Ankerboxen
Swipe um das Menü anzuzeigen
Anchor-Box ist ein vordefinierter Begrenzungsrahmen mit fester Größe und festem Seitenverhältnis, der an bestimmten Positionen über ein Bild hinweg platziert wird.
Warum Anchor-Boxen in der Objekterkennung verwendet werden
Anchor-Boxen sind ein grundlegendes Konzept in modernen Objekterkennungsmodellen wie Faster R-CNN und YOLO. Sie dienen als vordefinierte Referenzrahmen, die helfen, Objekte unterschiedlicher Größen und Seitenverhältnisse zu erkennen, wodurch die Erkennung schneller und zuverlässiger wird.
Anstatt Objekte von Grund auf zu erkennen, verwenden Modelle Anchor-Boxen als Ausgangspunkt und passen diese an, um die erkannten Objekte besser abzubilden. Dieser Ansatz verbessert die Effizienz und Genauigkeit, insbesondere bei der Erkennung von Objekten in unterschiedlichen Maßstäben.
Unterschied zwischen Anchor-Box und Bounding-Box
- Anchor-Box: eine vordefinierte Vorlage, die während der Objekterkennung als Referenz dient;
- Bounding-Box: der endgültig vorhergesagte Rahmen, nachdem Anpassungen an einer Anchor-Box vorgenommen wurden, um das tatsächliche Objekt abzubilden.

Im Gegensatz zu Begrenzungsrahmen, die während der Vorhersage dynamisch angepasst werden, sind Ankerboxen vor der Objekterkennung an bestimmten Positionen festgelegt. Modelle lernen, Ankerboxen zu verfeinern, indem sie deren Größe, Position und Seitenverhältnis anpassen, sodass daraus endgültige Begrenzungsrahmen entstehen, die erkannte Objekte präzise abbilden.
Wie ein Netzwerk Ankerboxen generiert
Ankerboxen werden nicht direkt auf ein Bild angewendet, sondern auf Merkmalskarten, die aus dem Bild extrahiert wurden. Nach der Merkmalsextraktion wird eine Reihe von Ankerboxen auf diesen Merkmalskarten platziert, wobei Größe und Seitenverhältnis variieren. Die Auswahl der Ankerbox-Formen ist entscheidend und erfordert einen Ausgleich zwischen der Erkennung kleiner und großer Objekte.
Zur Definition der Ankerbox-Größen verwenden Modelle typischerweise eine Kombination aus manueller Auswahl und Clustering-Algorithmen wie K-Means, um den Datensatz zu analysieren und die häufigsten Objektformen und -größen zu bestimmen. Diese vordefinierten Ankerboxen werden dann an verschiedenen Positionen auf den Merkmalskarten angewendet. Ein Objekterkennungsmodell kann beispielsweise Ankerboxen der Größen (16x16), (32x32), (64x64) mit Seitenverhältnissen wie 1:1, 1:2, and 2:1 verwenden.
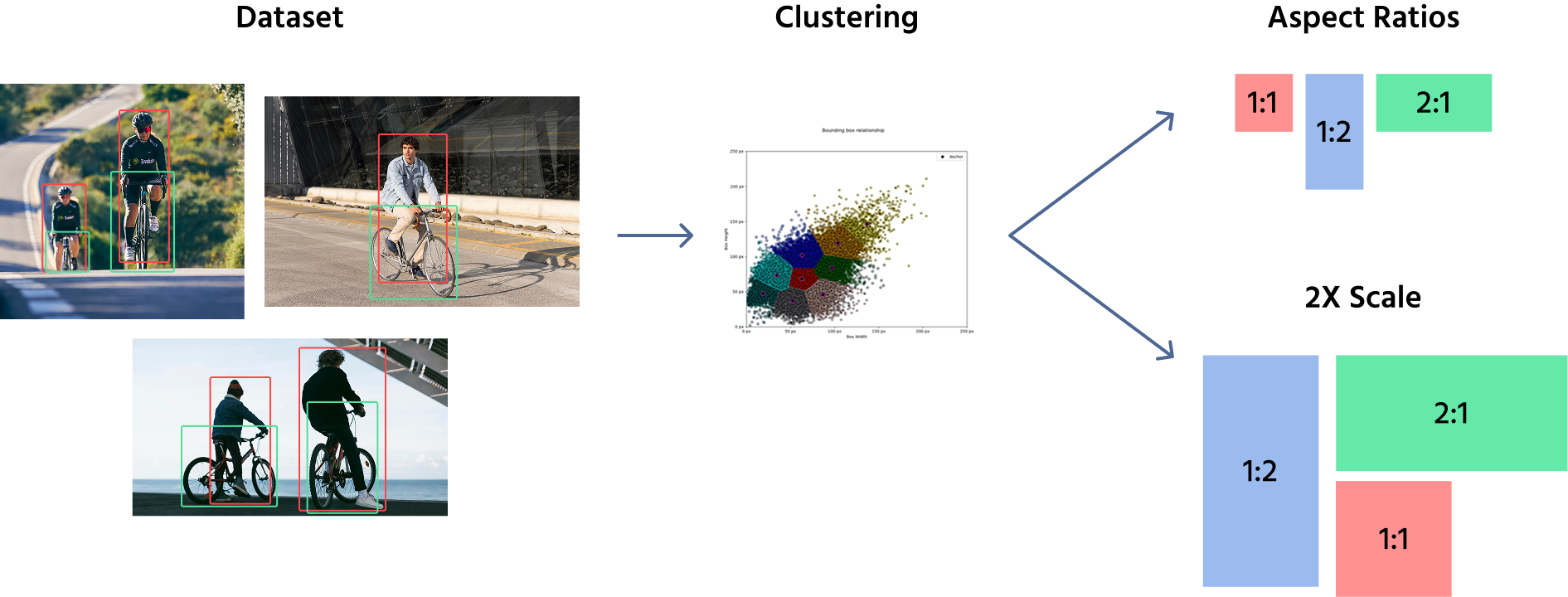
Sobald diese Ankerboxen definiert sind, werden sie auf die Feature-Maps und nicht auf das Originalbild angewendet. Das Modell weist jedem Ort der Feature-Map mehrere Ankerboxen zu, die verschiedene Formen und Größen abdecken. Während des Trainings passt das Netzwerk die Ankerboxen durch Vorhersage von Offsets an, um deren Größe und Position zu verfeinern und sie besser an die Objekte anzupassen.
