Überblick Über Beliebte CNN-Modelle
Swipe um das Menü anzuzeigen
Convolutional Neural Networks (CNNs) haben sich erheblich weiterentwickelt, wobei verschiedene Architekturen die Genauigkeit, Effizienz und Skalierbarkeit verbessert haben. Dieses Kapitel behandelt fünf zentrale CNN-Modelle, die das Deep Learning maßgeblich geprägt haben: LeNet, AlexNet, VGGNet, ResNet und InceptionNet.
LeNet: Die Grundlage der CNNs
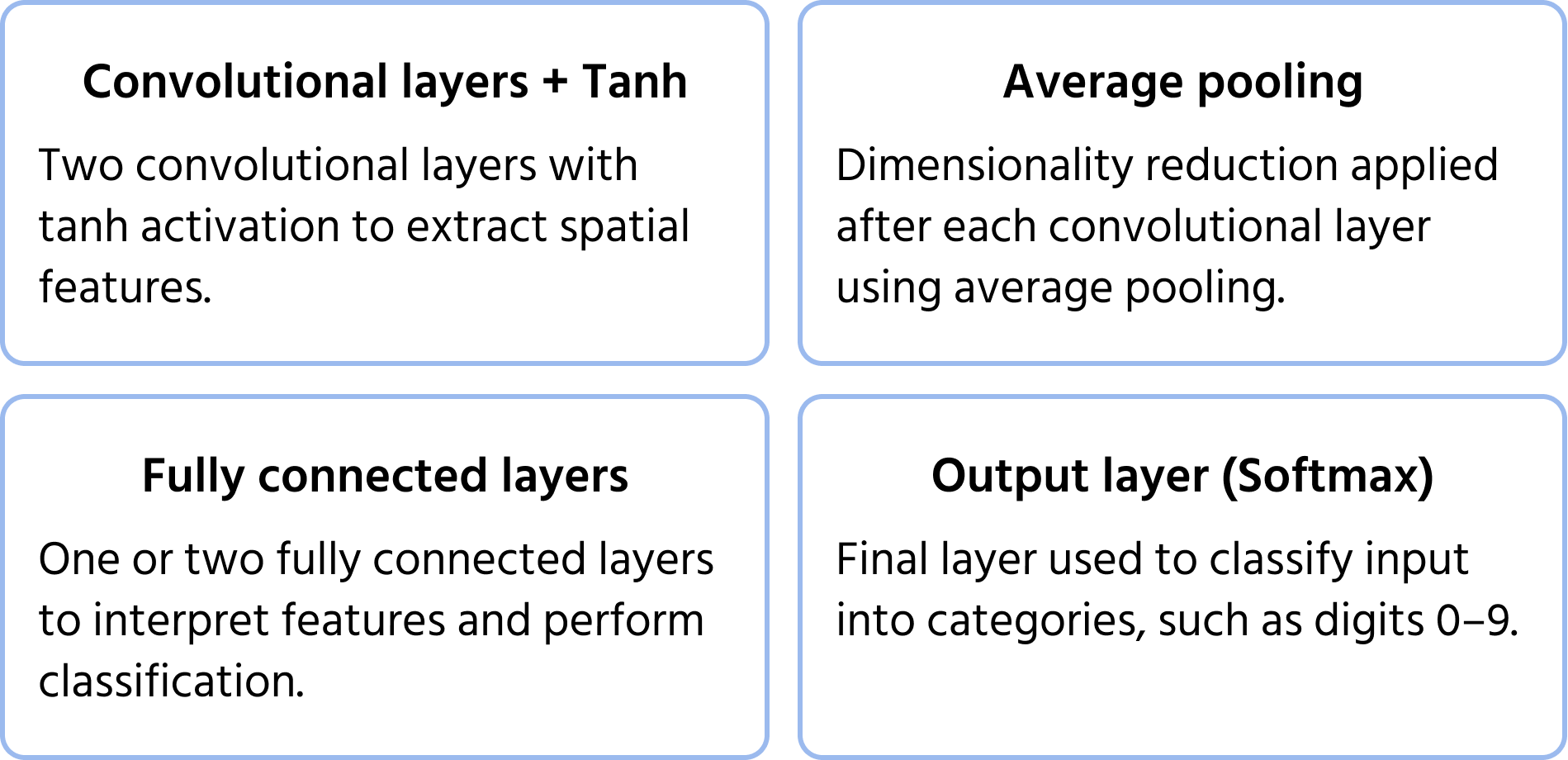
Eine der ersten Architekturen für Convolutional Neural Networks, 1998 von Yann LeCun für die Erkennung handgeschriebener Ziffern vorgeschlagen. Sie legte das Fundament für moderne CNNs durch die Einführung zentraler Komponenten wie Convolutions, Pooling und vollständig verbundener Schichten. Weitere Informationen zum Modell finden Sie in der Dokumentation.
