Überblick Über Die Bildgenerierung
Swipe um das Menü anzuzeigen
KI-generierte Bilder verändern die Art und Weise, wie Kunst, Design und digitale Inhalte erstellt werden. Mithilfe künstlicher Intelligenz können Computer heute realistische Bilder erzeugen, kreative Arbeiten verbessern und sogar Unternehmen unterstützen. In diesem Kapitel werden die Funktionsweise der KI-Bilderstellung, verschiedene Arten von Bildgenerierungsmodellen und deren praktische Anwendungen behandelt.
Wie KI Bilder erstellt
Die KI-Bilderzeugung funktioniert, indem sie aus einer riesigen Sammlung von Bildern lernt. Die KI analysiert Muster in den Bildern und erstellt anschließend neue, die ähnlich aussehen. Diese Technologie hat sich im Laufe der Jahre stark weiterentwickelt und ermöglicht heute realistischere und kreativere Bilder. Sie findet Anwendung in Videospielen, Filmen, Werbung und sogar in der Modebranche.
Frühe Methoden: PixelRNN und PixelCNN
Vor den heutigen fortschrittlichen KI-Modellen entwickelten Forscher frühe Methoden zur Bildgenerierung wie PixelRNN und PixelCNN. Diese Modelle erzeugten Bilder, indem sie jeweils ein Pixel vorhersagten.
- PixelRNN: verwendet ein System namens rekurrentes neuronales Netzwerk (RNN), um die Farben der Pixel nacheinander vorherzusagen. Obwohl es gut funktionierte, war es sehr langsam;
- PixelCNN: verbesserte PixelRNN durch die Nutzung eines anderen Netzwerks, sogenannter Faltungsschichten, wodurch die Bilderzeugung schneller wurde.
Obwohl diese Modelle einen guten Anfang darstellten, waren sie nicht in der Lage, hochwertige Bilder zu erzeugen. Dies führte zur Entwicklung besserer Techniken.
Autoregressive Modelle
Autoregressive Modelle erzeugen Bilder ebenfalls Pixel für Pixel, wobei sie vergangene Pixel nutzen, um vorherzusagen, was als Nächstes kommt. Diese Modelle waren nützlich, aber langsam, was sie im Laufe der Zeit weniger beliebt machte. Dennoch inspirierten sie neuere, schnellere Modelle.
Wie KI Text für die Bilderzeugung versteht
Einige KI-Modelle können geschriebene Wörter in Bilder umwandeln. Diese Modelle verwenden Large Language Models (LLMs), um Beschreibungen zu verstehen und passende Bilder zu erzeugen. Wenn beispielsweise „a cat sitting on a beach at sunset“ eingegeben wird, erstellt die KI ein Bild basierend auf dieser Beschreibung.
KI-Modelle wie OpenAIs DALL-E und Googles Imagen nutzen fortschrittliches Sprachverständnis, um die Übereinstimmung zwischen Textbeschreibungen und den generierten Bildern zu verbessern. Dies wird durch Natural Language Processing (NLP) ermöglicht, das es der KI erlaubt, Wörter in Zahlen umzuwandeln, die die Bilderzeugung steuern.