Von der Ankerbox zur Begrenzungsbox
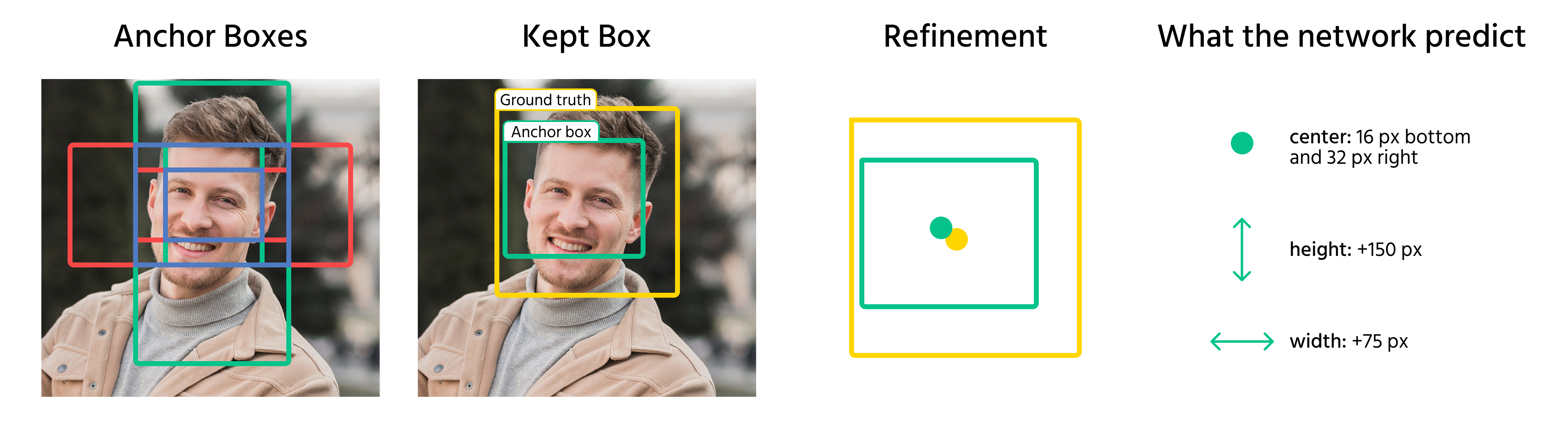
Nachdem Ankerboxen Objekten zugewiesen wurden, sagt das Modell Offsets voraus, um diese zu verfeinern. Diese Offsets umfassen:
- Anpassung der Mittelpunktkoordinaten der Box;
- Skalierung von Breite und Höhe;
- Verschiebung der Box zur besseren Ausrichtung mit dem Objekt.
Durch Anwendung dieser Transformationen wandelt das Modell Ankerboxen in finale Begrenzungsboxen um, die die Objekte im Bild möglichst genau abdecken.
Ansätze ohne oder mit reduzierter Anzahl von Ankerboxen
Obwohl Ankerboxen weit verbreitet sind, zielen einige Modelle darauf ab, deren Verwendung zu reduzieren oder vollständig darauf zu verzichten:
- Ankerfreie Methoden: Modelle wie
CenterNetundFCOSbestimmen Objektpositionen direkt ohne vordefinierte Anker, was die Komplexität verringert; - Ansätze mit reduzierten Ankern:
EfficientDetundYOLOv4optimieren die Anzahl der verwendeten Ankerboxen und balancieren so Erkennungsgeschwindigkeit und Genauigkeit.
Diese Ansätze zielen darauf ab, die Effizienz der Objekterkennung zu steigern und gleichzeitig eine hohe Leistung zu gewährleisten, insbesondere für Echtzeitanwendungen.
Zusammenfassend sind Ankerboxen ein wesentlicher Bestandteil der Objekterkennung und ermöglichen es Modellen, Objekte effizient über verschiedene Größen und Seitenverhältnisse hinweg zu erkennen. Neue Entwicklungen erforschen jedoch Möglichkeiten, Ankerboxen zu reduzieren oder zu eliminieren, um eine noch schnellere und flexiblere Erkennung zu ermöglichen.
1. Was ist die Hauptfunktion von Ankerboxen in der Objekterkennung?
2. Worin unterscheiden sich Ankerboxen von Begrenzungsrahmen?
3. Welches Verfahren wird häufig verwendet, um optimale Größen für Ankerboxen zu bestimmen?
Danke für Ihr Feedback!
Fragen Sie AI
Fragen Sie AI

Fragen Sie alles oder probieren Sie eine der vorgeschlagenen Fragen, um unser Gespräch zu beginnen
