Redes Generativas Antagónicas (GANs)
Desliza para mostrar el menú
Redes Generativas Antagónicas (GANs) son una clase de modelos generativos introducidos por Ian Goodfellow en 2014. Consisten en dos redes neuronales — el Generador y el Discriminador — entrenadas simultáneamente en un marco de teoría de juegos. El generador intenta producir datos que se asemejen a los datos reales, mientras que el discriminador intenta distinguir entre datos reales y datos generados.
Las GANs aprenden a generar muestras de datos a partir de ruido resolviendo un juego minimax. Durante el entrenamiento, el generador mejora en la producción de datos realistas y el discriminador mejora en distinguir entre datos reales y falsos.
Arquitectura de una GAN
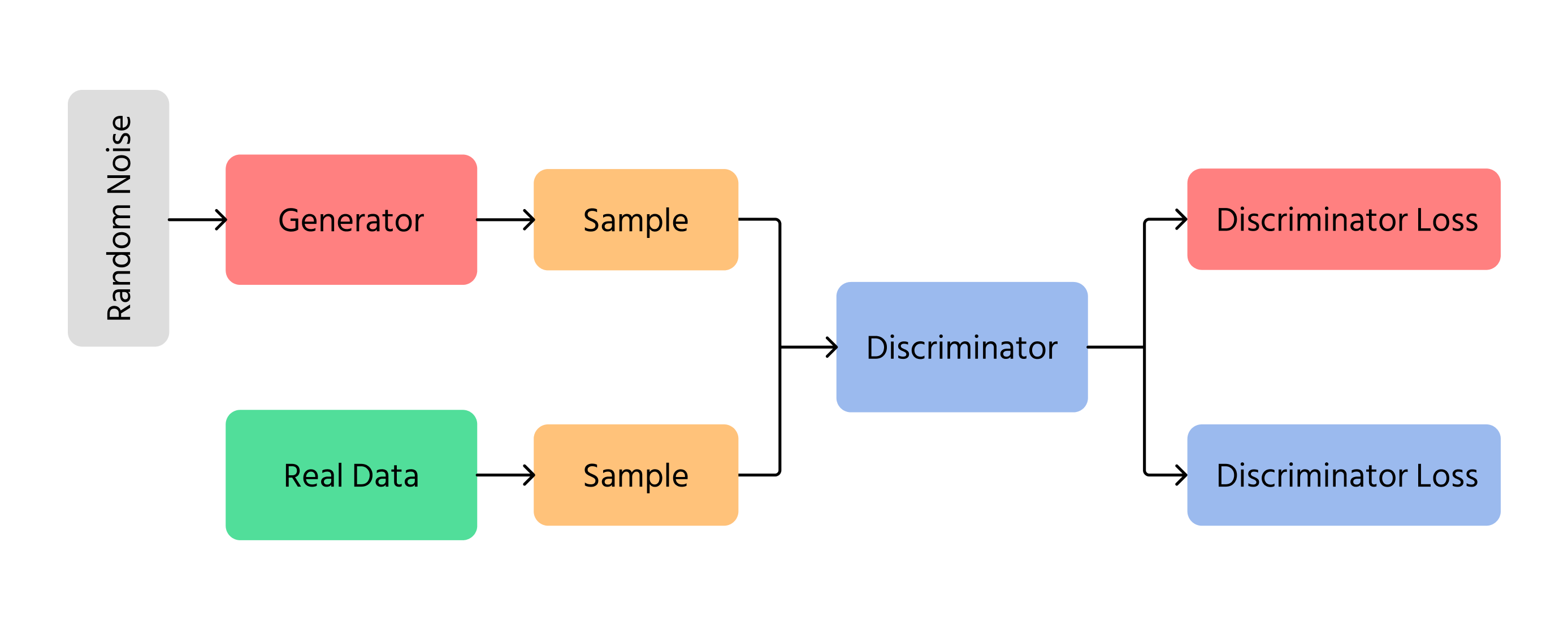
Un modelo GAN básico consta de dos componentes principales:
1. Generador (G)
- Recibe como entrada un vector de ruido aleatorio z∼pz(z);
- Lo transforma mediante una red neuronal en una muestra de datos G(z) destinada a parecerse a los datos de la distribución real.