Generative Adversarial Networks (GANs)
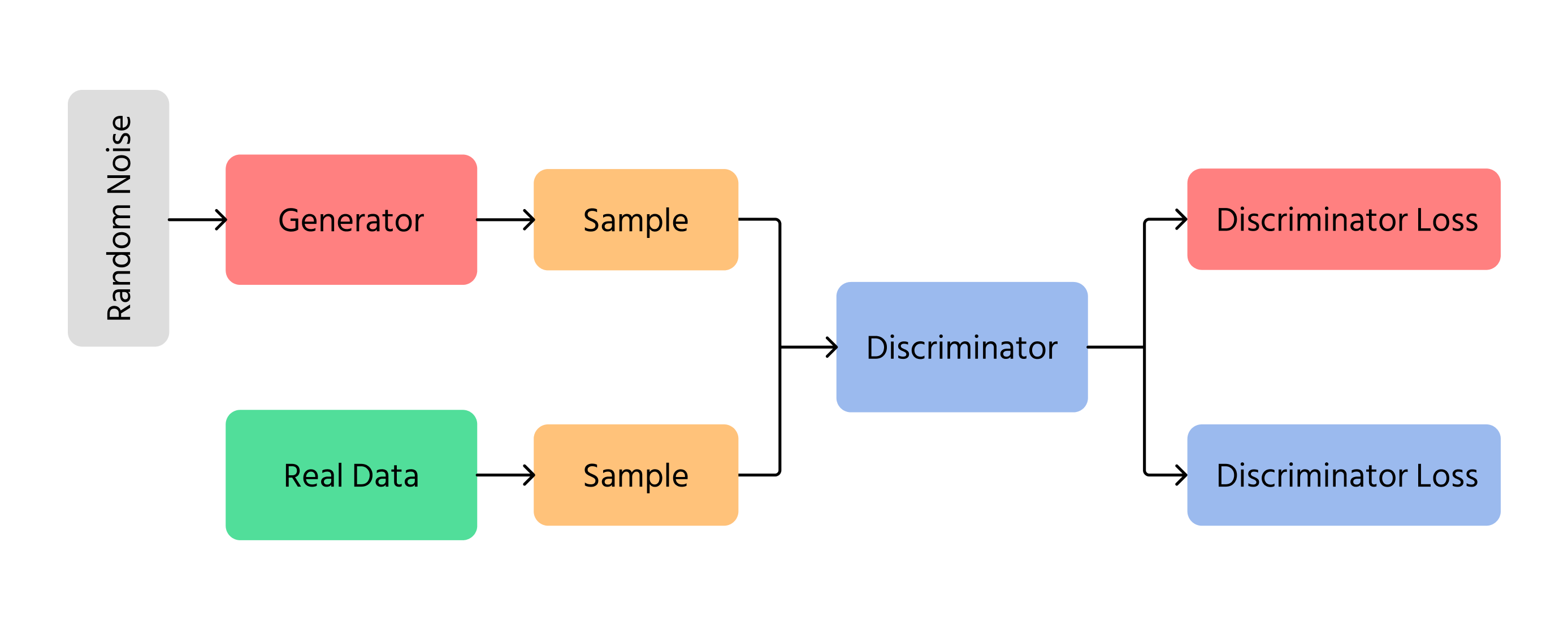
Einen der wichtigsten Durchbrüche bei der KI-Bilderzeugung stellten Generative Adversarial Networks (GANs) dar. GANs arbeiten mit zwei verschiedenen neuronalen Netzwerken:
- Generator: erzeugt neue Bilder aus dem Nichts;
- Discriminator: prüft, ob die Bilder echt oder gefälscht sind.
Der Generator versucht, Bilder so realistisch zu machen, dass der Discriminator nicht erkennen kann, dass sie gefälscht sind. Mit der Zeit werden die Bilder besser und sehen echten Fotografien immer ähnlicher. GANs werden in Deepfake-Technologien, der Erstellung von Kunstwerken und zur Verbesserung der Bildqualität eingesetzt.
Variationale Autoencoder (VAEs)
VAEs sind eine weitere Methode, mit der KI Bilder generieren kann. Anstatt wie GANs auf Wettbewerb zu setzen, kodieren und dekodieren VAEs Bilder mithilfe von Wahrscheinlichkeiten. Sie lernen die zugrunde liegenden Muster eines Bildes und rekonstruieren es anschließend mit leichten Variationen. Das probabilistische Element in VAEs sorgt dafür, dass jedes generierte Bild leicht unterschiedlich ist, was Vielfalt und Kreativität ermöglicht.
