Transfer Learning in Computer Vision
Swipe um das Menü anzuzeigen
Transfer Learning ermöglicht die Wiederverwendung von auf großen Datensätzen trainierten Modellen für neue Aufgaben mit begrenzten Daten. Anstatt ein neuronales Netzwerk von Grund auf neu zu erstellen, nutzen wir vortrainierte Modelle, um Effizienz und Leistung zu steigern. Im Verlauf dieses Kurses sind Ihnen bereits ähnliche Ansätze in vorherigen Abschnitten begegnet, die die Grundlage für den effektiven Einsatz von Transfer Learning geschaffen haben.
Was ist Transfer Learning?
Transfer Learning ist eine Technik, bei der ein auf eine Aufgabe trainiertes Modell an eine andere, verwandte Aufgabe angepasst wird. Im Bereich Computer Vision können auf großen Datensätzen wie ImageNet vortrainierte Modelle für spezifische Anwendungen wie medizinische Bildgebung oder autonomes Fahren feinabgestimmt werden.
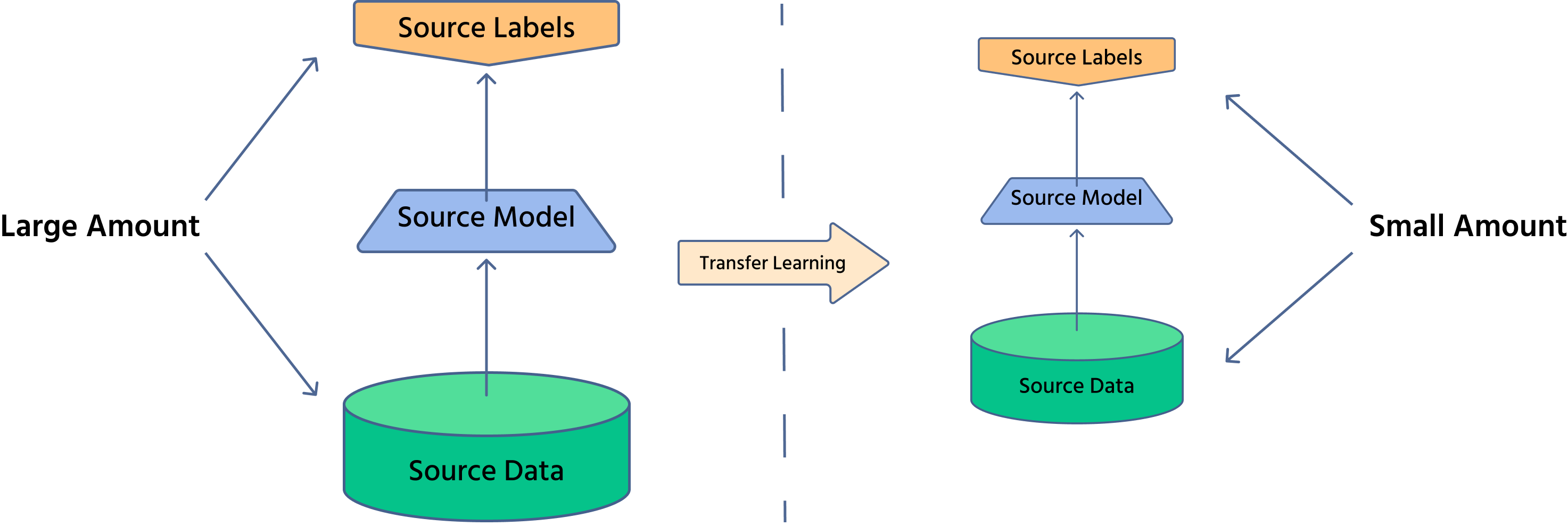
Warum ist Transferlernen wichtig?
- Reduziert die Trainingszeit: Da das Modell bereits allgemeine Merkmale gelernt hat, sind nur geringe Anpassungen erforderlich;
- Benötigt weniger Daten: Nützlich in Fällen, in denen die Beschaffung von gelabelten Daten kostspielig ist;
- Steigert die Leistung: Vorgefertigte Modelle bieten eine robuste Merkmalsextraktion und verbessern die Genauigkeit.