Wichtige Architekturmerkmale
AlexNet: Durchbruch im Deep Learning
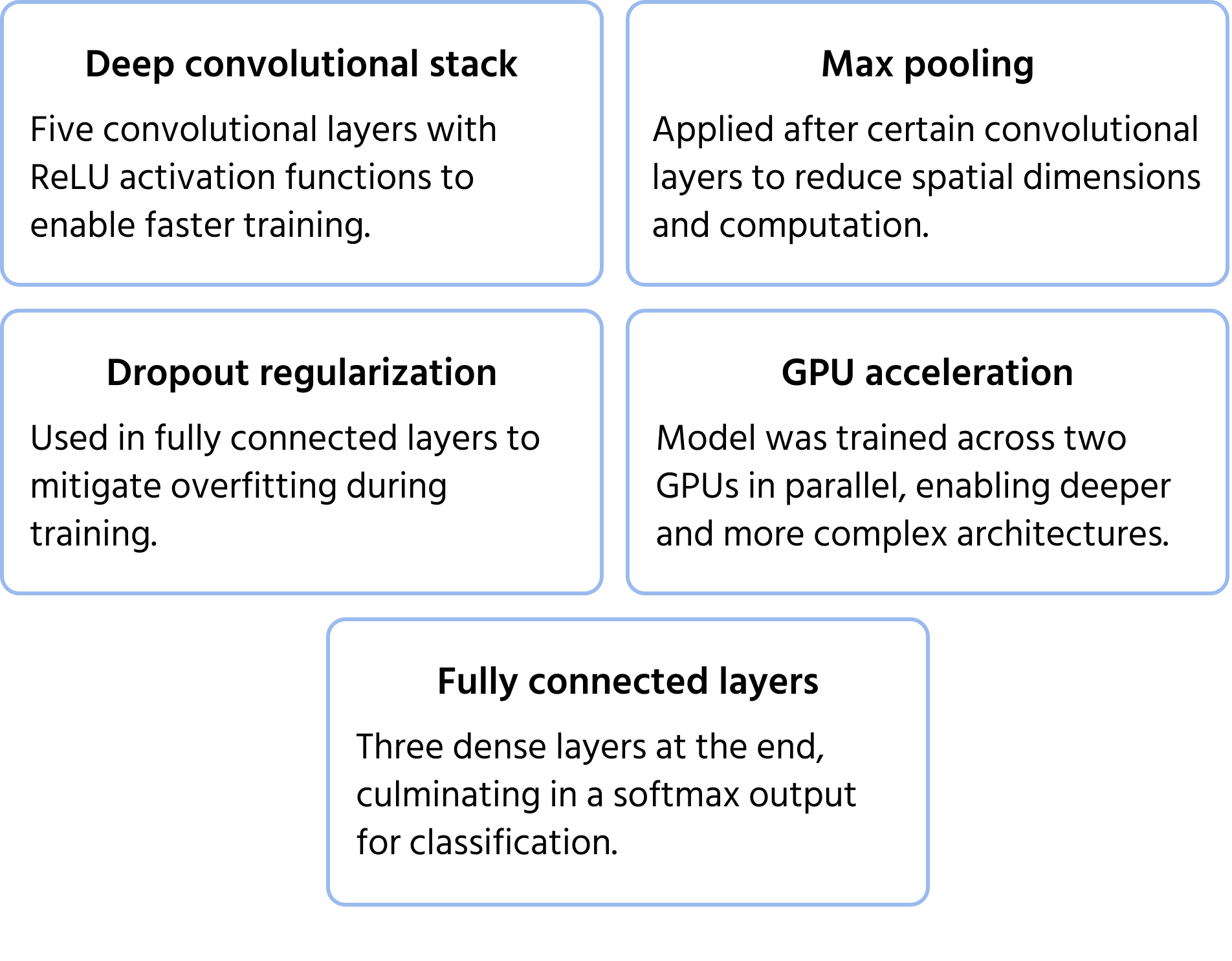
Eine bahnbrechende CNN-Architektur, die den ImageNet-Wettbewerb 2012 gewann. AlexNet zeigte, dass tiefe Convolutional Networks herkömmliche Machine-Learning-Methoden bei der großskaligen Bildklassifikation deutlich übertreffen können. Es führte Innovationen ein, die heute zum Standard im modernen Deep Learning gehören. Weitere Informationen zum Modell finden Sie in der Dokumentation.
Wichtige Architekturmerkmale
VGGNet: Tiefere Netzwerke mit einheitlichen Filtern
