Vorhersagen von Begrenzungsrahmen
Swipe um das Menü anzuzeigen
Begrenzungsrahmen sind entscheidend für die Objekterkennung und ermöglichen die Markierung von Objektpositionen. Objekterkennungsmodelle verwenden diese Rahmen, um die Position und die Abmessungen erkannter Objekte innerhalb eines Bildes zu definieren. Eine präzise Vorhersage der Begrenzungsrahmen ist grundlegend, um eine zuverlässige Objekterkennung zu gewährleisten.
Wie CNNs Begrenzungsrahmen-Koordinaten vorhersagen
Convolutional Neural Networks (CNNs) verarbeiten Bilder durch Schichten von Faltungen und Pooling, um Merkmale zu extrahieren. Für die Objekterkennung erzeugen CNNs Merkmalskarten, die verschiedene Bildbereiche repräsentieren. Die Vorhersage von Begrenzungsrahmen erfolgt typischerweise durch:
- Extraktion von Merkmalsrepräsentationen aus dem Bild;
- Anwendung einer Regressionsfunktion zur Vorhersage der Begrenzungsrahmen-Koordinaten;
- Klassifizierung der erkannten Objekte innerhalb jedes Rahmens.
Vorhersagen von Begrenzungsrahmen werden als numerische Werte dargestellt, die Folgendes entsprechen:
- (x, y): die Koordinaten des Mittelpunkts des Rahmens;
- (w, h): die Breite und Höhe des Rahmens.
Beispiel: Vorhersage von Begrenzungsrahmen mit einem vortrainierten Modell
Anstatt ein CNN von Grund auf zu trainieren, kann ein vortrainiertes Modell wie Faster R-CNN aus dem TensorFlow Model Zoo verwendet werden, um Begrenzungsrahmen auf einem Bild vorherzusagen. Nachfolgend ein Beispiel zum Laden eines vortrainierten Modells, Laden eines Bildes, Durchführen von Vorhersagen und Visualisieren der Begrenzungsrahmen mit Klassenbezeichnungen.
Bibliotheken importieren
import cv2
import tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
from tensorflow.image import draw_bounding_boxes
Modell und Bild laden
# Load a pretrained Faster R-CNN model from TensorFlow Hub
model = hub.load("https://www.kaggle.com/models/tensorflow/faster-rcnn-resnet-v1/TensorFlow2/faster-rcnn-resnet101-v1-1024x1024/1")
# Load and preprocess the image
img_path = "../../../Documents/Codefinity/CV/Pictures/Section 4/object_detection/bikes_n_persons.png"
img = cv2.imread(img_path)
Bild vorverarbeiten
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_resized = tf.image.resize(img, (1024, 1024))
# Convert to uint8
img_resized = tf.cast(img_resized, dtype=tf.uint8)
# Convert to tensor
img_tensor = tf.convert_to_tensor(img_resized)[tf.newaxis, ...]
Vorhersage durchführen und Bounding-Box-Merkmale extrahieren
# Make predictions
output = model(img_tensor)
# Extract bounding box coordinates
num_detections = int(output['num_detections'][0])
