Implementación de Redes Neuronales
Descripción general de una red neuronal básica
Ahora has llegado a una etapa en la que cuentas con los conocimientos esenciales de TensorFlow para crear redes neuronales por tu cuenta. Aunque la mayoría de las redes neuronales en el mundo real son complejas y normalmente se construyen utilizando librerías de alto nivel como Keras, construiremos una básica utilizando herramientas fundamentales de TensorFlow. Este enfoque nos brinda experiencia práctica con la manipulación de tensores a bajo nivel, ayudándonos a comprender los procesos subyacentes.
En cursos anteriores como Introducción a las redes neuronales, quizá recuerdes el tiempo y esfuerzo que tomó construir incluso una red neuronal simple, tratando cada neurona de forma individual.

TensorFlow simplifica este proceso de manera significativa. Al aprovechar los tensores, puedes encapsular cálculos complejos, reduciendo la necesidad de codificación intrincada. Nuestra tarea principal es configurar una tubería secuencial de operaciones con tensores.
Aquí tienes un breve recordatorio de los pasos para poner en marcha el proceso de entrenamiento de una red neuronal:
Preparación de datos y creación del modelo
La fase inicial del entrenamiento de una red neuronal implica la preparación de los datos, que abarca tanto las entradas como las salidas de las que la red aprenderá. Además, se establecen los hiperparámetros del modelo; estos son los parámetros que permanecen constantes durante todo el proceso de entrenamiento. Los pesos se inicializan, normalmente tomados de una distribución normal, y los sesgos, que a menudo se establecen en cero.