Ablauf des Transferlernens
Der typische Ablauf des Transferlernens umfasst mehrere zentrale Schritte:
-
Auswahl eines vortrainierten Modells:
- Auswahl eines Modells, das auf einem großen Datensatz trainiert wurde (z. B. ResNet, VGG, YOLO);
- Diese Modelle haben nützliche Repräsentationen gelernt, die für neue Aufgaben angepasst werden können.
-
Anpassung des vortrainierten Modells:
- Merkmalsextraktion: Frühe Schichten einfrieren und nur die späteren Schichten für die neue Aufgabe neu trainieren;
- Feinabstimmung: Einige oder alle Schichten freigeben und auf dem neuen Datensatz erneut trainieren.
-
Training auf dem neuen Datensatz:
- Training des angepassten Modells mit einem kleineren, auf die Zielaufgabe zugeschnittenen Datensatz;
- Optimierung mit Techniken wie Backpropagation und Loss-Funktionen.
-
Evaluation und Iteration:
- Bewertung der Leistung mit Metriken wie Genauigkeit, Präzision, Recall und mAP;
- Weitere Feinabstimmung bei Bedarf zur Verbesserung der Ergebnisse.
Beliebte vortrainierte Modelle
Zu den am häufigsten verwendeten vortrainierten Modellen für Computer Vision gehören:
- ResNet: Tiefe Residual-Netzwerke, die das Training sehr tiefer Architekturen ermöglichen;
- VGG: Eine einfache Architektur mit einheitlichen Faltungsschichten;
- EfficientNet: Für hohe Genauigkeit mit weniger Parametern optimiert;
- YOLO: State-of-the-Art (SOTA) für Echtzeit-Objekterkennung.
Feinabstimmung vs. Merkmalsextraktion
Merkmalsextraktion beinhaltet die Verwendung der Schichten eines vortrainierten Modells als feste Merkmalsextraktoren. Bei diesem Ansatz wird die ursprüngliche finale Klassifikationsschicht des Modells typischerweise entfernt und durch eine neue, auf die Zielaufgabe zugeschnittene Schicht ersetzt. Die vortrainierten Schichten bleiben eingefroren, das heißt, ihre Gewichte werden während des Trainings nicht aktualisiert. Dies beschleunigt das Training und erfordert weniger Daten.
from tensorflow.keras.applications import VGG16
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Flatten
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
for layer in base_model.layers:
layer.trainable = False # Freeze base model layers
x = Flatten()(base_model.output)
x = Dense(256, activation='relu')(x)
x = Dense(10, activation='softmax')(x) # Task-specific output
model = Model(inputs=base_model.input, outputs=x)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Feinabstimmung hingegen geht einen Schritt weiter, indem einige oder alle vortrainierten Schichten freigegeben und auf dem neuen Datensatz erneut trainiert werden. Dadurch kann das Modell die gelernten Merkmale besser an die spezifischen Eigenschaften der neuen Aufgabe anpassen, was häufig zu einer verbesserten Leistung führt – insbesondere, wenn der neue Datensatz ausreichend groß ist oder sich deutlich von den ursprünglichen Trainingsdaten unterscheidet.