2. Discriminador (D)
- Recibe como entrada una muestra de datos reales x∼px(x) o una muestra generada G(z);
- Produce un escalar entre 0 y 1, estimando la probabilidad de que la entrada sea real.
Estos dos componentes se entrenan simultáneamente. El generador busca producir muestras realistas para engañar al discriminador, mientras que el discriminador intenta identificar correctamente las muestras reales frente a las generadas.
Juego minimax de las GANs
En el núcleo de las GANs se encuentra el juego minimax, un concepto de la teoría de juegos. En este contexto:
- El generador G y el discriminador D son jugadores en competencia;
- D busca maximizar su capacidad para distinguir datos reales de los generados;
- G busca minimizar la capacidad de D para detectar sus datos falsos.
Esta dinámica define un juego de suma cero, donde la ganancia de un jugador es la pérdida del otro. La optimización se define como:
GminDmaxV(D,G)=Ex∼px[logD(x)]+Ez∼pz[log(1−D(G(z)))]El generador intenta engañar al discriminador generando muestras G(z) que sean lo más parecidas posible a los datos reales.
Funciones de pérdida
Aunque el objetivo original de las GAN define un juego minimax, en la práctica se utilizan funciones de pérdida alternativas para estabilizar el entrenamiento.
- Pérdida no saturante del generador:
Esto ayuda a que el generador reciba gradientes fuertes incluso cuando el discriminador tiene buen desempeño.
- Pérdida del discriminador:
Estas funciones de pérdida incentivan al generador a producir muestras que aumenten la incertidumbre del discriminador y mejoren la convergencia durante el entrenamiento.
Principales variantes de arquitecturas GAN
Han surgido varios tipos de GANs para abordar limitaciones específicas o mejorar el rendimiento:

GAN condicional (cGAN)
Los GANs condicionales amplían el marco estándar de los GANs al introducir información adicional (generalmente etiquetas) tanto en el generador como en el discriminador. En lugar de generar datos solo a partir de ruido aleatorio, el generador recibe tanto el ruido z como una condición y (por ejemplo, una etiqueta de clase). El discriminador también recibe y para juzgar si la muestra es realista bajo esa condición.
- Casos de uso: generación de imágenes condicionadas por clase, traducción de imagen a imagen, generación de texto a imagen.
GAN convolucional profundo (DCGAN)
Los DCGANs reemplazan las capas totalmente conectadas en los GANs originales por capas convolucionales y capas convolucionales transpuestas, lo que los hace más efectivos para la generación de imágenes. También introducen pautas arquitectónicas como eliminar capas totalmente conectadas, usar normalización por lotes y emplear activaciones ReLU/LeakyReLU.
- Casos de uso: generación de imágenes fotorrealistas, aprendizaje de representaciones visuales, aprendizaje no supervisado de características.
CycleGAN CycleGAN aborda el problema de la traducción de imágenes entre dominios sin pares. A diferencia de otros modelos que requieren conjuntos de datos emparejados (por ejemplo, la misma foto en dos estilos diferentes), CycleGAN puede aprender mapeos entre dos dominios sin ejemplos emparejados. Introduce dos generadores y dos discriminadores, cada uno responsable de mapear en una dirección (por ejemplo, de fotos a pinturas y viceversa), y aplica una pérdida de ciclo-consistencia para asegurar que traducir de un dominio y regresar al original recupere la imagen inicial. Esta pérdida es clave para preservar el contenido y la estructura.
La pérdida de ciclo-consistencia asegura:
GBA(GAB(x))≈x y GAB(GBA(y))≈ydonde:
- GAB mapea imágenes del dominio A al dominio B;
- GBA mapea del dominio B al dominio A.
- x∈A,y∈B.
Casos de uso: conversión de fotos a obras de arte, traducción de caballos a cebras, conversión de voz entre hablantes.
