Visión General de los Modelos CNN Populares
Desliza para mostrar el menú
Las redes neuronales convolucionales (CNN) han evolucionado significativamente, con diversas arquitecturas que mejoran la precisión, eficiencia y escalabilidad. Este capítulo explora cinco modelos clave de CNN que han marcado el aprendizaje profundo: LeNet, AlexNet, VGGNet, ResNet e InceptionNet.
LeNet: La base de las CNN
Una de las primeras arquitecturas de redes neuronales convolucionales, propuesta por Yann LeCun en 1998 para el reconocimiento de dígitos manuscritos. Sentó las bases de las CNN modernas al introducir componentes clave como convoluciones, agrupamiento y capas completamente conectadas. Puede obtener más información sobre el modelo en la documentación.
Características clave de la arquitectura
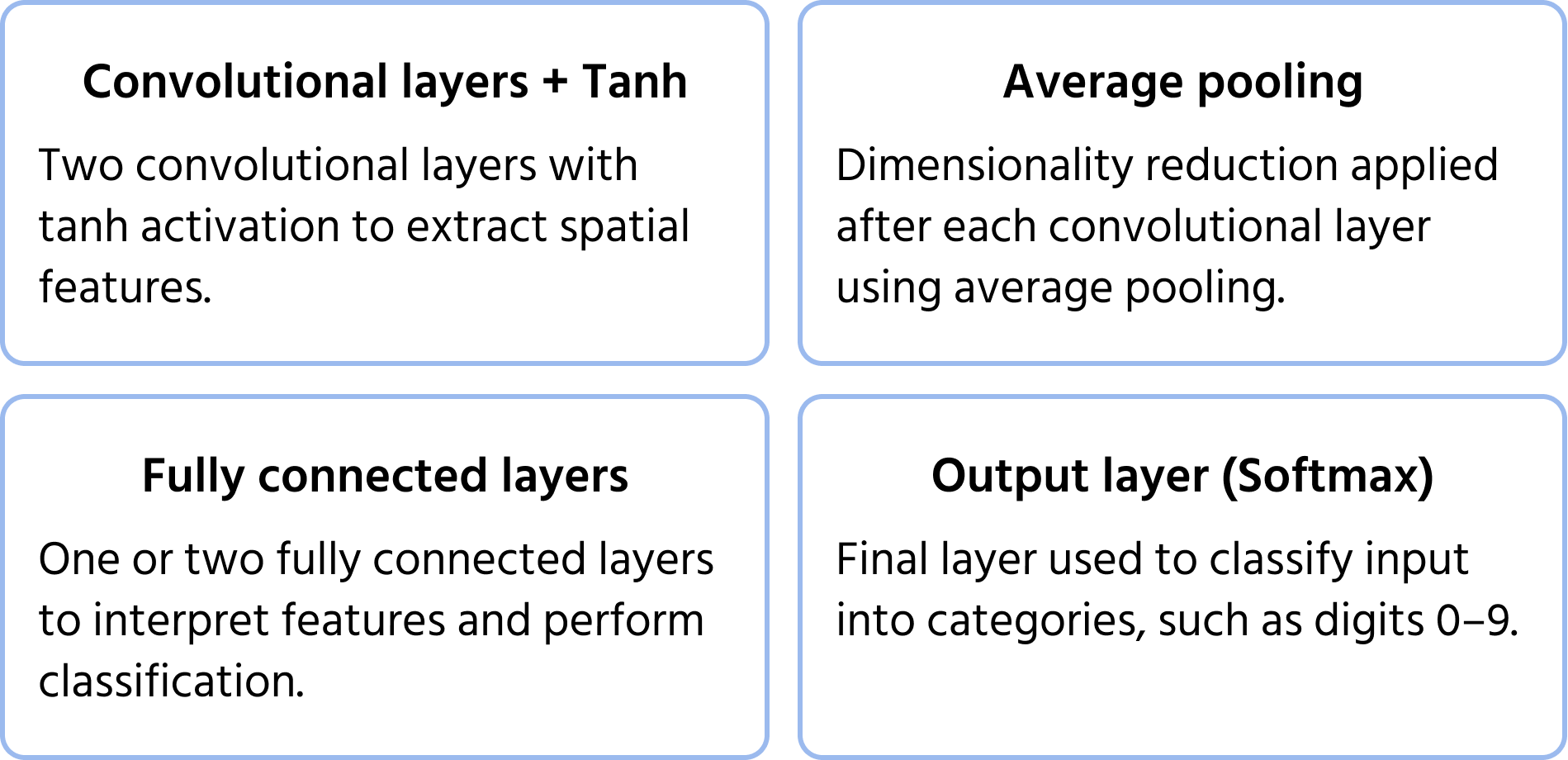
AlexNet: Avance en Aprendizaje Profundo
Una arquitectura de CNN emblemática que ganó la competencia ImageNet en 2012, AlexNet demostró que las redes convolucionales profundas podían superar significativamente a los métodos tradicionales de aprendizaje automático en la clasificación de imágenes a gran escala. Introdujo innovaciones que se convirtieron en estándar en el aprendizaje profundo moderno. Puede obtener más información sobre el modelo en la documentación.