for layer in base_model.layers[-10:]: # Unfreeze last 10 layers
layer.trainable = True
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Anwendungen des Transferlernens
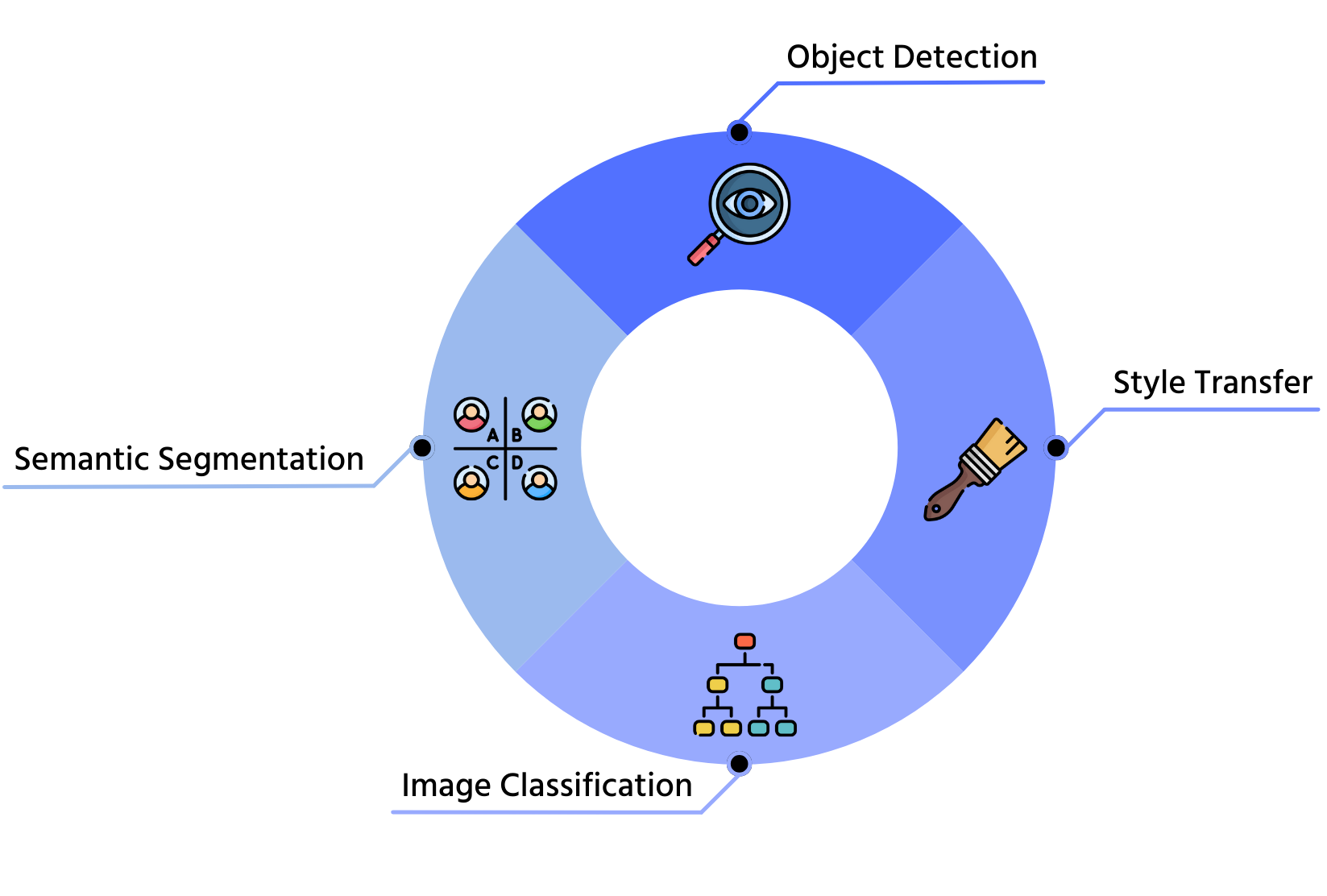
1. Bildklassifikation
Bildklassifikation umfasst das Zuweisen von Labels zu Bildern basierend auf deren visuellem Inhalt. Vorgefertigte Modelle wie ResNet und EfficientNet können für spezifische Aufgaben wie medizinische Bildgebung oder Wildtierklassifikation angepasst werden.
Beispiel:
- Auswahl eines vortrainierten Modells (z. B. ResNet);
- Anpassung der Klassifikationsschicht an die Zielklassen;
- Feinabstimmung mit einer niedrigeren Lernrate.
2. Objekterkennung
Objekterkennung beinhaltet sowohl das Identifizieren von Objekten als auch deren Lokalisierung innerhalb eines Bildes. Transferlernen ermöglicht es Modellen wie Faster R-CNN, SSD und YOLO, spezifische Objekte in neuen Datensätzen effizient zu erkennen.
Beispiel:
- Verwendung eines vortrainierten Objekterkennungsmodells (z. B. YOLOv8);
- Feinabstimmung auf einem eigenen Datensatz mit neuen Objektklassen;
- Bewertung der Leistung und entsprechende Optimierung.
3. Semantische Segmentierung
Semantische Segmentierung klassifiziert jedes Pixel in einem Bild in vordefinierte Kategorien. Modelle wie U-Net und DeepLab werden häufig in Anwendungen wie autonomem Fahren und medizinischer Bildgebung eingesetzt.