StyleGAN
StyleGAN, desarrollado por NVIDIA, introduce control basado en estilos en el generador. En lugar de alimentar un vector de ruido directamente al generador, este pasa por una red de mapeo para producir "vectores de estilo" que influyen en cada capa del generador. Esto permite un control detallado sobre características visuales como el color del cabello, expresiones faciales o iluminación.
Innovaciones destacadas:
- Mezcla de estilos, permite combinar múltiples códigos latentes;
- Normalización de instancia adaptativa (AdaIN), controla los mapas de características en el generador;
- Crecimiento progresivo, el entrenamiento comienza en baja resolución y aumenta con el tiempo.
Casos de uso: generación de imágenes de ultra alta resolución (por ejemplo, rostros), control de atributos visuales, generación artística.
Comparación: GANs vs VAEs
GANs son una potente clase de modelos generativos capaces de producir datos altamente realistas mediante un proceso de entrenamiento adversarial. Su núcleo radica en un juego minimax entre dos redes, utilizando funciones de pérdida adversarial para mejorar iterativamente ambos componentes. Un conocimiento sólido de su arquitectura, funciones de pérdida—incluyendo variantes como cGAN, DCGAN, CycleGAN y StyleGAN—y su contraste con otros modelos como los VAE proporciona a los profesionales la base necesaria para aplicaciones en campos como generación de imágenes, síntesis de video, aumento de datos y más.
1. ¿Cuál de las siguientes opciones describe mejor los componentes de una arquitectura básica de GAN?
2. ¿Cuál es el objetivo del juego minimax en las GANs?
3. ¿Cuál de las siguientes afirmaciones es verdadera sobre la diferencia entre GANs y VAEs?
¡Gracias por tus comentarios!
Pregunte a AI
Pregunte a AI

Pregunte lo que quiera o pruebe una de las preguntas sugeridas para comenzar nuestra charla
Redes Generativas Antagónicas (GANs)
Redes Generativas Antagónicas (GANs) son una clase de modelos generativos introducidos por Ian Goodfellow en 2014. Consisten en dos redes neuronales — el Generador y el Discriminador — entrenadas simultáneamente en un marco de teoría de juegos. El generador intenta producir datos que se asemejen a los datos reales, mientras que el discriminador intenta distinguir entre datos reales y datos generados.
Las GANs aprenden a generar muestras de datos a partir de ruido resolviendo un juego minimax. Durante el entrenamiento, el generador mejora en la producción de datos realistas y el discriminador mejora en distinguir entre datos reales y falsos.
Arquitectura de una GAN
Un modelo GAN básico consta de dos componentes principales:
1. Generador (G)
- Recibe como entrada un vector de ruido aleatorio z∼pz(z);
- Lo transforma mediante una red neuronal en una muestra de datos G(z) destinada a parecerse a los datos de la distribución real.
2. Discriminador (D)
- Recibe como entrada una muestra de datos reales x∼px(x) o una muestra generada G(z);
- Produce un escalar entre 0 y 1, estimando la probabilidad de que la entrada sea real.
Estos dos componentes se entrenan simultáneamente. El generador busca producir muestras realistas para engañar al discriminador, mientras que el discriminador intenta identificar correctamente las muestras reales frente a las generadas.
Juego minimax de las GANs
En el núcleo de las GANs se encuentra el juego minimax, un concepto de la teoría de juegos. En este contexto:
- El generador G y el discriminador D son jugadores en competencia;
- D busca maximizar su capacidad para distinguir datos reales de los generados;
- G busca minimizar la capacidad de D para detectar sus datos falsos.
Esta dinámica define un juego de suma cero, donde la ganancia de un jugador es la pérdida del otro. La optimización se define como:
GminDmaxV(D,G)=Ex∼px[logD(x)]+Ez∼pz[log(1−D(G(z)))]El generador intenta engañar al discriminador generando muestras G(z) que sean lo más parecidas posible a los datos reales.
Funciones de pérdida
Aunque el objetivo original de las GAN define un juego minimax, en la práctica se utilizan funciones de pérdida alternativas para estabilizar el entrenamiento.