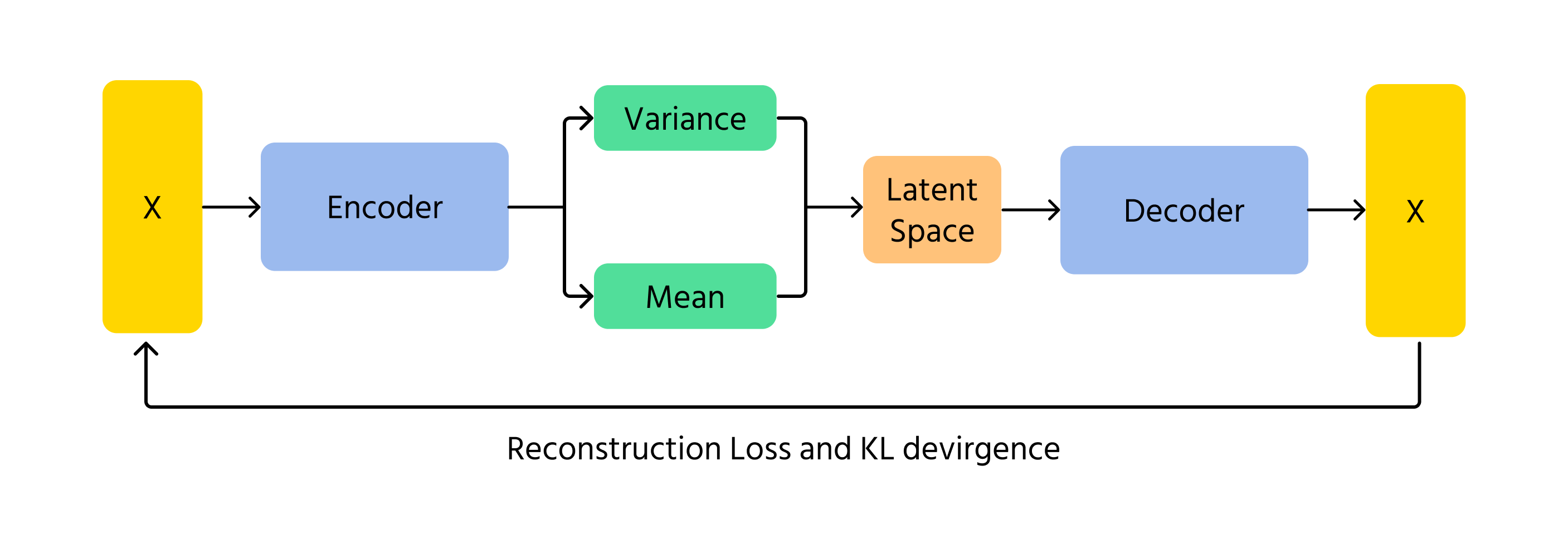
Ein zentrales Konzept bei VAEs ist die Kullback-Leibler (KL) Divergenz, die den Unterschied zwischen der gelernten Verteilung und einer Standard-Normalverteilung misst. Durch die Minimierung der KL-Divergenz stellen VAEs sicher, dass generierte Bilder realistisch bleiben und dennoch kreative Variationen ermöglichen.
Funktionsweise von VAEs
- Kodierung: Die Eingabedaten x werden in den Encoder eingespeist, der die Parameter der latenten Raumverteilung q(z∣x) (Mittelwert μ und Varianz σ²) ausgibt;
- Sampling im latenten Raum: Latente Variablen z werden aus der Verteilung q(z∣x) mithilfe von Techniken wie dem Reparametrisierungstrick gezogen;
- Dekodierung & Rekonstruktion: Das gesampelte z wird durch den Decoder geleitet, um die rekonstruierten Daten x̂ zu erzeugen, die dem ursprünglichen Input x ähneln sollten.
VAEs sind nützlich für Aufgaben wie das Rekonstruieren von Gesichtern, das Generieren neuer Versionen bestehender Bilder und das Erzeugen fließender Übergänge zwischen verschiedenen Bildern.
