Objekterkennung
Swipe um das Menü anzuzeigen
Objekterkennung stellt einen entscheidenden Fortschritt gegenüber der Bildklassifikation und -lokalisierung dar. Während die Klassifikation bestimmt, welches Objekt in einem Bild vorhanden ist, und die Lokalisierung angibt, wo sich ein einzelnes Objekt befindet, erweitert die Objekterkennung dies, indem sie mehrere Objekte und deren Positionen innerhalb eines Bildes erkennt.
Was unterscheidet die Objekterkennung?
Im Gegensatz zur Klassifikation, bei der einem gesamten Bild ein einzelnes Label zugewiesen wird, umfasst die Objekterkennung sowohl Klassifikation als auch Lokalisierung für mehrere Objekte. Ein Erkennungsmodell muss Begrenzungsrahmen (Bounding Boxes) für jedes Objekt vorhersagen und diese korrekt klassifizieren. Dadurch ist die Objekterkennung eine komplexere und rechnerisch aufwendigere Aufgabe als die einfache Klassifikation.

Sliding-Window-Ansatz & seine Einschränkungen
Eine traditionelle Methode zur Objekterkennung ist der Sliding-Window-Ansatz, bei dem ein Fenster fester Größe über ein Bild verschoben wird, um jeden Abschnitt zu klassifizieren. Obwohl das Konzept einfach ist, weist es mehrere Einschränkungen auf:
- Hoher Rechenaufwand: Erfordert das Scannen des Bildes auf mehreren Skalen und Positionen, was zu einer langen Verarbeitungszeit führt;
- Starre Fenstergrößen: Objekte variieren in Größe und Seitenverhältnis, wodurch Fenster fester Größe ineffizient sind;
- Redundante Berechnungen: Überlappende Fenster verarbeiten wiederholt ähnliche Bildbereiche und verschwenden Ressourcen.
Aufgrund dieser Ineffizienzen wurden Sliding-Window-Ansätze weitgehend durch Deep-Learning-basierte Methoden zur Objekterkennung ersetzt.

Regionenbasierte Methoden: Selective Search & Region Proposal Networks (RPN)
Zur Effizienzsteigerung schlagen regionenbasierte Methoden Regions of Interest (RoIs) vor, anstatt das gesamte Bild zu durchsuchen. Zwei wichtige Techniken sind:
-
Selective Search: Ein traditioneller Ansatz, der ähnliche Pixel zu Regionenvorschlägen gruppiert und so die Anzahl der Bounding-Box-Vorhersagen reduziert. Obwohl effizienter als Sliding Windows, ist er dennoch langsam;
-
Region Proposal Networks (RPNs): Eingesetzt in Faster R-CNN, verwenden RPNs ein neuronales Netzwerk, um potenzielle Objektregionen direkt zu generieren, was Geschwindigkeit und Genauigkeit im Vergleich zu Selective Search deutlich verbessert.
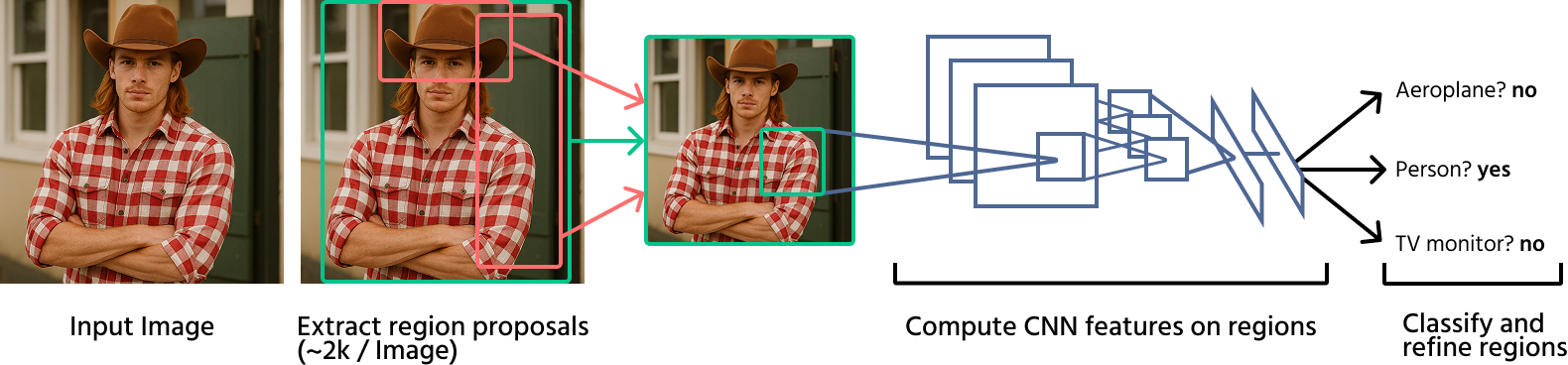
Frühe Deep-Learning-basierte Ansätze
Deep Learning hat die Objekterkennung revolutioniert, indem Convolutional Neural Networks (CNNs) in die Erkennungs-Pipelines eingeführt wurden. Zu den wegweisenden Modellen gehören:
-
R-CNN (Regions with CNNs): Dieses Verfahren wendet ein CNN auf jeden durch Selective Search generierten Bereichsvorschlag an. Es ist deutlich genauer als traditionelle Methoden, jedoch aufgrund mehrfacher CNN-Auswertungen rechnerisch langsam;
-
Fast R-CNN: Eine Verbesserung gegenüber R-CNN; dieses Modell verarbeitet das gesamte Bild zunächst mit einem CNN und nutzt anschließend RoI-Pooling, um Merkmale für die Klassifikation zu extrahieren, was die Erkennung beschleunigt;
-
Faster R-CNN: Führt Region Proposal Networks (RPNs) ein, um Selective Search zu ersetzen. Dadurch wird die Objekterkennung schneller und genauer, da die Generierung der Bereichsvorschläge direkt in das neuronale Netzwerk integriert wird.
Objekterkennung baut auf Klassifikation und Lokalisierung auf und ermöglicht es Modellen, mehrere Objekte innerhalb eines Bildes zu erkennen. Traditionelle Methoden wie Sliding Windows wurden durch effizientere, bereichsbasierte Techniken wie R-CNN und dessen Nachfolger ersetzt. Faster R-CNN mit dem Einsatz von Region Proposal Networks stellt einen bedeutenden Schritt in Richtung Echtzeit- und hochpräziser Objekterkennung dar. Zukünftig werden fortschrittlichere Verfahren wie YOLO und SSD die Erkennungsgeschwindigkeit und Effizienz weiter verbessern.
1. Was ist der Hauptvorteil von Faster R-CNN gegenüber Fast R-CNN?
2. Warum ist der Sliding-Window-Ansatz für die Objekterkennung ineffizient?
3. Welche der folgenden Methoden ist ein Deep-Learning-basierter Ansatz zur Objekterkennung?
Danke für Ihr Feedback!
Fragen Sie AI
Fragen Sie AI

Fragen Sie alles oder probieren Sie eine der vorgeschlagenen Fragen, um unser Gespräch zu beginnen