Beispiel:
- Verwendung eines vortrainierten Segmentierungsmodells (z. B. U-Net);
- Training auf einem domänenspezifischen Datensatz;
- Anpassung der Hyperparameter für bessere Genauigkeit.
4. Stiltransfer
Stiltransfer wendet den visuellen Stil eines Bildes auf ein anderes an, wobei der ursprüngliche Inhalt erhalten bleibt. Diese Technik wird häufig in der digitalen Kunst und Bildverbesserung eingesetzt und nutzt vortrainierte Modelle wie VGG.
Beispiel:
- Auswahl eines Stiltransfermodells (z. B. VGG);
- Eingabe von Inhalts- und Stilbildern;
- Optimierung für optisch ansprechende Ergebnisse.
1. Was ist der Hauptvorteil der Verwendung von Transferlernen im Bereich Computer Vision?
2. Welcher Ansatz wird im Transferlernen verwendet, wenn nur die letzte Schicht eines vortrainierten Modells modifiziert wird, während die vorherigen Schichten unverändert bleiben?
3. Welches der folgenden Modelle wird häufig für Transferlernen in der Objekterkennung verwendet?
Danke für Ihr Feedback!
Fragen Sie AI
Fragen Sie AI

Fragen Sie alles oder probieren Sie eine der vorgeschlagenen Fragen, um unser Gespräch zu beginnen
Transfer Learning in Computer Vision
Transfer Learning ermöglicht die Wiederverwendung von auf großen Datensätzen trainierten Modellen für neue Aufgaben mit begrenzten Daten. Anstatt ein neuronales Netzwerk von Grund auf neu zu erstellen, nutzen wir vortrainierte Modelle, um Effizienz und Leistung zu steigern. Im Verlauf dieses Kurses sind Ihnen bereits ähnliche Ansätze in vorherigen Abschnitten begegnet, die die Grundlage für den effektiven Einsatz von Transfer Learning geschaffen haben.
Was ist Transfer Learning?
Transfer Learning ist eine Technik, bei der ein auf eine Aufgabe trainiertes Modell an eine andere, verwandte Aufgabe angepasst wird. Im Bereich Computer Vision können auf großen Datensätzen wie ImageNet vortrainierte Modelle für spezifische Anwendungen wie medizinische Bildgebung oder autonomes Fahren feinabgestimmt werden.
Warum ist Transferlernen wichtig?
- Reduziert die Trainingszeit: Da das Modell bereits allgemeine Merkmale gelernt hat, sind nur geringe Anpassungen erforderlich;
- Benötigt weniger Daten: Nützlich in Fällen, in denen die Beschaffung von gelabelten Daten kostspielig ist;
- Steigert die Leistung: Vorgefertigte Modelle bieten eine robuste Merkmalsextraktion und verbessern die Genauigkeit.
Ablauf des Transferlernens
Der typische Ablauf des Transferlernens umfasst mehrere zentrale Schritte:
-
Auswahl eines vortrainierten Modells:
- Auswahl eines Modells, das auf einem großen Datensatz trainiert wurde (z. B. ResNet, VGG, YOLO);
- Diese Modelle haben nützliche Repräsentationen gelernt, die für neue Aufgaben angepasst werden können.
-
Anpassung des vortrainierten Modells:
- Merkmalsextraktion: Frühe Schichten einfrieren und nur die späteren Schichten für die neue Aufgabe neu trainieren;
- Feinabstimmung: Einige oder alle Schichten freigeben und auf dem neuen Datensatz erneut trainieren.
-
Training auf dem neuen Datensatz:
- Training des angepassten Modells mit einem kleineren, auf die Zielaufgabe zugeschnittenen Datensatz;
- Optimierung mit Techniken wie Backpropagation und Loss-Funktionen.
-
Evaluation und Iteration:
- Bewertung der Leistung mit Metriken wie Genauigkeit, Präzision, Recall und mAP;
- Weitere Feinabstimmung bei Bedarf zur Verbesserung der Ergebnisse.