Diffusionsmodelle
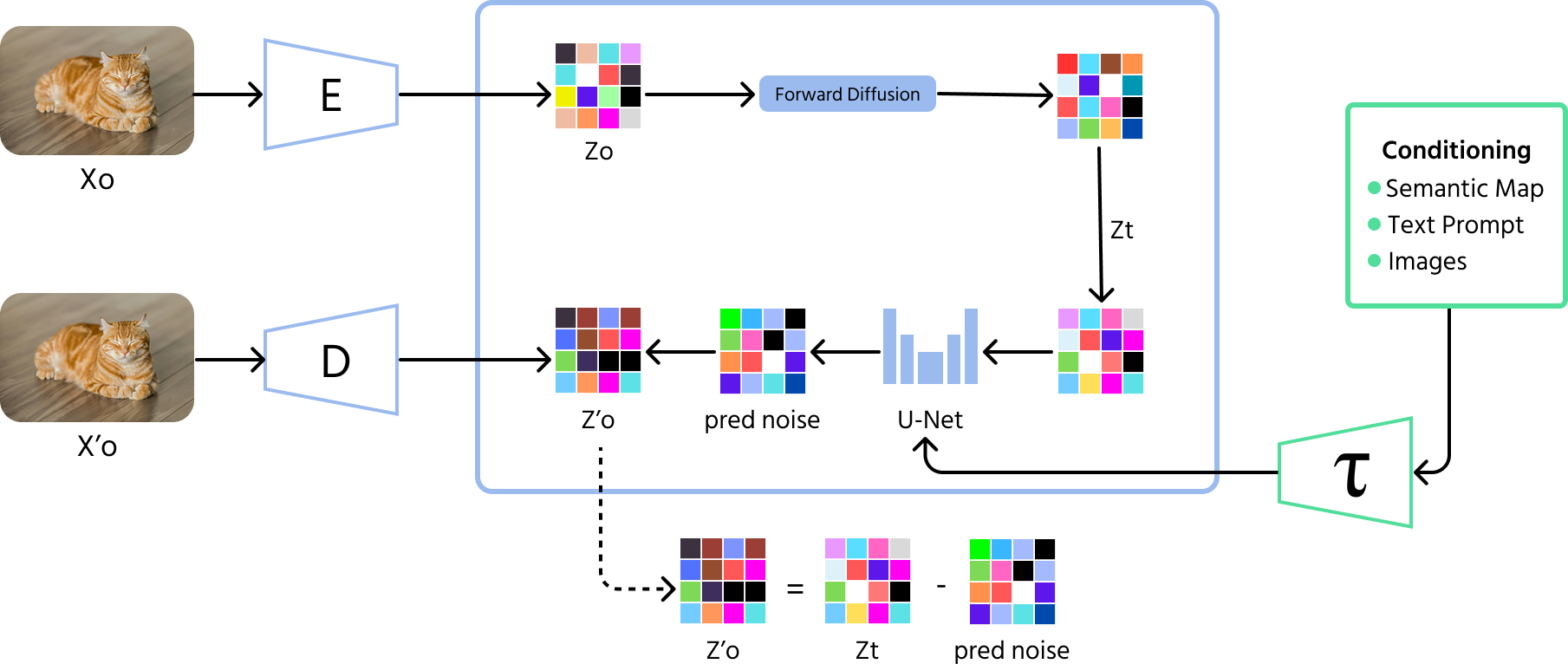
Diffusionsmodelle sind der neueste Durchbruch bei KI-generierten Bildern. Diese Modelle beginnen mit zufälligem Rauschen und verbessern das Bild schrittweise, ähnlich wie das Entfernen von Störungen aus einem verschwommenen Foto. Im Gegensatz zu GANs, die manchmal nur begrenzte Variationen erzeugen, können Diffusionsmodelle eine größere Bandbreite an hochwertigen Bildern produzieren.