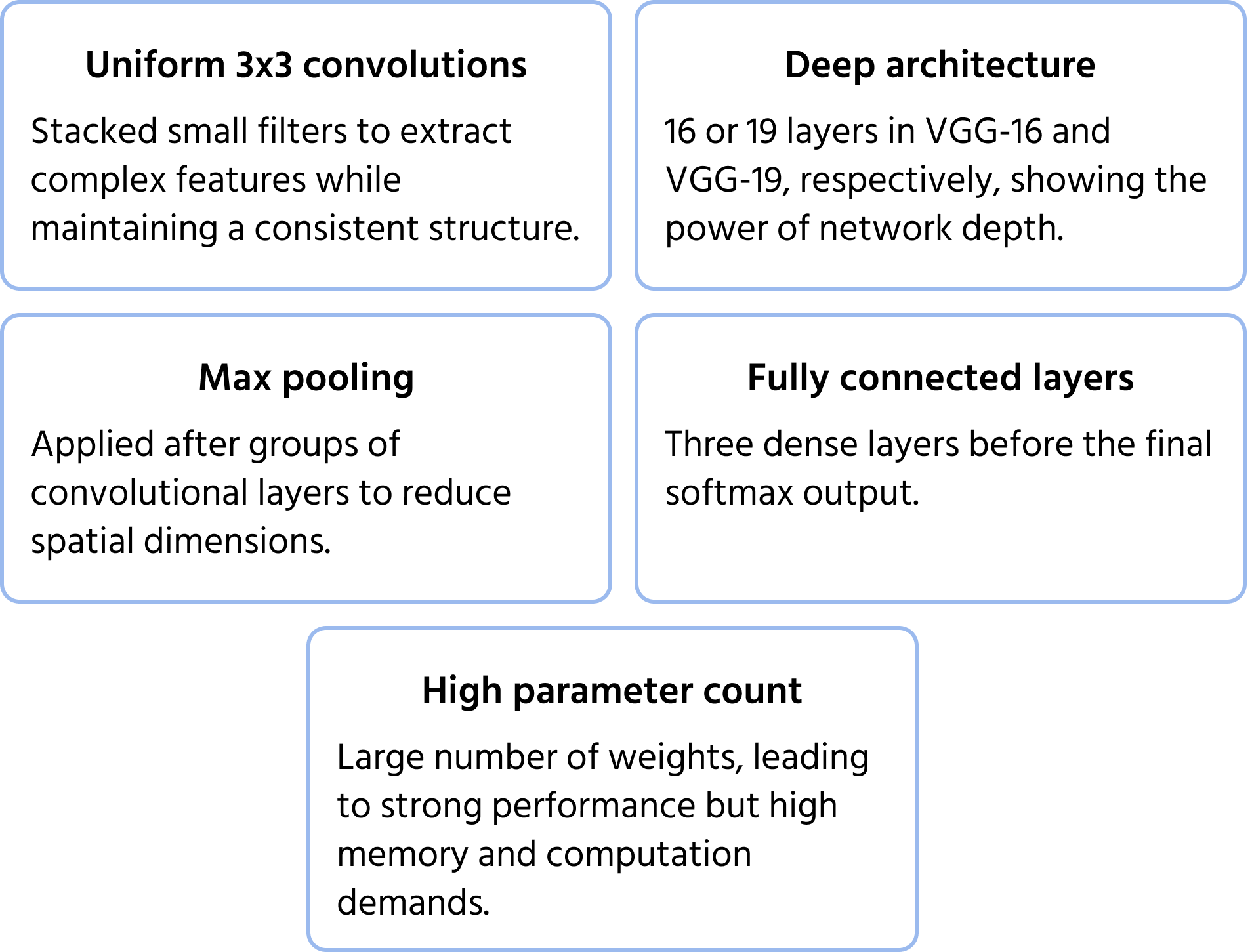
Entwickelt von der Visual Geometry Group in Oxford, betonte VGGNet Tiefe und Einfachheit durch die Verwendung einheitlicher 3×3-Faltungskerne. Es zeigte, dass das Stapeln kleiner Filter in tiefen Netzwerken die Leistung erheblich steigern kann, was zu weit verbreiteten Varianten wie VGG-16 und VGG-19 führte. Weitere Informationen zum Modell finden Sie in der Dokumentation.
Wichtige Architekturmerkmale
ResNet: Lösung des Tiefenproblems
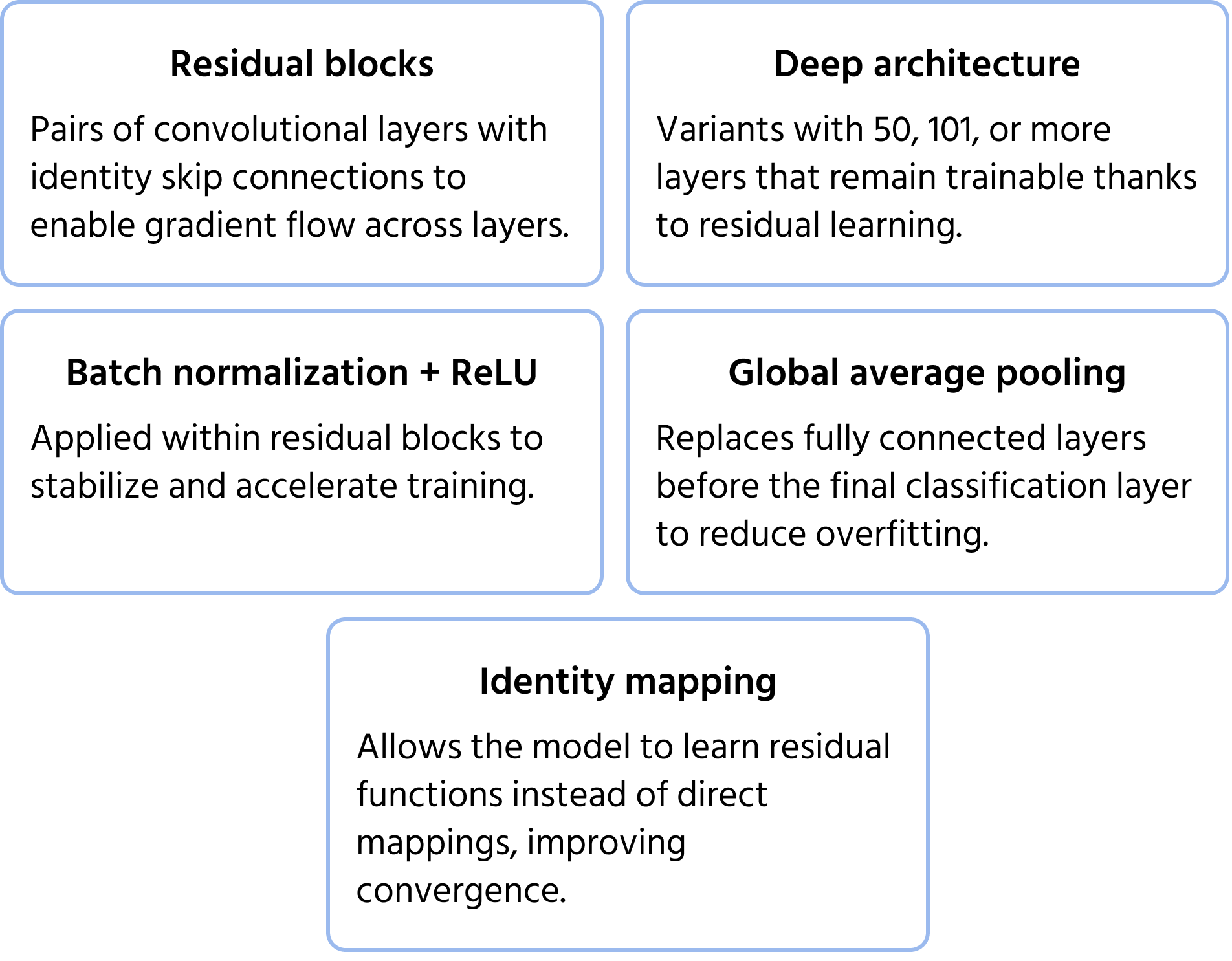