- Pérdida no saturante del generador:
Esto ayuda a que el generador reciba gradientes fuertes incluso cuando el discriminador tiene buen desempeño.
- Pérdida del discriminador:
Estas funciones de pérdida incentivan al generador a producir muestras que aumenten la incertidumbre del discriminador y mejoren la convergencia durante el entrenamiento.
Principales variantes de arquitecturas GAN
Han surgido varios tipos de GANs para abordar limitaciones específicas o mejorar el rendimiento:
GAN condicional (cGAN)
Los GANs condicionales amplían el marco estándar de los GANs al introducir información adicional (generalmente etiquetas) tanto en el generador como en el discriminador. En lugar de generar datos solo a partir de ruido aleatorio, el generador recibe tanto el ruido z como una condición y (por ejemplo, una etiqueta de clase). El discriminador también recibe y para juzgar si la muestra es realista bajo esa condición.
- Casos de uso: generación de imágenes condicionadas por clase, traducción de imagen a imagen, generación de texto a imagen.
GAN convolucional profundo (DCGAN)
Los DCGANs reemplazan las capas totalmente conectadas en los GANs originales por capas convolucionales y capas convolucionales transpuestas, lo que los hace más efectivos para la generación de imágenes. También introducen pautas arquitectónicas como eliminar capas totalmente conectadas, usar normalización por lotes y emplear activaciones ReLU/LeakyReLU.
- Casos de uso: generación de imágenes fotorrealistas, aprendizaje de representaciones visuales, aprendizaje no supervisado de características.
CycleGAN CycleGAN aborda el problema de la traducción de imágenes entre dominios sin pares. A diferencia de otros modelos que requieren conjuntos de datos emparejados (por ejemplo, la misma foto en dos estilos diferentes), CycleGAN puede aprender mapeos entre dos dominios sin ejemplos emparejados. Introduce dos generadores y dos discriminadores, cada uno responsable de mapear en una dirección (por ejemplo, de fotos a pinturas y viceversa), y aplica una pérdida de ciclo-consistencia para asegurar que traducir de un dominio y regresar al original recupere la imagen inicial. Esta pérdida es clave para preservar el contenido y la estructura.
La pérdida de ciclo-consistencia asegura:
GBA(GAB(x))≈x y GAB(GBA(y))≈ydonde:
- GAB mapea imágenes del dominio A al dominio B;
- GBA mapea del dominio B al dominio A.
- x∈A,y∈B.
Casos de uso: conversión de fotos a obras de arte, traducción de caballos a cebras, conversión de voz entre hablantes.
StyleGAN
StyleGAN, desarrollado por NVIDIA, introduce control basado en estilos en el generador. En lugar de alimentar un vector de ruido directamente al generador, este pasa por una red de mapeo para producir "vectores de estilo" que influyen en cada capa del generador. Esto permite un control detallado sobre características visuales como el color del cabello, expresiones faciales o iluminación.
Innovaciones destacadas:
- Mezcla de estilos, permite combinar múltiples códigos latentes;
- Normalización de instancia adaptativa (AdaIN), controla los mapas de características en el generador;
- Crecimiento progresivo, el entrenamiento comienza en baja resolución y aumenta con el tiempo.
Casos de uso: generación de imágenes de ultra alta resolución (por ejemplo, rostros), control de atributos visuales, generación artística.
Comparación: GANs vs VAEs
GANs son una potente clase de modelos generativos capaces de producir datos altamente realistas mediante un proceso de entrenamiento adversarial. Su núcleo radica en un juego minimax entre dos redes, utilizando funciones de pérdida adversarial para mejorar iterativamente ambos componentes. Un conocimiento sólido de su arquitectura, funciones de pérdida—incluyendo variantes como cGAN, DCGAN, CycleGAN y StyleGAN—y su contraste con otros modelos como los VAE proporciona a los profesionales la base necesaria para aplicaciones en campos como generación de imágenes, síntesis de video, aumento de datos y más.
¡Gracias por tus comentarios!
