Überblick Über Das YOLO-Modell
Swipe um das Menü anzuzeigen
Der YOLO-Algorithmus (You Only Look Once) ist ein schnelles und effizientes Modell zur Objekterkennung. Im Gegensatz zu traditionellen Ansätzen wie R-CNN, die mehrere Schritte verwenden, verarbeitet YOLO das gesamte Bild in einem einzigen Durchlauf und ist daher ideal für Echtzeitanwendungen geeignet.
Unterschiede zwischen YOLO und R-CNN-Ansätzen
Traditionelle Methoden der Objekterkennung, wie R-CNN und deren Varianten, basieren auf einer zweistufigen Pipeline: Zunächst werden Regionenvorschläge generiert, anschließend wird jede vorgeschlagene Region klassifiziert. Obwohl dieses Verfahren effektiv ist, ist es rechenintensiv und verlangsamt die Inferenz, wodurch es weniger für Echtzeitanwendungen geeignet ist.
YOLO (You Only Look Once) verfolgt einen grundlegend anderen Ansatz. Das Eingabebild wird in ein Gitter unterteilt, und für jede Zelle werden Begrenzungsrahmen sowie Klassenzugehörigkeitswahrscheinlichkeiten in einem einzigen Vorwärtsdurchlauf vorhergesagt. Dieses Design betrachtet die Objekterkennung als ein einziges Regressionsproblem und ermöglicht YOLO dadurch eine Echtzeitleistung.
Im Gegensatz zu R-CNN-basierten Methoden, die sich nur auf lokale Regionen konzentrieren, verarbeitet YOLO das gesamte Bild gleichzeitig und kann dadurch globale Kontextinformationen erfassen. Dies führt zu einer besseren Erkennung von mehreren oder überlappenden Objekten, während gleichzeitig hohe Geschwindigkeit und Genauigkeit beibehalten werden.
YOLO-Architektur und gitterbasierte Vorhersagen
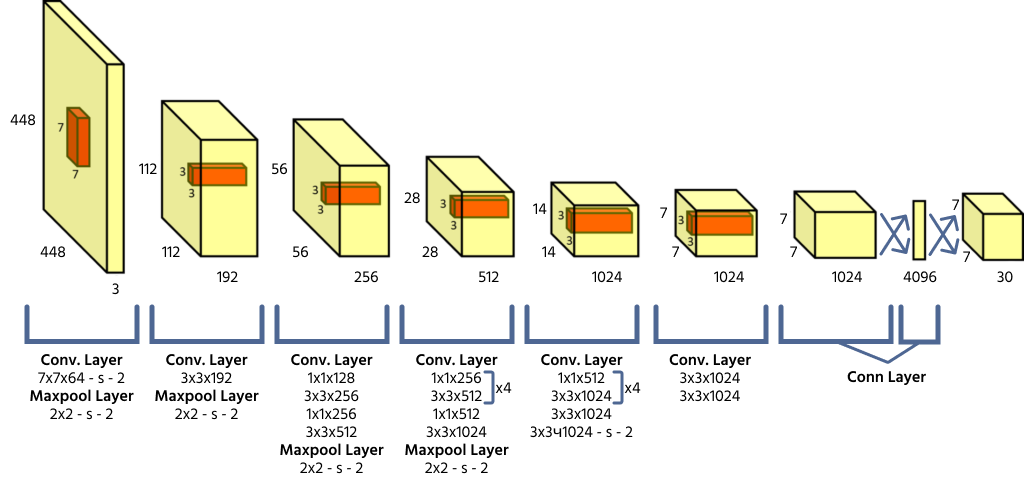
YOLO unterteilt ein Eingabebild in ein S × S-Gitter, wobei jede Gitterzelle für die Erkennung von Objekten verantwortlich ist, deren Mittelpunkt in diese Zelle fällt. Jede Zelle sagt die Koordinaten des Begrenzungsrahmens (x, y, Breite, Höhe), einen Objekt-Konfidenzwert und Klassenzugehörigkeitswahrscheinlichkeiten voraus. Da YOLO das gesamte Bild in einem einzigen Vorwärtsdurchlauf verarbeitet, ist es im Vergleich zu früheren Modellen der Objekterkennung äußerst effizient.
Verlustfunktion und Klassenzuverlässigkeitswerte
YOLO optimiert die Erkennungsgenauigkeit mithilfe einer benutzerdefinierten Verlustfunktion, die Folgendes umfasst:
- Lokalisationverlust: misst die Genauigkeit der Begrenzungsrahmen;
- Konfidenzverlust: stellt sicher, dass Vorhersagen das Vorhandensein eines Objekts korrekt anzeigen;
- Klassifikationsverlust: bewertet, wie gut die vorhergesagte Klasse mit der tatsächlichen Klasse übereinstimmt.
Zur Ergebnisverbesserung verwendet YOLO Ankerboxen und Non-Maximum Suppression (NMS), um redundante Erkennungen zu entfernen.