Propagación hacia adelante
En la propagación hacia adelante, cada capa de la red normalmente sigue estos pasos:
- Multiplicar la entrada de la capa por sus pesos.
- Sumar un sesgo al resultado.
- Aplicar una función de activación a esta suma.
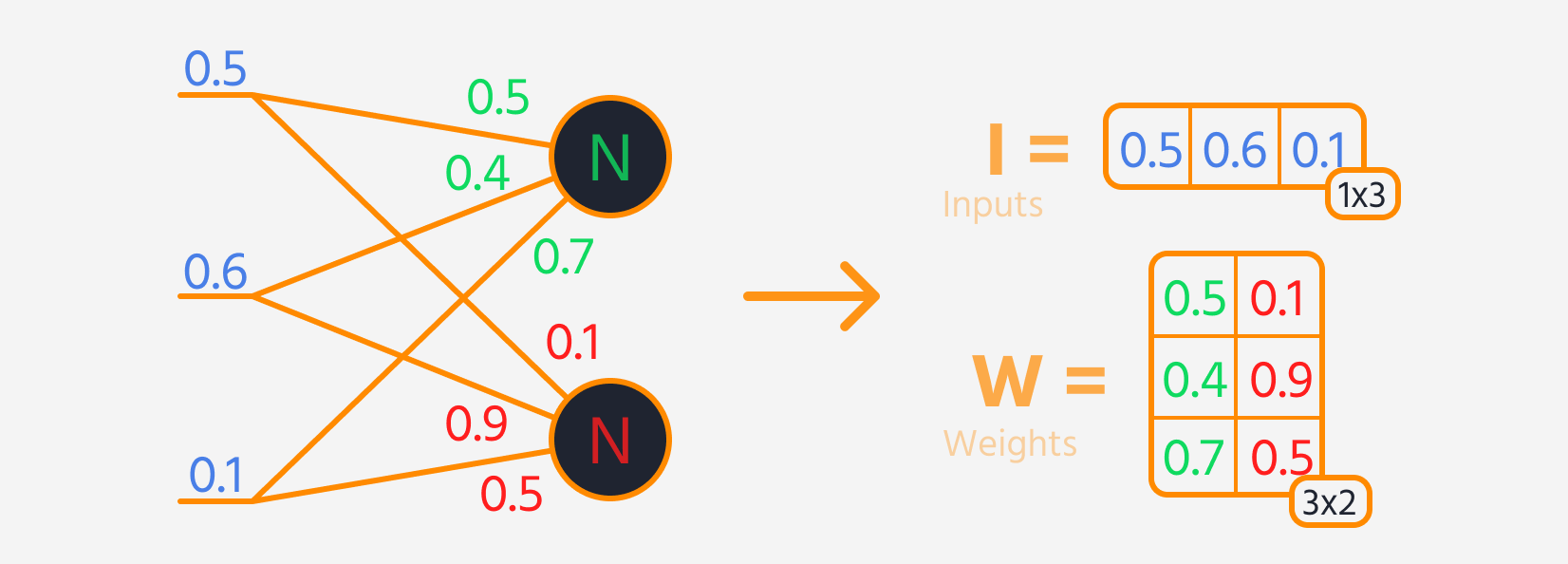
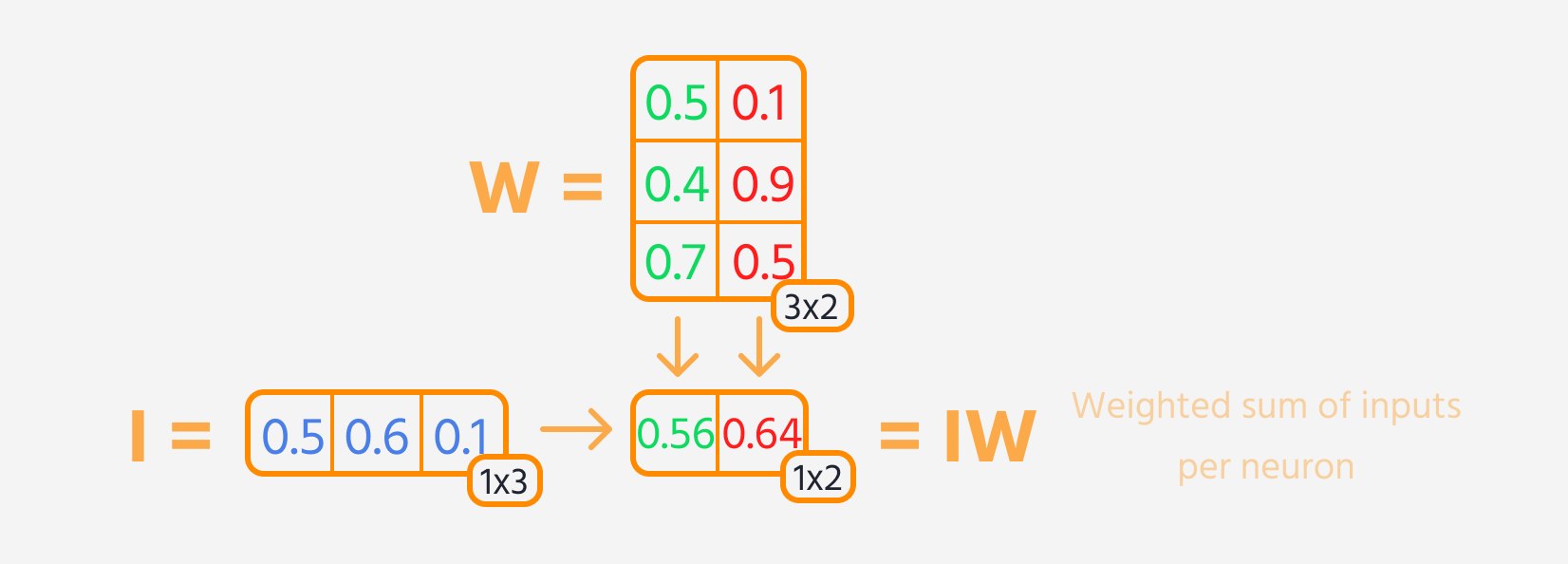
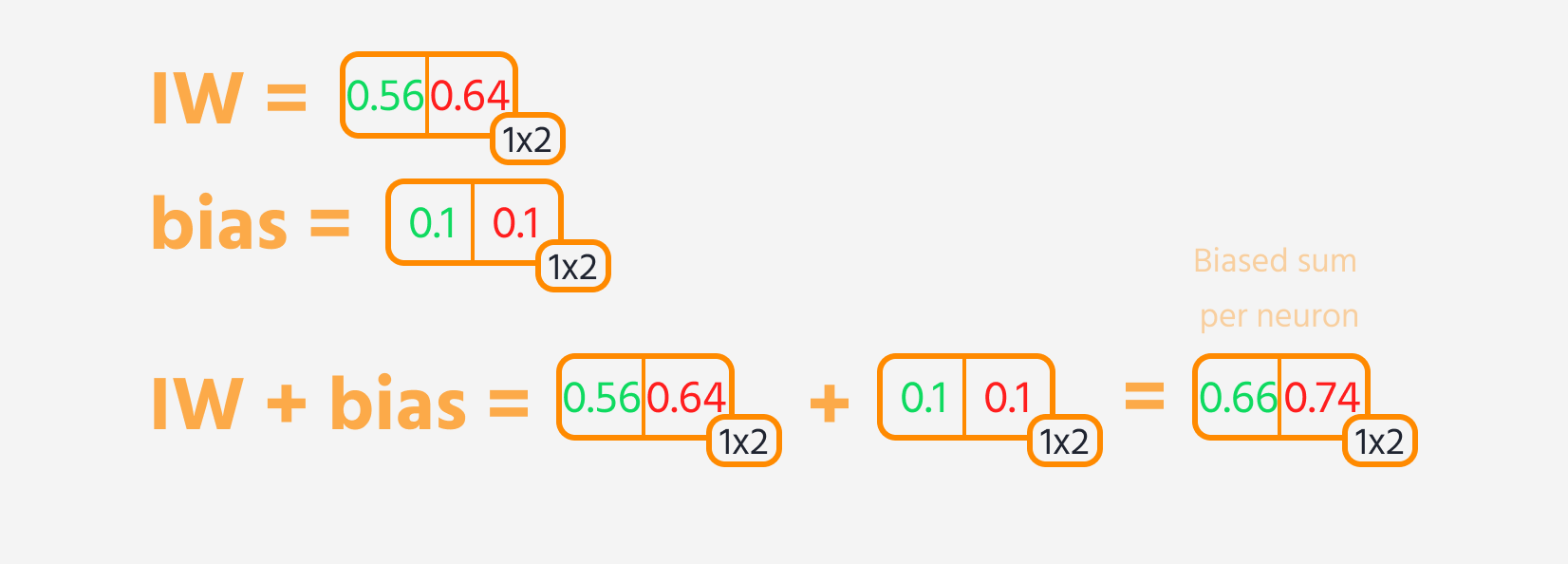


Luego, se puede calcular la pérdida.
Propagación hacia atrás
El siguiente paso es la propagación hacia atrás, donde se ajustan los pesos y sesgos según su influencia en la pérdida. Esta influencia está representada por el gradiente, que la Gradient Tape de TensorFlow calcula automáticamente. Se actualizan los pesos y sesgos restando el gradiente, escalado por la tasa de aprendizaje.