bboxes = output['detection_boxes'][0][:num_detections].numpy()
class_names = output['detection_classes'][0][:num_detections].numpy().astype(int)
scores = output['detection_scores'][0][:num_detections].numpy()
# Example labels from COCO dataset
labels = {1: "Person", 2: "Bike"}
Bounding-Boxen zeichnen
# Draw bounding boxes with labels
for i in range(num_detections):
# Confidence threshold
if scores[i] > 0.5:
y1, x1, y2, x2 = bboxes[i]
start_point = (int(x1 * img.shape[1]), int(y1 * img.shape[0]))
end_point = (int(x2 * img.shape[1]), int(y2 * img.shape[0]))
cv2.rectangle(img, start_point, end_point, (0, 255, 0), 2)
# Get label or 'Unknown'
label = labels.get(class_names[i], "Unknown")
cv2.putText(img, f"{label} ({scores[i]:.2f})", (start_point[0], start_point[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
Visualisierung
# Display image with bounding boxes and labels
plt.figure()
plt.imshow(img)
plt.axis("off")
plt.title("Object Detection with Bounding Boxes and Labels")
plt.show()
Ergebnis:

Regressionsbasierte Vorhersage von Begrenzungsrahmen
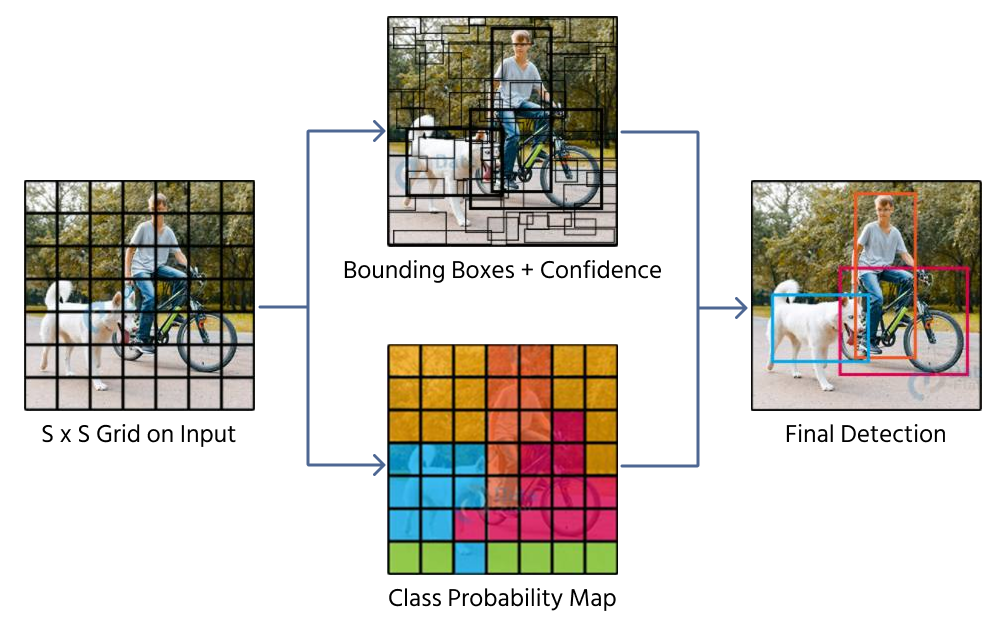
Ein Ansatz zur Vorhersage von Begrenzungsrahmen ist die direkte Regression, bei der ein CNN vier numerische Werte ausgibt, die die Position und Größe des Rahmens darstellen. Modelle wie YOLO (You Only Look Once) verwenden diese Technik, indem sie ein Bild in ein Raster unterteilen und den Rasterzellen Begrenzungsrahmen-Vorhersagen zuweisen.
Die direkte Regression weist jedoch Einschränkungen auf:
- Schwierigkeiten bei Objekten mit unterschiedlichen Größen und Seitenverhältnissen;
- Unzureichende Handhabung überlappender Objekte;
- Begrenzungsrahmen können sich unvorhersehbar verschieben, was zu Inkonsistenzen führt.
Ankerbasierte vs. Ankerfreie Ansätze
Ankerbasierte Methoden
Ankerboxen sind vordefinierte Begrenzungsrahmen mit festen Größen und Seitenverhältnissen. Modelle wie Faster R-CNN und SSD (Single Shot MultiBox Detector) verwenden Ankerboxen, um die Vorhersagegenauigkeit zu verbessern. Das Modell sagt Anpassungen an den Ankerboxen voraus, anstatt Begrenzungsrahmen von Grund auf zu bestimmen. Diese Methode eignet sich gut zur Erkennung von Objekten in unterschiedlichen Maßstäben, erhöht jedoch die Rechenkomplexität.
Ankerfreie Methoden
Ankerfreie Methoden wie CenterNet und FCOS (Fully Convolutional One-Stage Object Detection) verzichten auf vordefinierte Ankerboxen und sagen stattdessen direkt die Objektzentren voraus. Diese Methoden bieten:
- Einfachere Modellarchitekturen;
- Schnellere Inferenzzeiten;
- Verbesserte Generalisierung auf unbekannte Objektgrößen.

