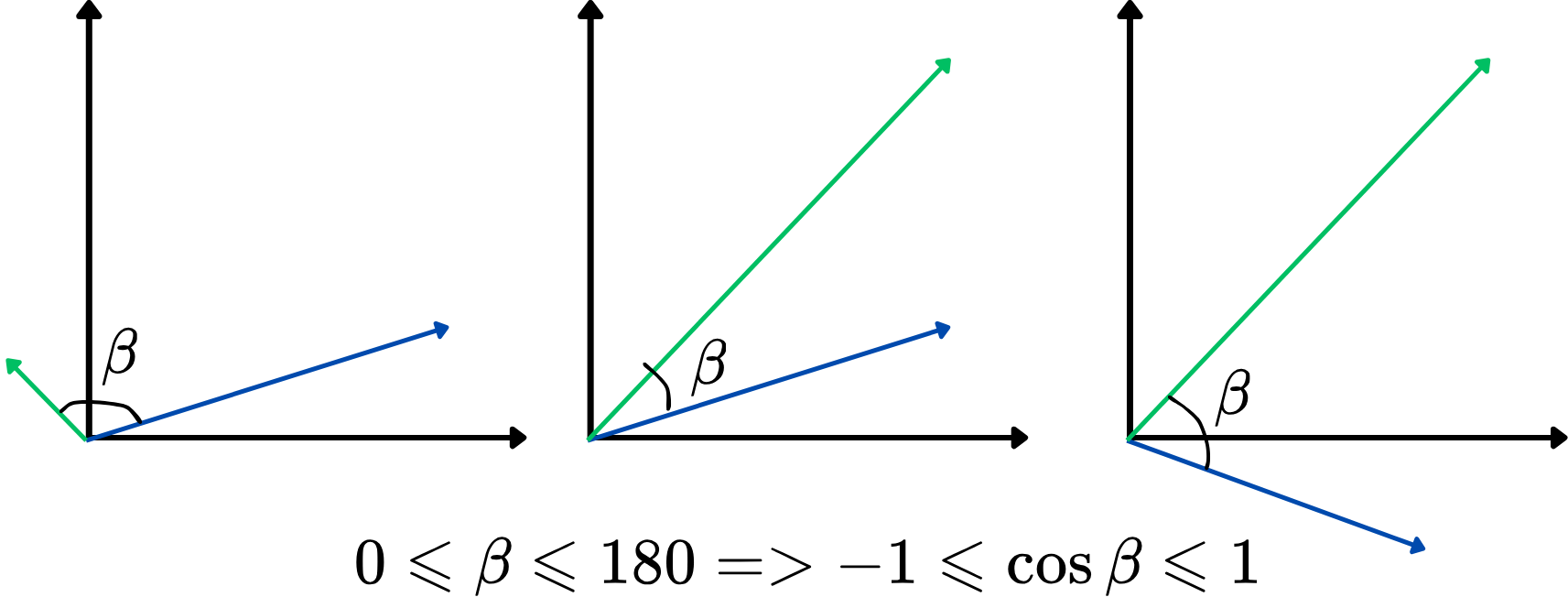
Je höher die Kosinus-Ähnlichkeit, desto ähnlicher sind sich die beiden Vektoren, und umgekehrt. Wenn beispielsweise zwei Wortvektoren eine Kosinus-Ähnlichkeit nahe 1 (der Winkel nahe 0 Grad) aufweisen, deutet dies darauf hin, dass sie im Vektorraum eng miteinander verwandt oder kontextuell ähnlich sind.
Nun ermitteln wir die fünf ähnlichsten Wörter zum Wort "man" mithilfe der Kosinus-Ähnlichkeit:
12345678910from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0) # Retrieve the top-5 most similar words to 'man' similar_words = model.wv.most_similar('man', topn=5) print(similar_words)
model.wv greift auf die Wortvektoren des trainierten Modells zu, während die Methode .most_similar() die Wörter findet, deren Einbettungen der Einbettung des angegebenen Wortes am nächsten sind, basierend auf der Kosinus-Ähnlichkeit. Der Parameter topn bestimmt die Anzahl der Top-N ähnlichen Wörter, die zurückgegeben werden.
Danke für Ihr Feedback!
Fragen Sie AI
Fragen Sie AI

Fragen Sie alles oder probieren Sie eine der vorgeschlagenen Fragen, um unser Gespräch zu beginnen