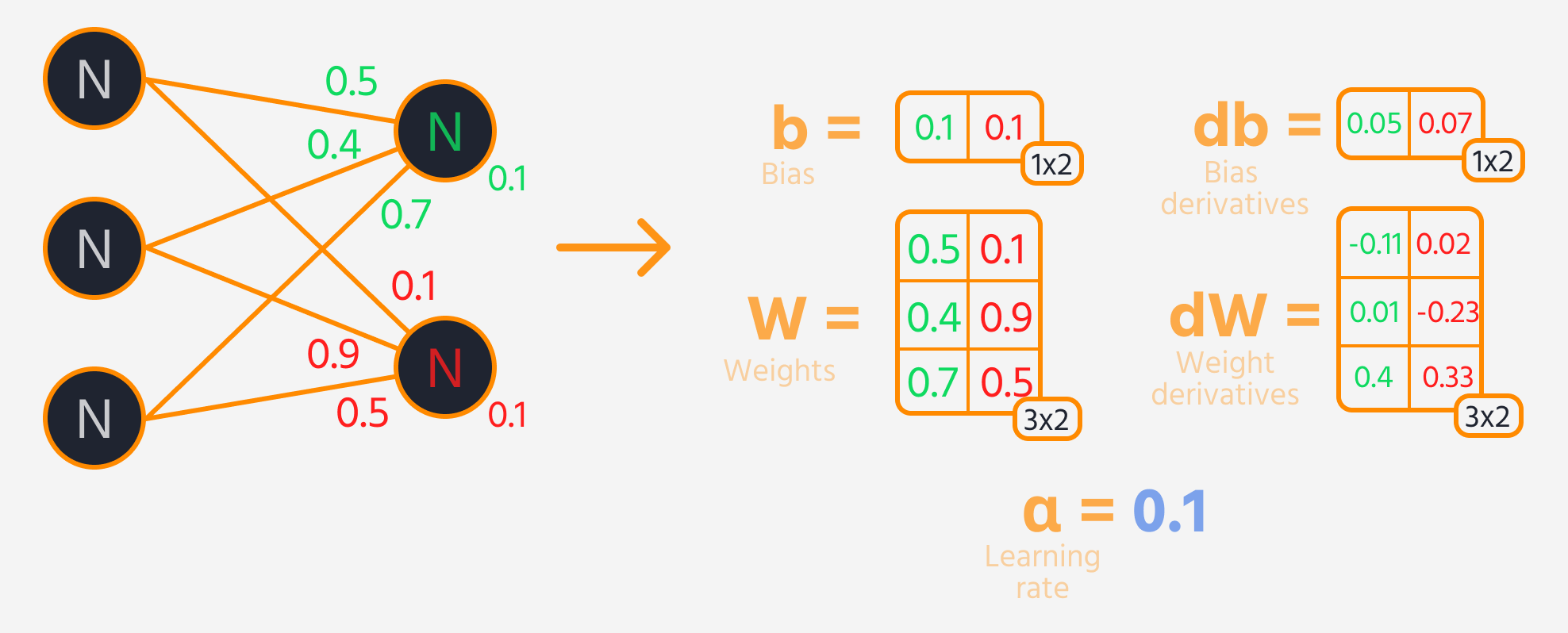
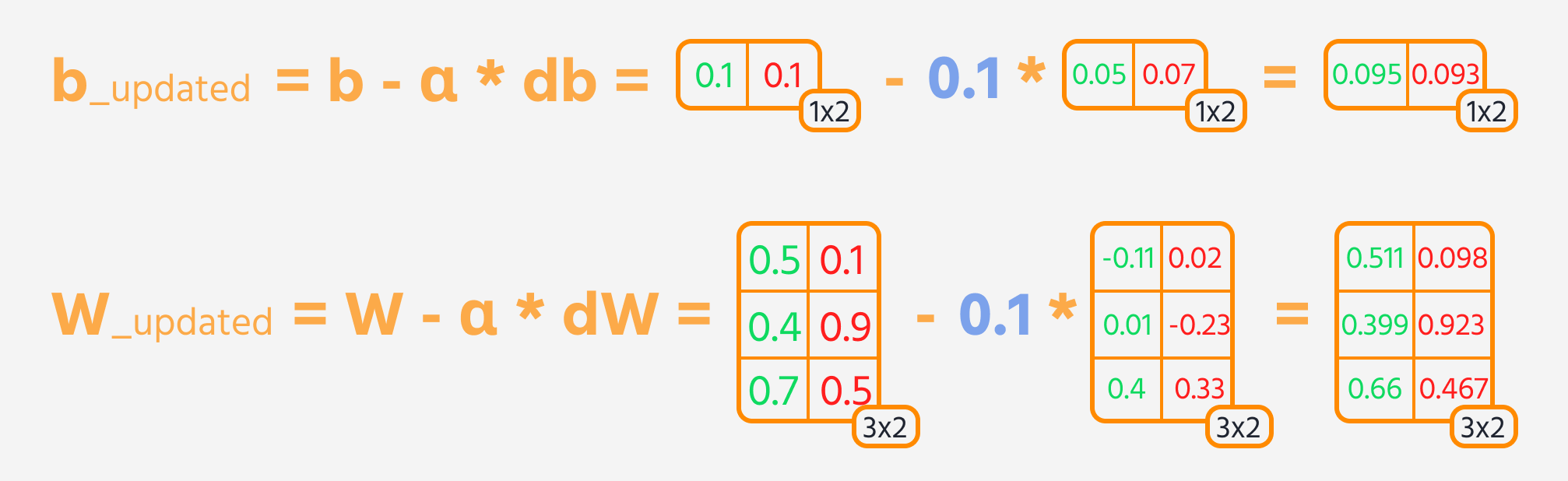
Bucle de entrenamiento
Para entrenar eficazmente la red neuronal, los pasos de entrenamiento se repiten varias veces mientras se supervisa el rendimiento del modelo. Idealmente, la pérdida debería disminuir a lo largo de las épocas.