Vorteile von YOLO: Abwägung zwischen Geschwindigkeit und Genauigkeit
Der Hauptvorteil von YOLO ist die Geschwindigkeit. Da die Erkennung in einem einzigen Durchlauf erfolgt, ist YOLO deutlich schneller als R-CNN-basierte Methoden und eignet sich daher für Echtzeitanwendungen wie autonomes Fahren und Überwachung. Frühere YOLO-Versionen hatten Schwierigkeiten bei der Erkennung kleiner Objekte, was in späteren Versionen verbessert wurde.
YOLO: Ein kurzer Überblick
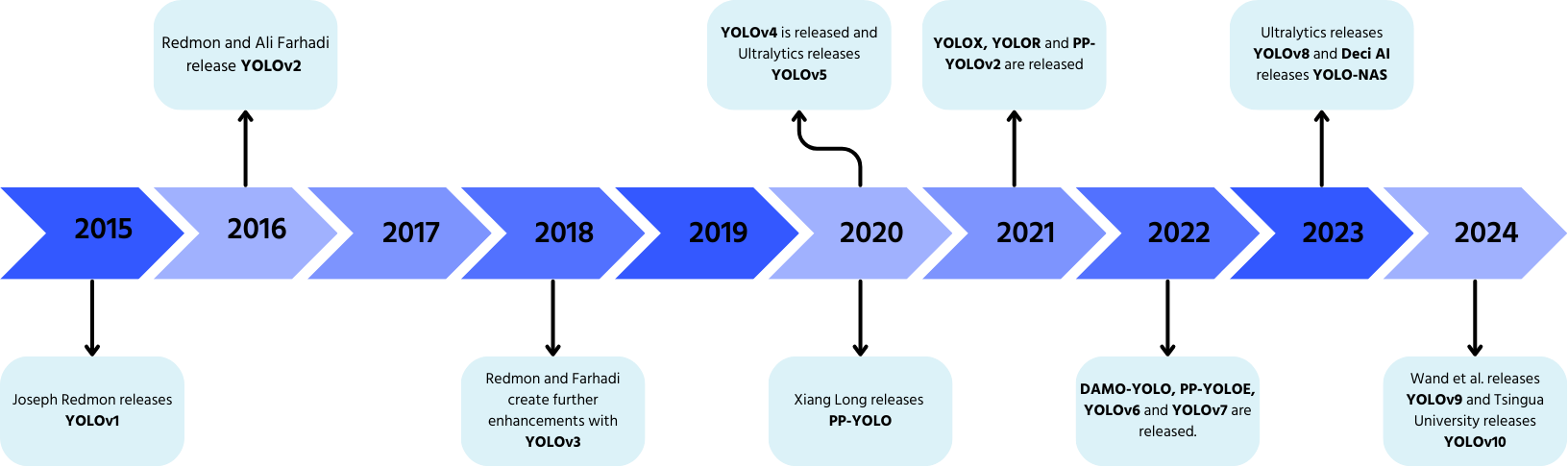
YOLO, entwickelt von Joseph Redmon und Ali Farhadi im Jahr 2015, revolutionierte die Objekterkennung durch die Verarbeitung in einem einzigen Durchlauf.
- YOLOv2 (2016): Einführung von Batch-Normalisierung, Ankerboxen und Dimensions-Clustern;
- YOLOv3 (2018): Einführung eines effizienteren Backbones, mehrerer Anker und Spatial Pyramid Pooling;
- YOLOv4 (2020): Hinzufügen von Mosaic-Datenaugmentation, einem ankerfreien Erkennungskopf und einer neuen Verlustfunktion;
- YOLOv5: Verbesserte Leistung durch Hyperparameter-Optimierung, Experiment-Tracking und automatische Exportfunktionen;
- YOLOv6 (2022): Open Source von Meituan und Einsatz in autonomen Lieferrobotern;
- YOLOv7: Erweiterung der Fähigkeiten um Posenabschätzung;
- YOLOv8 (2023): Verbesserte Geschwindigkeit, Flexibilität und Effizienz für Vision-AI-Aufgaben;
- YOLOv9: Einführung von Programmable Gradient Information (PGI) und dem Generalized Efficient Layer Aggregation Network (GELAN);
- YOLOv10: Entwickelt von der Tsinghua-Universität, Eliminierung von Non-Maximum Suppression (NMS) mit einem End-to-End-Erkennungskopf;
- YOLOv11: Das neueste Modell mit modernster Leistung in Objekterkennung, Segmentierung und Klassifikation.
Danke für Ihr Feedback!
Fragen Sie AI
Fragen Sie AI

Fragen Sie alles oder probieren Sie eine der vorgeschlagenen Fragen, um unser Gespräch zu beginnen
Überblick Über Das YOLO-Modell
Der YOLO-Algorithmus (You Only Look Once) ist ein schnelles und effizientes Modell zur Objekterkennung. Im Gegensatz zu traditionellen Ansätzen wie R-CNN, die mehrere Schritte verwenden, verarbeitet YOLO das gesamte Bild in einem einzigen Durchlauf und ist daher ideal für Echtzeitanwendungen geeignet.