Funktionsweise von Diffusionsmodellen
- Vorwärtsprozess (Rauschzugabe): Das Modell beginnt damit, einem Bild über viele Schritte hinweg zufälliges Rauschen hinzuzufügen, bis es völlig unkenntlich wird;
- Rückwärtsprozess (Entrauschen): Anschließend lernt das Modell, diesen Prozess umzukehren, indem es das Rauschen schrittweise entfernt, um ein sinnvolles Bild wiederherzustellen;
- Training: Diffusionsmodelle werden darauf trainiert, das Rauschen in jedem Schritt vorherzusagen und zu entfernen, wodurch sie in der Lage sind, aus zufälligem Rauschen klare und hochwertige Bilder zu erzeugen.
Ein bekanntes Beispiel sind MidJourney, DALL-E und Stable Diffusion, die für die Erstellung realistischer und künstlerischer Bilder bekannt sind. Diffusionsmodelle werden häufig für KI-generierte Kunst, hochauflösende Bildsynthese und kreative Designanwendungen eingesetzt.
Beispiele für von Diffusionsmodellen erzeugte Bilder

Realistisches Bild eines Basketballspielers mit Bart in einer gelb-violetten Uniform, der einen Dunk ausführt und Dämonen in einem Basketballspiel besiegt; die gesamte Aktion findet in der Hölle statt.

Ein surrealistisch schönes, künstlerisches Foto eines weißen Volkswagen Golf GTI von 1990 in einem endlosen Feld weißer Blumen, in Harmonie mit der Natur, inmitten endloser, blumenbedeckter Hügel, botanisch, natürliches Licht, künstlerisch, neblig, fotorealistisch, surrealistisch, ultradetailliert, Kodak-Film, natürliches Licht, Weitwinkelobjektiv, f 1.20

Gemälde eines beigen Pudels, der auf einem grünen Sofa mit grün-weiß gestreiftem Kissen liegt, im Stil von Fairfield Porter, abstrakter Expressionismus, mit kräftigen Pinselstrichen auf beigem Hintergrund

Extreme Nahaufnahme der Haut einer mediterranen oder lateinamerikanischen Frau, die einen Mischhauttyp mit sichtbarer Ölglanzbildung auf Stirn und Nase hervorhebt, während die Wangen trockener und leicht schuppig erscheinen. Die Poren sind in der T-Zone deutlicher sichtbar, und ein natürlicher Glanz spiegelt die Talgproduktion wider. Die Haut weist eine Mischung aus warmen und goldenen Untertönen auf, mit einer ungleichmäßigen Textur aufgrund unterschiedlicher Feuchtigkeitsniveaus. Weiches, natürliches Licht betont den realistischen Kontrast zwischen den trockenen und öligen Bereichen. Der Hintergrund ist unscharf, sodass der Fokus auf dem Teint liegt.
Herausforderungen und ethische Bedenken
Auch wenn KI-generierte Bilder beeindruckend sind, gibt es Herausforderungen:
- Mangelnde Kontrolle: KI erzeugt möglicherweise nicht immer genau das, was der Nutzer erwartet;
- Rechenleistung: Die Erstellung hochwertiger KI-Bilder erfordert teure und leistungsstarke Computer;
- Voreingenommenheit in KI-Modellen: Da KI aus bestehenden Bildern lernt, kann sie manchmal Vorurteile aus den Daten wiederholen.
Es gibt auch ethische Bedenken:
- Wem gehört KI-Kunst?: Wenn eine KI ein Kunstwerk erschafft, gehört es dann der Person, die die KI genutzt hat, oder dem KI-Unternehmen?
- Gefälschte Bilder und Deepfakes: GANs können verwendet werden, um gefälschte Bilder zu erstellen, die echt aussehen, was zu Fehlinformationen und Datenschutzproblemen führen kann.
Aktuelle Anwendungsbereiche der KI-Bilderzeugung
KI-generierte Bilder haben bereits großen Einfluss auf verschiedene Branchen:
- Unterhaltung: Videospiele, Filme und Animationen nutzen KI zur Erstellung von Hintergründen, Charakteren und Effekten;
- Mode: Designer verwenden KI, um neue Kleidungsstile zu entwerfen, und Online-Shops bieten virtuelle Anproben für Kunden an;
- Grafikdesign: KI unterstützt Künstler und Designer bei der schnellen Erstellung von Logos, Postern und Werbematerialien.