A (Anker-basiert): Sagt Offsets (grüne Linien) von vordefinierten Ankern (blau) voraus, um mit dem Ground Truth (rot) übereinzustimmen. B (Anker-frei): Schätzt Offsets direkt von einem Punkt zu seinen Begrenzungen.
Vorhersage von Begrenzungsrahmen ist ein zentrales Element der Objekterkennung, wobei verschiedene Ansätze Genauigkeit und Effizienz ausbalancieren. Während ankerbasierte Methoden die Präzision durch vordefinierte Formen erhöhen, vereinfachen ankerfreie Methoden die Erkennung, indem sie Objektpositionen direkt vorhersagen. Das Verständnis dieser Techniken unterstützt die Entwicklung leistungsfähiger Objekterkennungssysteme für vielfältige Anwendungen in der Praxis.
1. Welche Informationen enthält eine Bounding-Box-Vorhersage typischerweise?
2. Was ist der Hauptvorteil von Anker-basierten Methoden in der Objekterkennung?
3. Welcher Herausforderung steht die direkte Regression bei der Bounding-Box-Vorhersage gegenüber?
Danke für Ihr Feedback!
Fragen Sie AI
Fragen Sie AI

Fragen Sie alles oder probieren Sie eine der vorgeschlagenen Fragen, um unser Gespräch zu beginnen
Vorhersagen von Begrenzungsrahmen
Begrenzungsrahmen sind entscheidend für die Objekterkennung und ermöglichen die Markierung von Objektpositionen. Objekterkennungsmodelle verwenden diese Rahmen, um die Position und die Abmessungen erkannter Objekte innerhalb eines Bildes zu definieren. Eine präzise Vorhersage der Begrenzungsrahmen ist grundlegend, um eine zuverlässige Objekterkennung zu gewährleisten.
Wie CNNs Begrenzungsrahmen-Koordinaten vorhersagen
Convolutional Neural Networks (CNNs) verarbeiten Bilder durch Schichten von Faltungen und Pooling, um Merkmale zu extrahieren. Für die Objekterkennung erzeugen CNNs Merkmalskarten, die verschiedene Bildbereiche repräsentieren. Die Vorhersage von Begrenzungsrahmen erfolgt typischerweise durch:
- Extraktion von Merkmalsrepräsentationen aus dem Bild;
- Anwendung einer Regressionsfunktion zur Vorhersage der Begrenzungsrahmen-Koordinaten;
- Klassifizierung der erkannten Objekte innerhalb jedes Rahmens.
Vorhersagen von Begrenzungsrahmen werden als numerische Werte dargestellt, die Folgendes entsprechen:
- (x, y): die Koordinaten des Mittelpunkts des Rahmens;
- (w, h): die Breite und Höhe des Rahmens.
Beispiel: Vorhersage von Begrenzungsrahmen mit einem vortrainierten Modell
Anstatt ein CNN von Grund auf zu trainieren, kann ein vortrainiertes Modell wie Faster R-CNN aus dem TensorFlow Model Zoo verwendet werden, um Begrenzungsrahmen auf einem Bild vorherzusagen. Nachfolgend ein Beispiel zum Laden eines vortrainierten Modells, Laden eines Bildes, Durchführen von Vorhersagen und Visualisieren der Begrenzungsrahmen mit Klassenbezeichnungen.
Bibliotheken importieren
import cv2
import tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
from tensorflow.image import draw_bounding_boxes
Modell und Bild laden
# Load a pretrained Faster R-CNN model from TensorFlow Hub
model = hub.load("https://www.kaggle.com/models/tensorflow/faster-rcnn-resnet-v1/TensorFlow2/faster-rcnn-resnet101-v1-1024x1024/1")
# Load and preprocess the image
img_path = "../../../Documents/Codefinity/CV/Pictures/Section 4/object_detection/bikes_n_persons.png"
img = cv2.imread(img_path)
Bild vorverarbeiten
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_resized = tf.image.resize(img, (1024, 1024))
# Convert to uint8
img_resized = tf.cast(img_resized, dtype=tf.uint8)
# Convert to tensor
img_tensor = tf.convert_to_tensor(img_resized)[tf.newaxis, ...]
