Aktivierungsfunktionen
Swipe um das Menü anzuzeigen
Warum Aktivierungsfunktionen in CNNs entscheidend sind
Aktivierungsfunktionen führen Nichtlinearität in CNNs ein und ermöglichen es ihnen, komplexe Muster zu erlernen, die über die Fähigkeiten eines einfachen linearen Modells hinausgehen. Ohne Aktivierungsfunktionen hätten CNNs Schwierigkeiten, komplexe Zusammenhänge in den Daten zu erkennen, was ihre Effektivität bei der Bildklassifikation und -erkennung einschränkt. Die Wahl der richtigen Aktivierungsfunktion beeinflusst Trainingsgeschwindigkeit, Stabilität und Gesamtleistung.
Häufig verwendete Aktivierungsfunktionen
- ReLU (Rectified Linear Unit): Die am häufigsten verwendete Aktivierungsfunktion in CNNs. Sie gibt nur positive Werte weiter und setzt alle negativen Eingaben auf Null, was sie recheneffizient macht und das Verschwinden von Gradienten verhindert. Allerdings können einige Neuronen durch das "Dying ReLU"-Problem inaktiv werden;

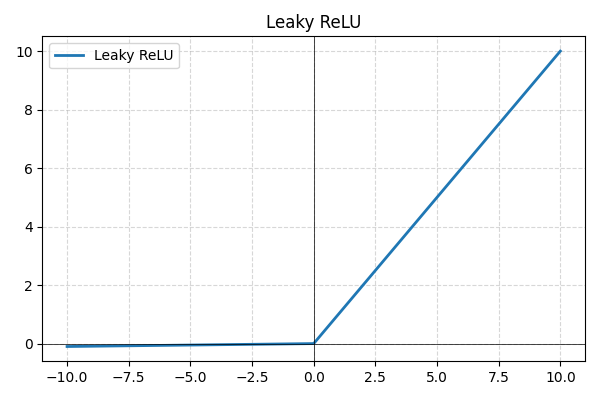
- Leaky ReLU: eine Variante der ReLU, die kleine negative Werte zulässt, anstatt sie auf Null zu setzen, wodurch inaktive Neuronen vermieden und der Gradientenfluss verbessert werden;
- Sigmoid: komprimiert Eingabewerte in einen Bereich zwischen 0 und 1 und ist daher nützlich für binäre Klassifikation. Allerdings tritt bei tiefen Netzwerken das Problem verschwindender Gradienten auf;

- Tanh: ähnlich wie Sigmoid, gibt jedoch Werte zwischen -1 und 1 aus und zentriert die Aktivierungen um Null;

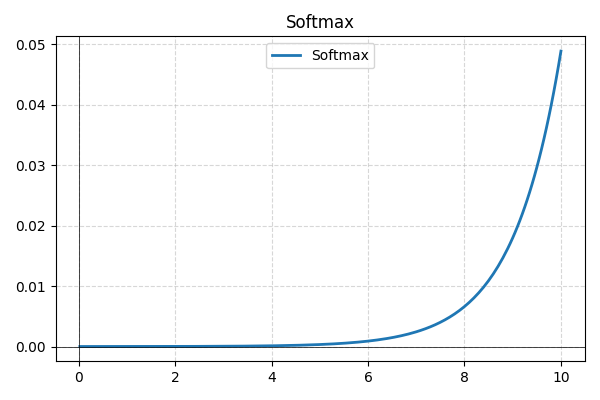
- Softmax: Wird typischerweise in der letzten Schicht für Mehrklassenklassifikation verwendet. Softmax wandelt die Rohwerte des Netzwerks in Wahrscheinlichkeiten um und stellt sicher, dass deren Summe eins ergibt, was die Interpretierbarkeit verbessert.
Auswahl der richtigen Aktivierungsfunktion
ReLU ist aufgrund ihrer Effizienz und starken Leistung die Standardwahl für versteckte Schichten, während Leaky ReLU vorzuziehen ist, wenn das Problem der Inaktivität von Neuronen auftritt. Sigmoid und Tanh werden in tiefen CNNs meist vermieden, können jedoch in bestimmten Anwendungen weiterhin nützlich sein. Softmax bleibt für Aufgaben der Mehrklassenklassifikation unverzichtbar und sorgt für klare, auf Wahrscheinlichkeiten basierende Vorhersagen.
Die Auswahl der passenden Aktivierungsfunktion ist entscheidend für die Optimierung der CNN-Leistung, das Gleichgewicht zwischen Effizienz und die Vermeidung von Problemen wie verschwindenden oder explodierenden Gradienten. Jede Funktion trägt auf einzigartige Weise dazu bei, wie ein Netzwerk visuelle Daten verarbeitet und daraus lernt.
1. Warum wird ReLU in tiefen CNNs gegenüber Sigmoid bevorzugt?
2. Welche Aktivierungsfunktion wird üblicherweise in der letzten Schicht eines Multi-Klassen-Klassifikations-CNN verwendet?
3. Was ist der Hauptvorteil von Leaky ReLU gegenüber dem Standard-ReLU?
Danke für Ihr Feedback!
Fragen Sie AI
Fragen Sie AI

Fragen Sie alles oder probieren Sie eine der vorgeschlagenen Fragen, um unser Gespräch zu beginnen