¡Gracias por tus comentarios!
single
Implementación de Redes Neuronales
Desliza para mostrar el menú
Descripción general de una red neuronal básica
Ahora has llegado a una etapa en la que cuentas con los conocimientos esenciales de TensorFlow para crear redes neuronales por tu cuenta. Aunque la mayoría de las redes neuronales en el mundo real son complejas y normalmente se construyen utilizando librerías de alto nivel como Keras, construiremos una básica utilizando herramientas fundamentales de TensorFlow. Este enfoque nos brinda experiencia práctica con la manipulación de tensores a bajo nivel, ayudándonos a comprender los procesos subyacentes.
En cursos anteriores como Introducción a las redes neuronales, quizá recuerdes el tiempo y esfuerzo que tomó construir incluso una red neuronal simple, tratando cada neurona de forma individual.
TensorFlow simplifica este proceso de manera significativa. Al aprovechar los tensores, puedes encapsular cálculos complejos, reduciendo la necesidad de codificación intrincada. Nuestra tarea principal es configurar una tubería secuencial de operaciones con tensores.
Aquí tienes un breve recordatorio de los pasos para poner en marcha el proceso de entrenamiento de una red neuronal:
Preparación de datos y creación del modelo
La fase inicial del entrenamiento de una red neuronal implica la preparación de los datos, que abarca tanto las entradas como las salidas de las que la red aprenderá. Además, se establecen los hiperparámetros del modelo; estos son los parámetros que permanecen constantes durante todo el proceso de entrenamiento. Los pesos se inicializan, normalmente tomados de una distribución normal, y los sesgos, que a menudo se establecen en cero.
Propagación hacia adelante
En la propagación hacia adelante, cada capa de la red normalmente sigue estos pasos:
- Multiplicar la entrada de la capa por sus pesos.
- Sumar un sesgo al resultado.
- Aplicar una función de activación a esta suma.
Luego, se puede calcular la pérdida.
Propagación hacia atrás
El siguiente paso es la propagación hacia atrás, donde se ajustan los pesos y sesgos según su influencia en la pérdida. Esta influencia está representada por el gradiente, que la Gradient Tape de TensorFlow calcula automáticamente. Se actualizan los pesos y sesgos restando el gradiente, escalado por la tasa de aprendizaje.
Bucle de entrenamiento
Para entrenar eficazmente la red neuronal, los pasos de entrenamiento se repiten varias veces mientras se supervisa el rendimiento del modelo. Idealmente, la pérdida debería disminuir a lo largo de las épocas.
Desliza para comenzar a programar
Crear una red neuronal diseñada para predecir los resultados de la operación XOR. La red debe consistir en 2 neuronas de entrada, una capa oculta con 2 neuronas y 1 neurona de salida.