ResNet (Residual Networks), eingeführt von Microsoft im Jahr 2015, adressierte das Problem des verschwindenden Gradienten, das beim Training sehr tiefer Netzwerke auftritt. Traditionelle tiefe Netzwerke haben Schwierigkeiten mit der Trainingseffizienz und Leistungsverschlechterung, aber ResNet überwand dieses Problem durch Skip Connections (residuales Lernen). Diese Abkürzungen ermöglichen es, Informationen bestimmte Schichten zu umgehen, wodurch sichergestellt wird, dass Gradienten effektiv weitergegeben werden. ResNet-Architekturen wie ResNet-50 und ResNet-101 ermöglichten das Training von Netzwerken mit Hunderten von Schichten und verbesserten die Genauigkeit der Bildklassifikation erheblich. Weitere Informationen zum Modell finden Sie in der Dokumentation.
Wichtige Architekturmerkmale
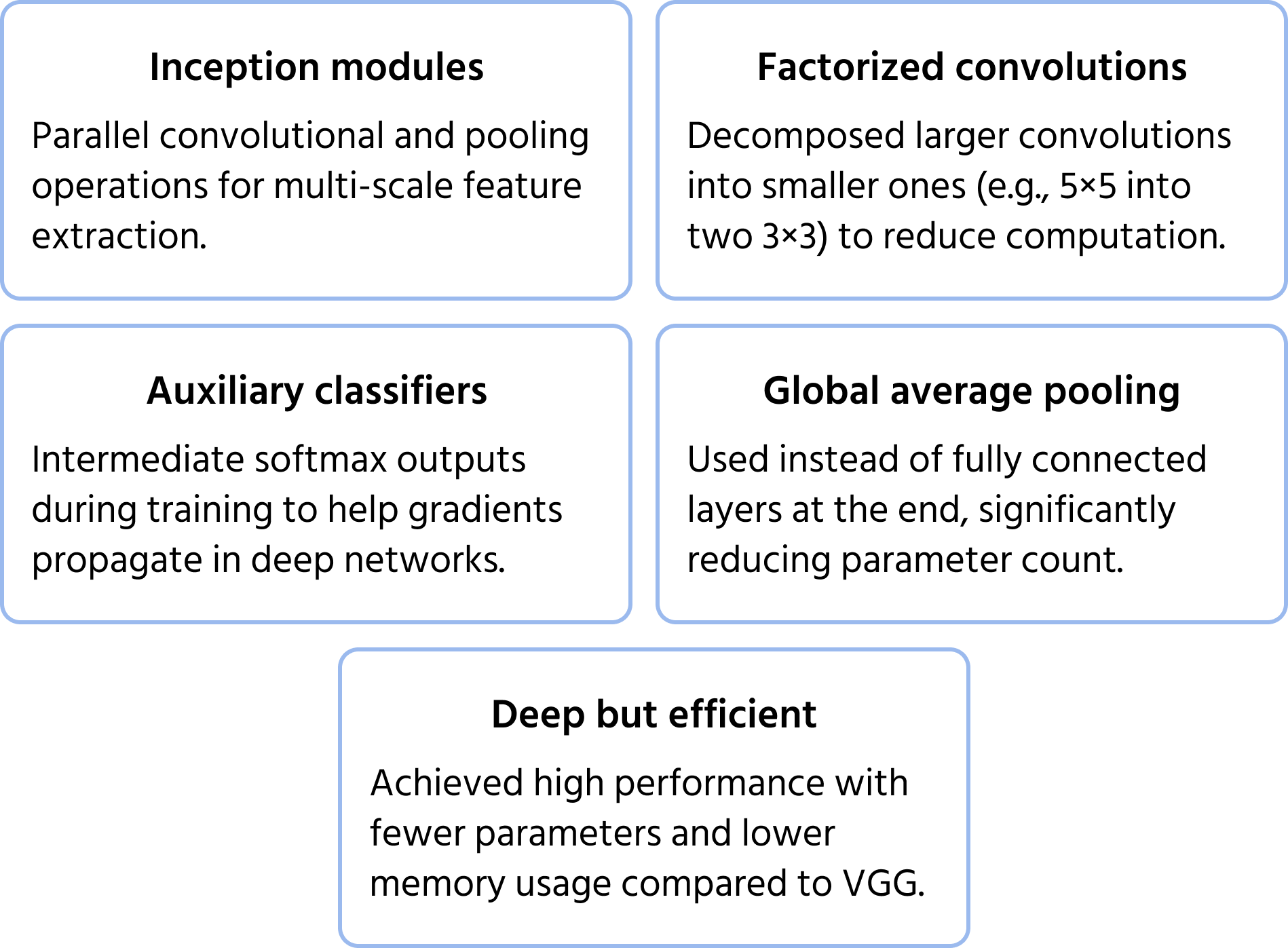
InceptionNet: Multi-Skalen-Merkmalextraktion
InceptionNet (auch bekannt als GoogLeNet) basiert auf dem Inception-Modul und bietet eine tiefe, aber effiziente Architektur. Anstatt Schichten sequenziell zu stapeln, verwendet InceptionNet parallele Pfade, um Merkmale auf verschiedenen Ebenen zu extrahieren. Weitere Informationen zum Modell finden Sie in der Dokumentation.
Wichtige Optimierungen umfassen:
- Faktorisierte Faltungen zur Reduzierung des Rechenaufwands;
- Hilfsklassifikatoren in Zwischenschichten zur Verbesserung der Trainingsstabilität;
- Globales Durchschnittspooling anstelle vollständig verbundener Schichten, wodurch die Anzahl der Parameter reduziert wird, während die Leistung erhalten bleibt.
Diese Struktur ermöglicht es InceptionNet, tiefer als frühere CNNs wie VGG zu sein, ohne die Rechenanforderungen drastisch zu erhöhen.