Die Zukunft der KI-Bilderzeugung
Mit der fortschreitenden Entwicklung der KI-Bilderzeugung verändert sich weiterhin die Art und Weise, wie Menschen Bilder erstellen und nutzen. Ob in Kunst, Wirtschaft oder Unterhaltung – KI eröffnet neue Möglichkeiten und erleichtert kreative Arbeit, macht sie effizienter und spannender.
1. Was ist der Hauptzweck der KI-Bilderzeugung?
2. Wie funktionieren Generative Adversarial Networks (GANs)?
3. Welches KI-Modell beginnt mit zufälligem Rauschen und verbessert das Bild Schritt für Schritt?
Danke für Ihr Feedback!
Fragen Sie AI
Fragen Sie AI

Fragen Sie alles oder probieren Sie eine der vorgeschlagenen Fragen, um unser Gespräch zu beginnen
Überblick Über Die Bildgenerierung
KI-generierte Bilder verändern die Art und Weise, wie Kunst, Design und digitale Inhalte erstellt werden. Mithilfe künstlicher Intelligenz können Computer heute realistische Bilder erzeugen, kreative Arbeiten verbessern und sogar Unternehmen unterstützen. In diesem Kapitel werden die Funktionsweise der KI-Bilderstellung, verschiedene Arten von Bildgenerierungsmodellen und deren praktische Anwendungen behandelt.
Wie KI Bilder erstellt
Die KI-Bilderzeugung funktioniert, indem sie aus einer riesigen Sammlung von Bildern lernt. Die KI analysiert Muster in den Bildern und erstellt anschließend neue, die ähnlich aussehen. Diese Technologie hat sich im Laufe der Jahre stark weiterentwickelt und ermöglicht heute realistischere und kreativere Bilder. Sie findet Anwendung in Videospielen, Filmen, Werbung und sogar in der Modebranche.
Frühe Methoden: PixelRNN und PixelCNN
Vor den heutigen fortschrittlichen KI-Modellen entwickelten Forscher frühe Methoden zur Bildgenerierung wie PixelRNN und PixelCNN. Diese Modelle erzeugten Bilder, indem sie jeweils ein Pixel vorhersagten.
- PixelRNN: verwendet ein System namens rekurrentes neuronales Netzwerk (RNN), um die Farben der Pixel nacheinander vorherzusagen. Obwohl es gut funktionierte, war es sehr langsam;
- PixelCNN: verbesserte PixelRNN durch die Nutzung eines anderen Netzwerks, sogenannter Faltungsschichten, wodurch die Bilderzeugung schneller wurde.
Obwohl diese Modelle einen guten Anfang darstellten, waren sie nicht in der Lage, hochwertige Bilder zu erzeugen. Dies führte zur Entwicklung besserer Techniken.
Autoregressive Modelle
Autoregressive Modelle erzeugen Bilder ebenfalls Pixel für Pixel, wobei sie vergangene Pixel nutzen, um vorherzusagen, was als Nächstes kommt. Diese Modelle waren nützlich, aber langsam, was sie im Laufe der Zeit weniger beliebt machte. Dennoch inspirierten sie neuere, schnellere Modelle.
Wie KI Text für die Bilderzeugung versteht
Einige KI-Modelle können geschriebene Wörter in Bilder umwandeln. Diese Modelle verwenden Large Language Models (LLMs), um Beschreibungen zu verstehen und passende Bilder zu erzeugen. Wenn beispielsweise „a cat sitting on a beach at sunset“ eingegeben wird, erstellt die KI ein Bild basierend auf dieser Beschreibung.
KI-Modelle wie OpenAIs DALL-E und Googles Imagen nutzen fortschrittliches Sprachverständnis, um die Übereinstimmung zwischen Textbeschreibungen und den generierten Bildern zu verbessern. Dies wird durch Natural Language Processing (NLP) ermöglicht, das es der KI erlaubt, Wörter in Zahlen umzuwandeln, die die Bilderzeugung steuern.