- Comenzar con la configuración de los pesos y sesgos iniciales. Los pesos deben inicializarse utilizando una distribución normal, y todos los sesgos deben inicializarse en cero. Utilizar los hiperparámetros
input_size,hidden_sizeyoutput_sizepara definir las formas adecuadas de estos tensores. - Utilizar un decorador de función para transformar la función
train_step()en un grafo de TensorFlow. - Realizar la propagación hacia adelante a través de las capas oculta y de salida de la red. Utilizar la función de activación sigmoide.
- Determinar los gradientes para comprender cómo cada peso y sesgo afecta la pérdida. Asegurarse de que los gradientes se calculen en el orden correcto, correspondiente a los nombres de las variables de salida.
- Modificar los pesos y sesgos en función de sus respectivos gradientes. Incorporar el
learning_rateen este proceso de ajuste para controlar la magnitud de cada actualización.
Solución
Preparación de datos
X_data: estos son los datos de entrada para la función XOR. Es un array de NumPy con forma (4, 2), que representa las cuatro combinaciones posibles de las entradas XOR (0,0), (0,1), (1,0) y (1,1);Y_data: este es el resultado objetivo para cada combinación de entrada enX_data. También es un array de NumPy pero con forma (4, 1), que representa la salida XOR para cada par de entradas.
Parámetros de la red
input_size: tamaño de la capa de entrada, establecido en 2, correspondiente a los dos nodos de entrada (para las dos entradas de la función XOR);hidden_size: tamaño de la capa oculta, también establecido en 2. Esta elección es algo arbitraria pero suficiente para aprender la función XOR;output_size: tamaño de la capa de salida, establecido en 1, correspondiente al único nodo de salida (el resultado de la operación XOR);learning_rate: tasa de aprendizaje para el algoritmo de optimización, que controla cuánto se ajustan los pesos durante el entrenamiento.
Pesos y sesgos
W1yb1: los pesos (W1) y sesgos (b1) para las conexiones desde la capa de entrada a la capa oculta.W1es una variable de TensorFlow inicializada con valores aleatorios y tiene una forma de(input_size, hidden_size), es decir,(2, 2).b1es una variable de TensorFlow inicializada en ceros y tiene una forma de(hidden_size), es decir,(2);W2yb2: los pesos (W2) y sesgos (b2) para las conexiones desde la capa oculta a la capa de salida.W2se inicializa con valores aleatorios y tiene una forma de(hidden_size, output_size), es decir,(2, 1).b2se inicializa en ceros y tiene una forma de(output_size), es decir,(1).
Función de entrenamiento
train_step(): esta es la función principal de entrenamiento. Utilizatf.GradientTape()para la diferenciación automática. En la pasada hacia adelante, calcula las activaciones de la capa oculta (a1) y las predicciones de salida (Y_pred). La pérdida se calcula como el error cuadrático medio entreY_predyY. Luego, la función calcula los gradientes y actualiza los pesos y sesgos;tf.sigmoid(): se utiliza una función de activación sigmoide, que transforma la entrada en un valor entre0y1. Se usa tanto para la capa oculta como para la capa de salida.
Bucle de entrenamiento
- La red se entrena durante
2500épocas. En cada época, se llama a la funcióntrain_step()y se actualizan los pesos. La pérdida se imprime cada500épocas para monitorear el progreso del entrenamiento.
Conclusión
Dado que la función XOR es una tarea relativamente sencilla, no es necesario utilizar técnicas avanzadas como ajuste de hiperparámetros, división de conjuntos de datos o construcción de canalizaciones de datos complejas en esta etapa. Este ejercicio es solo un paso hacia la construcción de redes neuronales más sofisticadas para aplicaciones del mundo real.
Dominar estos conceptos básicos es fundamental antes de abordar técnicas avanzadas de construcción de redes neuronales en los próximos cursos, donde se utilizará la librería Keras y se explorarán métodos para mejorar la calidad del modelo con las amplias funcionalidades de TensorFlow.
¡Gracias por tus comentarios!
single
Pregunte a AI
Pregunte a AI

Pregunte lo que quiera o pruebe una de las preguntas sugeridas para comenzar nuestra charla