Unterschiede zwischen YOLO und R-CNN-Ansätzen
Traditionelle Methoden der Objekterkennung, wie R-CNN und deren Varianten, basieren auf einer zweistufigen Pipeline: Zunächst werden Regionenvorschläge generiert, anschließend wird jede vorgeschlagene Region klassifiziert. Obwohl dieses Verfahren effektiv ist, ist es rechenintensiv und verlangsamt die Inferenz, wodurch es weniger für Echtzeitanwendungen geeignet ist.
YOLO (You Only Look Once) verfolgt einen grundlegend anderen Ansatz. Das Eingabebild wird in ein Gitter unterteilt, und für jede Zelle werden Begrenzungsrahmen sowie Klassenzugehörigkeitswahrscheinlichkeiten in einem einzigen Vorwärtsdurchlauf vorhergesagt. Dieses Design betrachtet die Objekterkennung als ein einziges Regressionsproblem und ermöglicht YOLO dadurch eine Echtzeitleistung.
Im Gegensatz zu R-CNN-basierten Methoden, die sich nur auf lokale Regionen konzentrieren, verarbeitet YOLO das gesamte Bild gleichzeitig und kann dadurch globale Kontextinformationen erfassen. Dies führt zu einer besseren Erkennung von mehreren oder überlappenden Objekten, während gleichzeitig hohe Geschwindigkeit und Genauigkeit beibehalten werden.
YOLO-Architektur und gitterbasierte Vorhersagen
YOLO unterteilt ein Eingabebild in ein S × S-Gitter, wobei jede Gitterzelle für die Erkennung von Objekten verantwortlich ist, deren Mittelpunkt in diese Zelle fällt. Jede Zelle sagt die Koordinaten des Begrenzungsrahmens (x, y, Breite, Höhe), einen Objekt-Konfidenzwert und Klassenzugehörigkeitswahrscheinlichkeiten voraus. Da YOLO das gesamte Bild in einem einzigen Vorwärtsdurchlauf verarbeitet, ist es im Vergleich zu früheren Modellen der Objekterkennung äußerst effizient.
Verlustfunktion und Klassenzuverlässigkeitswerte
YOLO optimiert die Erkennungsgenauigkeit mithilfe einer benutzerdefinierten Verlustfunktion, die Folgendes umfasst:
- Lokalisationverlust: misst die Genauigkeit der Begrenzungsrahmen;
- Konfidenzverlust: stellt sicher, dass Vorhersagen das Vorhandensein eines Objekts korrekt anzeigen;
- Klassifikationsverlust: bewertet, wie gut die vorhergesagte Klasse mit der tatsächlichen Klasse übereinstimmt.
Zur Ergebnisverbesserung verwendet YOLO Ankerboxen und Non-Maximum Suppression (NMS), um redundante Erkennungen zu entfernen.
Vorteile von YOLO: Abwägung zwischen Geschwindigkeit und Genauigkeit
Der Hauptvorteil von YOLO ist die Geschwindigkeit. Da die Erkennung in einem einzigen Durchlauf erfolgt, ist YOLO deutlich schneller als R-CNN-basierte Methoden und eignet sich daher für Echtzeitanwendungen wie autonomes Fahren und Überwachung. Frühere YOLO-Versionen hatten Schwierigkeiten bei der Erkennung kleiner Objekte, was in späteren Versionen verbessert wurde.
YOLO: Ein kurzer Überblick
YOLO, entwickelt von Joseph Redmon und Ali Farhadi im Jahr 2015, revolutionierte die Objekterkennung durch die Verarbeitung in einem einzigen Durchlauf.
- YOLOv2 (2016): Einführung von Batch-Normalisierung, Ankerboxen und Dimensions-Clustern;
- YOLOv3 (2018): Einführung eines effizienteren Backbones, mehrerer Anker und Spatial Pyramid Pooling;
- YOLOv4 (2020): Hinzufügen von Mosaic-Datenaugmentation, einem ankerfreien Erkennungskopf und einer neuen Verlustfunktion;
- YOLOv5: Verbesserte Leistung durch Hyperparameter-Optimierung, Experiment-Tracking und automatische Exportfunktionen;
- YOLOv6 (2022): Open Source von Meituan und Einsatz in autonomen Lieferrobotern;
- YOLOv7: Erweiterung der Fähigkeiten um Posenabschätzung;
- YOLOv8 (2023): Verbesserte Geschwindigkeit, Flexibilität und Effizienz für Vision-AI-Aufgaben;
- YOLOv9: Einführung von Programmable Gradient Information (PGI) und dem Generalized Efficient Layer Aggregation Network (GELAN);
- YOLOv10: Entwickelt von der Tsinghua-Universität, Eliminierung von Non-Maximum Suppression (NMS) mit einem End-to-End-Erkennungskopf;
- YOLOv11: Das neueste Modell mit modernster Leistung in Objekterkennung, Segmentierung und Klassifikation.
Danke für Ihr Feedback!
