Introducción a las Redes Neuronales Convolucionales
Desliza para mostrar el menú
¿Qué es una CNN y en qué se diferencia de las redes neuronales tradicionales?
Una red neuronal convolucional (CNN) es un tipo de inteligencia artificial que ayuda a las computadoras a "ver" y comprender imágenes. A diferencia de las redes neuronales tradicionales que procesan imágenes como una lista de números, las CNN analizan las imágenes por secciones, reconociendo patrones como bordes, formas y texturas. Esto las hace mucho más eficaces para trabajar con imágenes y videos.
Cómo las CNN se inspiran en el ojo humano
Las CNN funcionan de manera similar a cómo el cerebro humano procesa las imágenes. Cuando observamos algo, nuestros ojos envían información al cerebro, que primero reconoce formas simples como bordes y colores. Luego, las capas más profundas de nuestro cerebro combinan estas piezas para comprender objetos, rostros o escenas completas. Las CNN siguen la misma idea, comenzando con características simples y avanzando hasta reconocer objetos complejos.
Al igual que nuestros ojos se enfocan en ciertas áreas, las CNN también procesan imágenes en pequeñas secciones, lo que les ayuda a reconocer patrones sin importar dónde aparezcan. Sin embargo, a diferencia de los humanos, las CNN necesitan miles de imágenes etiquetadas para aprender, mientras que las personas pueden reconocer objetos incluso si solo los han visto unas pocas veces.
Descripción general de los componentes clave: convolución, agrupamiento, activación y capas totalmente conectadas
Una CNN consta de múltiples capas, cada una desempeñando un papel distinto en el procesamiento de imágenes:
- Aplicación de filtros (kernels) para detectar patrones como bordes, texturas y formas;
- Uso de stride y padding para controlar las dimensiones del mapa de características;
- Generación de múltiples mapas de características para una extracción profunda de características.
- Introducción de no linealidad, permitiendo que las CNN aprendan representaciones complejas;
- Funciones comunes incluyen ReLU (Unidad Lineal Rectificada), Leaky ReLU y Sigmoid.
- Reducción de las dimensiones espaciales de los mapas de características mientras se preserva la información importante;
- Tipos incluyen max pooling (captura características dominantes) y average pooling (suaviza representaciones);
- Contribuye a la invarianza ante traslaciones y eficiencia computacional.
- Aplanamiento de los mapas de características en un vector 1D para clasificación;
- Conexión a una capa de salida final usando Softmax (para clasificación multiclase) o Sigmoid (para clasificación binaria).
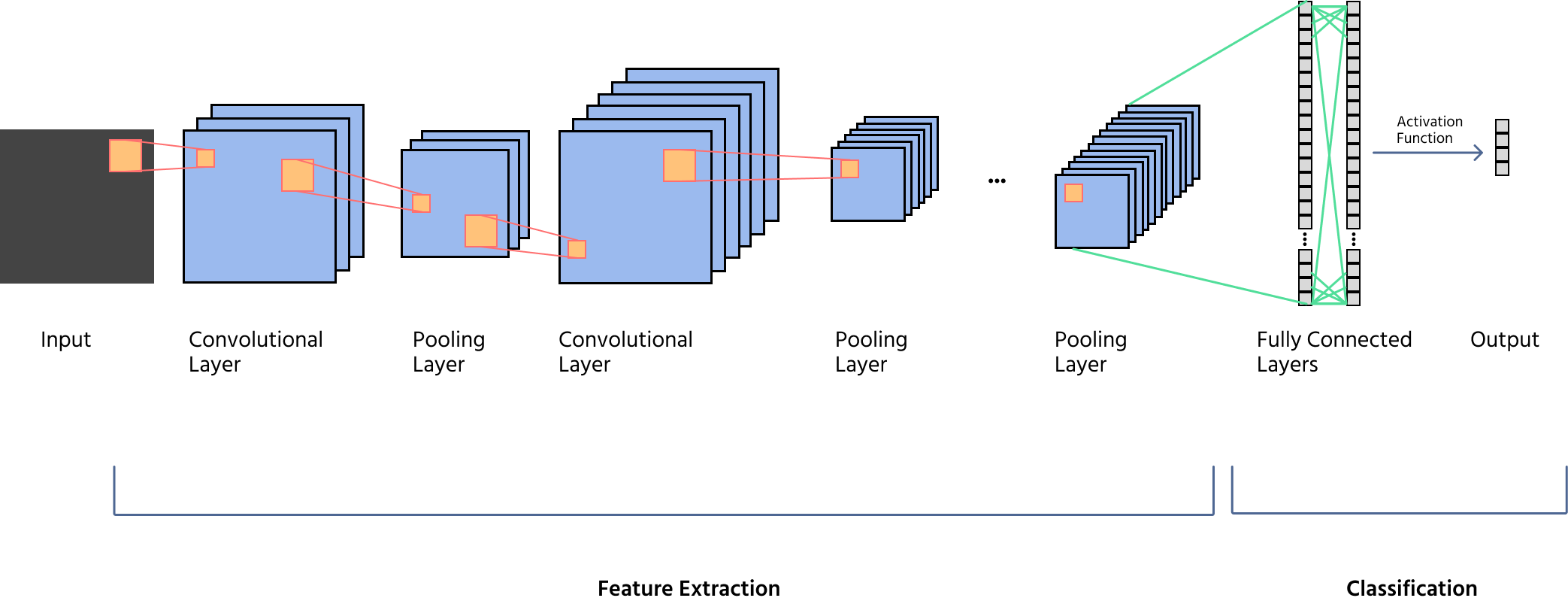
Las CNN son potentes porque pueden aprender automáticamente características a partir de imágenes en lugar de requerir que los humanos programen cada detalle. Por eso se utilizan en coches autónomos, reconocimiento facial, imágenes médicas y muchas otras aplicaciones del mundo real.
1. ¿Cuál es la principal ventaja de las CNN sobre las redes neuronales tradicionales al procesar imágenes?
2. Relaciona el elemento de la CNN con su función.