Generative Adversarial Networks (GANs)
Einen der wichtigsten Durchbrüche bei der KI-Bilderzeugung stellten Generative Adversarial Networks (GANs) dar. GANs arbeiten mit zwei verschiedenen neuronalen Netzwerken:
- Generator: erzeugt neue Bilder aus dem Nichts;
- Discriminator: prüft, ob die Bilder echt oder gefälscht sind.
Der Generator versucht, Bilder so realistisch zu machen, dass der Discriminator nicht erkennen kann, dass sie gefälscht sind. Mit der Zeit werden die Bilder besser und sehen echten Fotografien immer ähnlicher. GANs werden in Deepfake-Technologien, der Erstellung von Kunstwerken und zur Verbesserung der Bildqualität eingesetzt.
Variationale Autoencoder (VAEs)
VAEs sind eine weitere Methode, mit der KI Bilder generieren kann. Anstatt wie GANs auf Wettbewerb zu setzen, kodieren und dekodieren VAEs Bilder mithilfe von Wahrscheinlichkeiten. Sie lernen die zugrunde liegenden Muster eines Bildes und rekonstruieren es anschließend mit leichten Variationen. Das probabilistische Element in VAEs sorgt dafür, dass jedes generierte Bild leicht unterschiedlich ist, was Vielfalt und Kreativität ermöglicht.
Ein zentrales Konzept bei VAEs ist die Kullback-Leibler (KL) Divergenz, die den Unterschied zwischen der gelernten Verteilung und einer Standard-Normalverteilung misst. Durch die Minimierung der KL-Divergenz stellen VAEs sicher, dass generierte Bilder realistisch bleiben und dennoch kreative Variationen ermöglichen.
Funktionsweise von VAEs
- Kodierung: Die Eingabedaten x werden in den Encoder eingespeist, der die Parameter der latenten Raumverteilung q(z∣x) (Mittelwert μ und Varianz σ²) ausgibt;
- Sampling im latenten Raum: Latente Variablen z werden aus der Verteilung q(z∣x) mithilfe von Techniken wie dem Reparametrisierungstrick gezogen;
- Dekodierung & Rekonstruktion: Das gesampelte z wird durch den Decoder geleitet, um die rekonstruierten Daten x̂ zu erzeugen, die dem ursprünglichen Input x ähneln sollten.
VAEs sind nützlich für Aufgaben wie das Rekonstruieren von Gesichtern, das Generieren neuer Versionen bestehender Bilder und das Erzeugen fließender Übergänge zwischen verschiedenen Bildern.
Diffusionsmodelle
Diffusionsmodelle sind der neueste Durchbruch bei KI-generierten Bildern. Diese Modelle beginnen mit zufälligem Rauschen und verbessern das Bild schrittweise, ähnlich wie das Entfernen von Störungen aus einem verschwommenen Foto. Im Gegensatz zu GANs, die manchmal nur begrenzte Variationen erzeugen, können Diffusionsmodelle eine größere Bandbreite an hochwertigen Bildern produzieren.
Funktionsweise von Diffusionsmodellen
- Vorwärtsprozess (Rauschzugabe): Das Modell beginnt damit, einem Bild über viele Schritte hinweg zufälliges Rauschen hinzuzufügen, bis es völlig unkenntlich wird;
- Rückwärtsprozess (Entrauschen): Anschließend lernt das Modell, diesen Prozess umzukehren, indem es das Rauschen schrittweise entfernt, um ein sinnvolles Bild wiederherzustellen;
- Training: Diffusionsmodelle werden darauf trainiert, das Rauschen in jedem Schritt vorherzusagen und zu entfernen, wodurch sie in der Lage sind, aus zufälligem Rauschen klare und hochwertige Bilder zu erzeugen.