Wichtige Architekturmerkmale
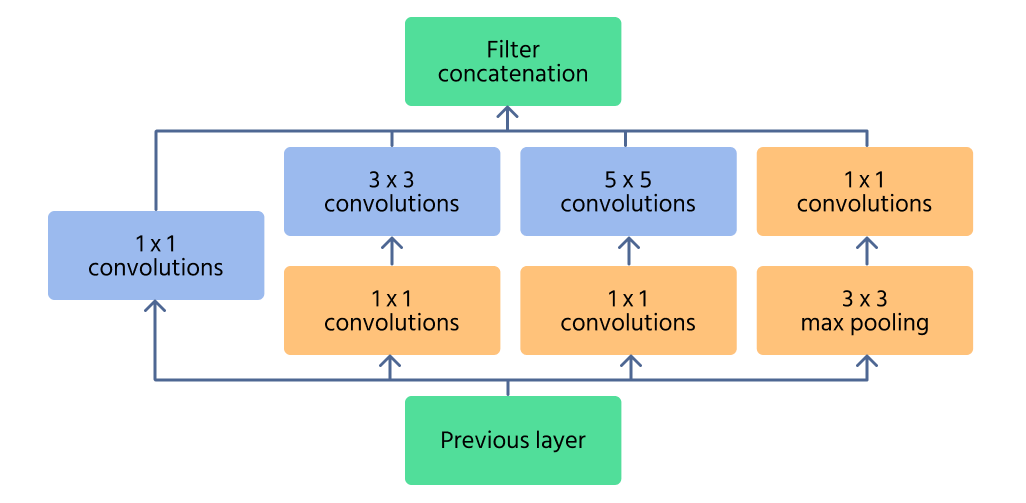
Inception-Modul
Das Inception-Modul ist die zentrale Komponente von InceptionNet und wurde entwickelt, um Merkmale auf mehreren Skalen effizient zu erfassen. Anstatt nur eine einzelne Faltung anzuwenden, verarbeitet das Modul die Eingabe parallel mit mehreren Filtergrößen (1×1, 3×3, 5×5). Dadurch kann das Netzwerk sowohl feine Details als auch große Muster in einem Bild erkennen.
Um die Rechenkosten zu senken, werden 1×1 convolutions vor der Anwendung größerer Filter eingesetzt. Diese reduzieren die Anzahl der Eingangskanäle und machen das Netzwerk effizienter. Zusätzlich helfen Max-Pooling-Schichten innerhalb des Moduls, wesentliche Merkmale zu erhalten und gleichzeitig die Dimensionalität zu kontrollieren.
Beispiel
Betrachten Sie ein Beispiel, um zu veranschaulichen, wie die Reduzierung der Dimensionen die Rechenlast verringert. Angenommen, es sollen 28 × 28 × 192 input feature maps mit 5 × 5 × 32 filters gefaltet werden. Dieser Vorgang würde etwa 120,42 Millionen Berechnungen erfordern.

Number of operations = (2828192) * (5532) = 120,422,400 operations
Führen wir die Berechnungen erneut durch, aber dieses Mal fügen wir eine 1×1 convolutional layer hinzu, bevor wir die 5×5 convolution auf die gleichen Eingabe-Feature-Maps anwenden.

Number of operations for 1x1 convolution = (2828192) * (1116) = 2,408,448 operations
Number of operations for 5x5 convolution = (282816) * (5532) = 10,035,200 operations
Total number of operations 2,408,448 + 10,035,200 = 12,443,648 operations
Jede dieser CNN-Architekturen hat eine entscheidende Rolle bei der Weiterentwicklung der Computer Vision gespielt und Anwendungen in Gesundheitswesen, autonomen Systemen, Sicherheit und Echtzeit-Bildverarbeitung beeinflusst. Von den grundlegenden Prinzipien von LeNet bis zur Multi-Skalen-Merkmalextraktion von InceptionNet haben diese Modelle die Grenzen des Deep Learning kontinuierlich erweitert und den Weg für noch fortschrittlichere Architekturen in der Zukunft geebnet.
1. Was war die wichtigste Innovation, die von ResNet eingeführt wurde und das Training extrem tiefer Netzwerke ermöglichte?
2. Wie verbessert InceptionNet die rechnerische Effizienz im Vergleich zu traditionellen CNNs?
3. Welche CNN-Architektur führte erstmals das Konzept der durchgängigen Verwendung kleiner 3×3-Faltungskerne im gesamten Netzwerk ein?
Danke für Ihr Feedback!
Fragen Sie AI
Fragen Sie AI

Fragen Sie alles oder probieren Sie eine der vorgeschlagenen Fragen, um unser Gespräch zu beginnen