¡Gracias por tus comentarios!
Pregunte a AI
Pregunte a AI

Pregunte lo que quiera o pruebe una de las preguntas sugeridas para comenzar nuestra charla
Introducción a las Redes Neuronales Convolucionales
¿Qué es una CNN y en qué se diferencia de las redes neuronales tradicionales?
Una red neuronal convolucional (CNN) es un tipo de inteligencia artificial que ayuda a las computadoras a "ver" y comprender imágenes. A diferencia de las redes neuronales tradicionales que procesan imágenes como una lista de números, las CNN analizan las imágenes por secciones, reconociendo patrones como bordes, formas y texturas. Esto las hace mucho más eficaces para trabajar con imágenes y videos.
Cómo las CNN se inspiran en el ojo humano
Las CNN funcionan de manera similar a cómo el cerebro humano procesa las imágenes. Cuando observamos algo, nuestros ojos envían información al cerebro, que primero reconoce formas simples como bordes y colores. Luego, las capas más profundas de nuestro cerebro combinan estas piezas para comprender objetos, rostros o escenas completas. Las CNN siguen la misma idea, comenzando con características simples y avanzando hasta reconocer objetos complejos.
Al igual que nuestros ojos se enfocan en ciertas áreas, las CNN también procesan imágenes en pequeñas secciones, lo que les ayuda a reconocer patrones sin importar dónde aparezcan. Sin embargo, a diferencia de los humanos, las CNN necesitan miles de imágenes etiquetadas para aprender, mientras que las personas pueden reconocer objetos incluso si solo los han visto unas pocas veces.
Descripción general de los componentes clave: convolución, agrupamiento, activación y capas totalmente conectadas
Una CNN consta de múltiples capas, cada una desempeñando un papel distinto en el procesamiento de imágenes:
- Aplicación de filtros (kernels) para detectar patrones como bordes, texturas y formas;
- Uso de stride y padding para controlar las dimensiones del mapa de características;
- Generación de múltiples mapas de características para una extracción profunda de características.
- Introducción de no linealidad, permitiendo que las CNN aprendan representaciones complejas;
- Funciones comunes incluyen ReLU (Unidad Lineal Rectificada), Leaky ReLU y Sigmoid.
- Reducción de las dimensiones espaciales de los mapas de características mientras se preserva la información importante;
- Tipos incluyen max pooling (captura características dominantes) y average pooling (suaviza representaciones);
- Contribuye a la invarianza ante traslaciones y eficiencia computacional.
- Aplanamiento de los mapas de características en un vector 1D para clasificación;
- Conexión a una capa de salida final usando Softmax (para clasificación multiclase) o Sigmoid (para clasificación binaria).
Las CNN son potentes porque pueden aprender automáticamente características a partir de imágenes en lugar de requerir que los humanos programen cada detalle. Por eso se utilizan en coches autónomos, reconocimiento facial, imágenes médicas y muchas otras aplicaciones del mundo real.
¡Gracias por tus comentarios!