Vorhersage durchführen und Bounding-Box-Merkmale extrahieren
# Make predictions
output = model(img_tensor)
# Extract bounding box coordinates
num_detections = int(output['num_detections'][0])
bboxes = output['detection_boxes'][0][:num_detections].numpy()
class_names = output['detection_classes'][0][:num_detections].numpy().astype(int)
scores = output['detection_scores'][0][:num_detections].numpy()
# Example labels from COCO dataset
labels = {1: "Person", 2: "Bike"}
Bounding-Boxen zeichnen
# Draw bounding boxes with labels
for i in range(num_detections):
# Confidence threshold
if scores[i] > 0.5:
y1, x1, y2, x2 = bboxes[i]
start_point = (int(x1 * img.shape[1]), int(y1 * img.shape[0]))
end_point = (int(x2 * img.shape[1]), int(y2 * img.shape[0]))
cv2.rectangle(img, start_point, end_point, (0, 255, 0), 2)
# Get label or 'Unknown'
label = labels.get(class_names[i], "Unknown")
cv2.putText(img, f"{label} ({scores[i]:.2f})", (start_point[0], start_point[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
Visualisierung
# Display image with bounding boxes and labels
plt.figure()
plt.imshow(img)
plt.axis("off")
plt.title("Object Detection with Bounding Boxes and Labels")
plt.show()
Ergebnis:
Regressionsbasierte Vorhersage von Begrenzungsrahmen
Ein Ansatz zur Vorhersage von Begrenzungsrahmen ist die direkte Regression, bei der ein CNN vier numerische Werte ausgibt, die die Position und Größe des Rahmens darstellen. Modelle wie YOLO (You Only Look Once) verwenden diese Technik, indem sie ein Bild in ein Raster unterteilen und den Rasterzellen Begrenzungsrahmen-Vorhersagen zuweisen.
Die direkte Regression weist jedoch Einschränkungen auf:
- Schwierigkeiten bei Objekten mit unterschiedlichen Größen und Seitenverhältnissen;
- Unzureichende Handhabung überlappender Objekte;
- Begrenzungsrahmen können sich unvorhersehbar verschieben, was zu Inkonsistenzen führt.
Ankerbasierte vs. Ankerfreie Ansätze
Ankerbasierte Methoden
Ankerboxen sind vordefinierte Begrenzungsrahmen mit festen Größen und Seitenverhältnissen. Modelle wie Faster R-CNN und SSD (Single Shot MultiBox Detector) verwenden Ankerboxen, um die Vorhersagegenauigkeit zu verbessern. Das Modell sagt Anpassungen an den Ankerboxen voraus, anstatt Begrenzungsrahmen von Grund auf zu bestimmen. Diese Methode eignet sich gut zur Erkennung von Objekten in unterschiedlichen Maßstäben, erhöht jedoch die Rechenkomplexität.
Ankerfreie Methoden
Ankerfreie Methoden wie CenterNet und FCOS (Fully Convolutional One-Stage Object Detection) verzichten auf vordefinierte Ankerboxen und sagen stattdessen direkt die Objektzentren voraus. Diese Methoden bieten:
- Einfachere Modellarchitekturen;
- Schnellere Inferenzzeiten;
- Verbesserte Generalisierung auf unbekannte Objektgrößen.
A (Anker-basiert): Sagt Offsets (grüne Linien) von vordefinierten Ankern (blau) voraus, um mit dem Ground Truth (rot) übereinzustimmen. B (Anker-frei): Schätzt Offsets direkt von einem Punkt zu seinen Begrenzungen.
Vorhersage von Begrenzungsrahmen ist ein zentrales Element der Objekterkennung, wobei verschiedene Ansätze Genauigkeit und Effizienz ausbalancieren. Während ankerbasierte Methoden die Präzision durch vordefinierte Formen erhöhen, vereinfachen ankerfreie Methoden die Erkennung, indem sie Objektpositionen direkt vorhersagen. Das Verständnis dieser Techniken unterstützt die Entwicklung leistungsfähiger Objekterkennungssysteme für vielfältige Anwendungen in der Praxis.
Danke für Ihr Feedback!