Ein bekanntes Beispiel sind MidJourney, DALL-E und Stable Diffusion, die für die Erstellung realistischer und künstlerischer Bilder bekannt sind. Diffusionsmodelle werden häufig für KI-generierte Kunst, hochauflösende Bildsynthese und kreative Designanwendungen eingesetzt.
Beispiele für von Diffusionsmodellen erzeugte Bilder
Realistisches Bild eines Basketballspielers mit Bart in einer gelb-violetten Uniform, der einen Dunk ausführt und Dämonen in einem Basketballspiel besiegt; die gesamte Aktion findet in der Hölle statt.
Ein surrealistisch schönes, künstlerisches Foto eines weißen Volkswagen Golf GTI von 1990 in einem endlosen Feld weißer Blumen, in Harmonie mit der Natur, inmitten endloser, blumenbedeckter Hügel, botanisch, natürliches Licht, künstlerisch, neblig, fotorealistisch, surrealistisch, ultradetailliert, Kodak-Film, natürliches Licht, Weitwinkelobjektiv, f 1.20
Gemälde eines beigen Pudels, der auf einem grünen Sofa mit grün-weiß gestreiftem Kissen liegt, im Stil von Fairfield Porter, abstrakter Expressionismus, mit kräftigen Pinselstrichen auf beigem Hintergrund
Extreme Nahaufnahme der Haut einer mediterranen oder lateinamerikanischen Frau, die einen Mischhauttyp mit sichtbarer Ölglanzbildung auf Stirn und Nase hervorhebt, während die Wangen trockener und leicht schuppig erscheinen. Die Poren sind in der T-Zone deutlicher sichtbar, und ein natürlicher Glanz spiegelt die Talgproduktion wider. Die Haut weist eine Mischung aus warmen und goldenen Untertönen auf, mit einer ungleichmäßigen Textur aufgrund unterschiedlicher Feuchtigkeitsniveaus. Weiches, natürliches Licht betont den realistischen Kontrast zwischen den trockenen und öligen Bereichen. Der Hintergrund ist unscharf, sodass der Fokus auf dem Teint liegt.
Herausforderungen und ethische Bedenken
Auch wenn KI-generierte Bilder beeindruckend sind, gibt es Herausforderungen:
- Mangelnde Kontrolle: KI erzeugt möglicherweise nicht immer genau das, was der Nutzer erwartet;
- Rechenleistung: Die Erstellung hochwertiger KI-Bilder erfordert teure und leistungsstarke Computer;
- Voreingenommenheit in KI-Modellen: Da KI aus bestehenden Bildern lernt, kann sie manchmal Vorurteile aus den Daten wiederholen.
Es gibt auch ethische Bedenken:
- Wem gehört KI-Kunst?: Wenn eine KI ein Kunstwerk erschafft, gehört es dann der Person, die die KI genutzt hat, oder dem KI-Unternehmen?
- Gefälschte Bilder und Deepfakes: GANs können verwendet werden, um gefälschte Bilder zu erstellen, die echt aussehen, was zu Fehlinformationen und Datenschutzproblemen führen kann.
Aktuelle Anwendungsbereiche der KI-Bilderzeugung
KI-generierte Bilder haben bereits großen Einfluss auf verschiedene Branchen:
- Unterhaltung: Videospiele, Filme und Animationen nutzen KI zur Erstellung von Hintergründen, Charakteren und Effekten;
- Mode: Designer verwenden KI, um neue Kleidungsstile zu entwerfen, und Online-Shops bieten virtuelle Anproben für Kunden an;
- Grafikdesign: KI unterstützt Künstler und Designer bei der schnellen Erstellung von Logos, Postern und Werbematerialien.
Die Zukunft der KI-Bilderzeugung
Mit der fortschreitenden Entwicklung der KI-Bilderzeugung verändert sich weiterhin die Art und Weise, wie Menschen Bilder erstellen und nutzen. Ob in Kunst, Wirtschaft oder Unterhaltung – KI eröffnet neue Möglichkeiten und erleichtert kreative Arbeit, macht sie effizienter und spannender.
Danke für Ihr Feedback!