Beliebte vortrainierte Modelle
Zu den am häufigsten verwendeten vortrainierten Modellen für Computer Vision gehören:
- ResNet: Tiefe Residual-Netzwerke, die das Training sehr tiefer Architekturen ermöglichen;
- VGG: Eine einfache Architektur mit einheitlichen Faltungsschichten;
- EfficientNet: Für hohe Genauigkeit mit weniger Parametern optimiert;
- YOLO: State-of-the-Art (SOTA) für Echtzeit-Objekterkennung.
Feinabstimmung vs. Merkmalsextraktion
Merkmalsextraktion beinhaltet die Verwendung der Schichten eines vortrainierten Modells als feste Merkmalsextraktoren. Bei diesem Ansatz wird die ursprüngliche finale Klassifikationsschicht des Modells typischerweise entfernt und durch eine neue, auf die Zielaufgabe zugeschnittene Schicht ersetzt. Die vortrainierten Schichten bleiben eingefroren, das heißt, ihre Gewichte werden während des Trainings nicht aktualisiert. Dies beschleunigt das Training und erfordert weniger Daten.
from tensorflow.keras.applications import VGG16
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Flatten
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
for layer in base_model.layers:
layer.trainable = False # Freeze base model layers
x = Flatten()(base_model.output)
x = Dense(256, activation='relu')(x)
x = Dense(10, activation='softmax')(x) # Task-specific output
model = Model(inputs=base_model.input, outputs=x)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Feinabstimmung hingegen geht einen Schritt weiter, indem einige oder alle vortrainierten Schichten freigegeben und auf dem neuen Datensatz erneut trainiert werden. Dadurch kann das Modell die gelernten Merkmale besser an die spezifischen Eigenschaften der neuen Aufgabe anpassen, was häufig zu einer verbesserten Leistung führt – insbesondere, wenn der neue Datensatz ausreichend groß ist oder sich deutlich von den ursprünglichen Trainingsdaten unterscheidet.
for layer in base_model.layers[-10:]: # Unfreeze last 10 layers
layer.trainable = True
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Anwendungen des Transferlernens
1. Bildklassifikation
Bildklassifikation umfasst das Zuweisen von Labels zu Bildern basierend auf deren visuellem Inhalt. Vorgefertigte Modelle wie ResNet und EfficientNet können für spezifische Aufgaben wie medizinische Bildgebung oder Wildtierklassifikation angepasst werden.
Beispiel:
- Auswahl eines vortrainierten Modells (z. B. ResNet);
- Anpassung der Klassifikationsschicht an die Zielklassen;
- Feinabstimmung mit einer niedrigeren Lernrate.
2. Objekterkennung
Objekterkennung beinhaltet sowohl das Identifizieren von Objekten als auch deren Lokalisierung innerhalb eines Bildes. Transferlernen ermöglicht es Modellen wie Faster R-CNN, SSD und YOLO, spezifische Objekte in neuen Datensätzen effizient zu erkennen.
Beispiel:
- Verwendung eines vortrainierten Objekterkennungsmodells (z. B. YOLOv8);
- Feinabstimmung auf einem eigenen Datensatz mit neuen Objektklassen;
- Bewertung der Leistung und entsprechende Optimierung.
3. Semantische Segmentierung
Semantische Segmentierung klassifiziert jedes Pixel in einem Bild in vordefinierte Kategorien. Modelle wie U-Net und DeepLab werden häufig in Anwendungen wie autonomem Fahren und medizinischer Bildgebung eingesetzt.
Beispiel:
- Verwendung eines vortrainierten Segmentierungsmodells (z. B. U-Net);
- Training auf einem domänenspezifischen Datensatz;
- Anpassung der Hyperparameter für bessere Genauigkeit.
4. Stiltransfer
Stiltransfer wendet den visuellen Stil eines Bildes auf ein anderes an, wobei der ursprüngliche Inhalt erhalten bleibt. Diese Technik wird häufig in der digitalen Kunst und Bildverbesserung eingesetzt und nutzt vortrainierte Modelle wie VGG.
Beispiel:
- Auswahl eines Stiltransfermodells (z. B. VGG);
- Eingabe von Inhalts- und Stilbildern;
- Optimierung für optisch ansprechende Ergebnisse.
Danke für Ihr Feedback!