Características Clave de la Arquitectura
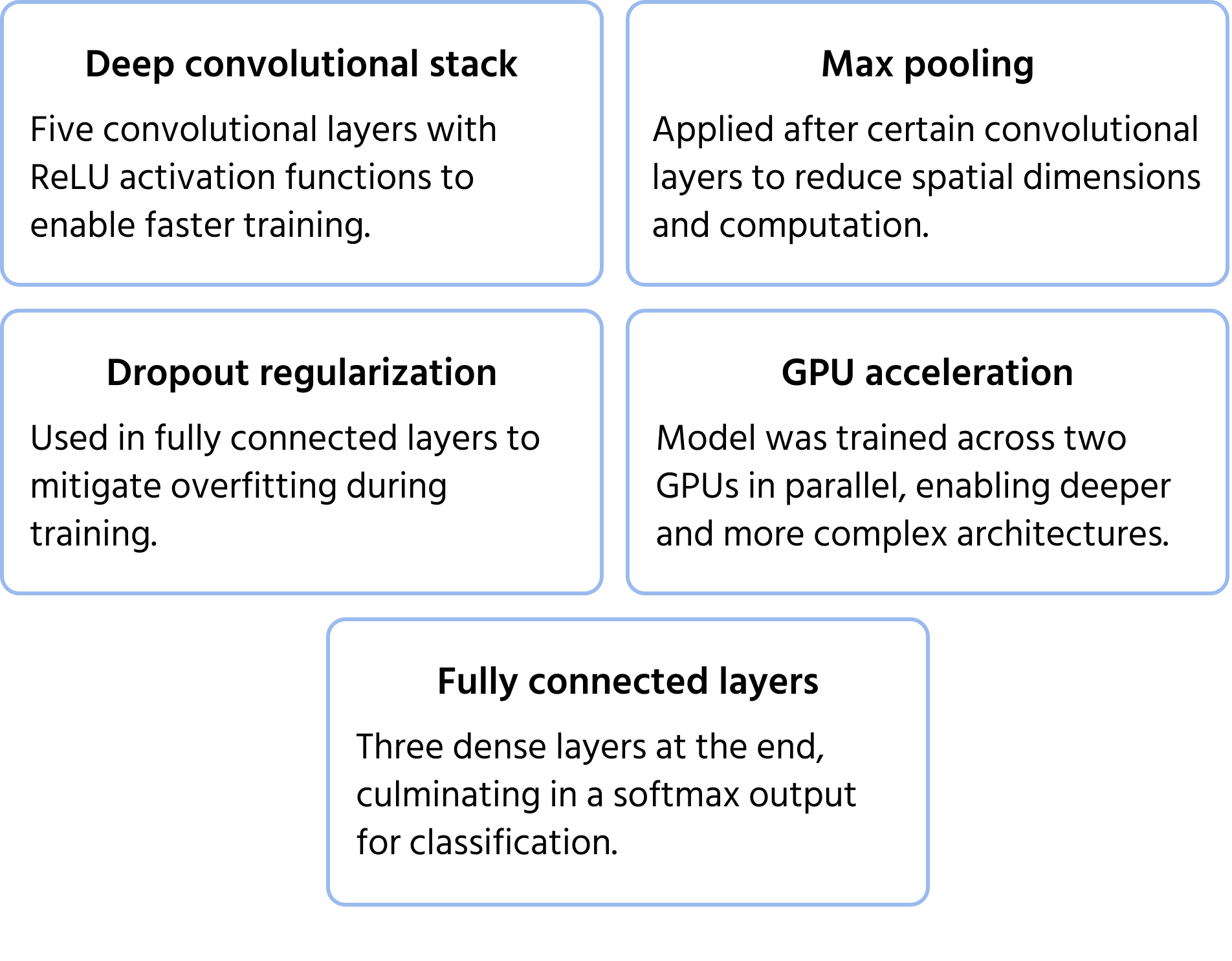
VGGNet: Redes más profundas con filtros uniformes
Desarrollada por el Visual Geometry Group de Oxford, VGGNet enfatizó la profundidad y la simplicidad mediante el uso de filtros convolucionales uniformes de 3×3. Demostró que apilar filtros pequeños en redes profundas podía mejorar significativamente el rendimiento, lo que llevó a variantes ampliamente utilizadas como VGG-16 y VGG-19. Puede obtener más información sobre el modelo en la documentación.
Características clave de la arquitectura
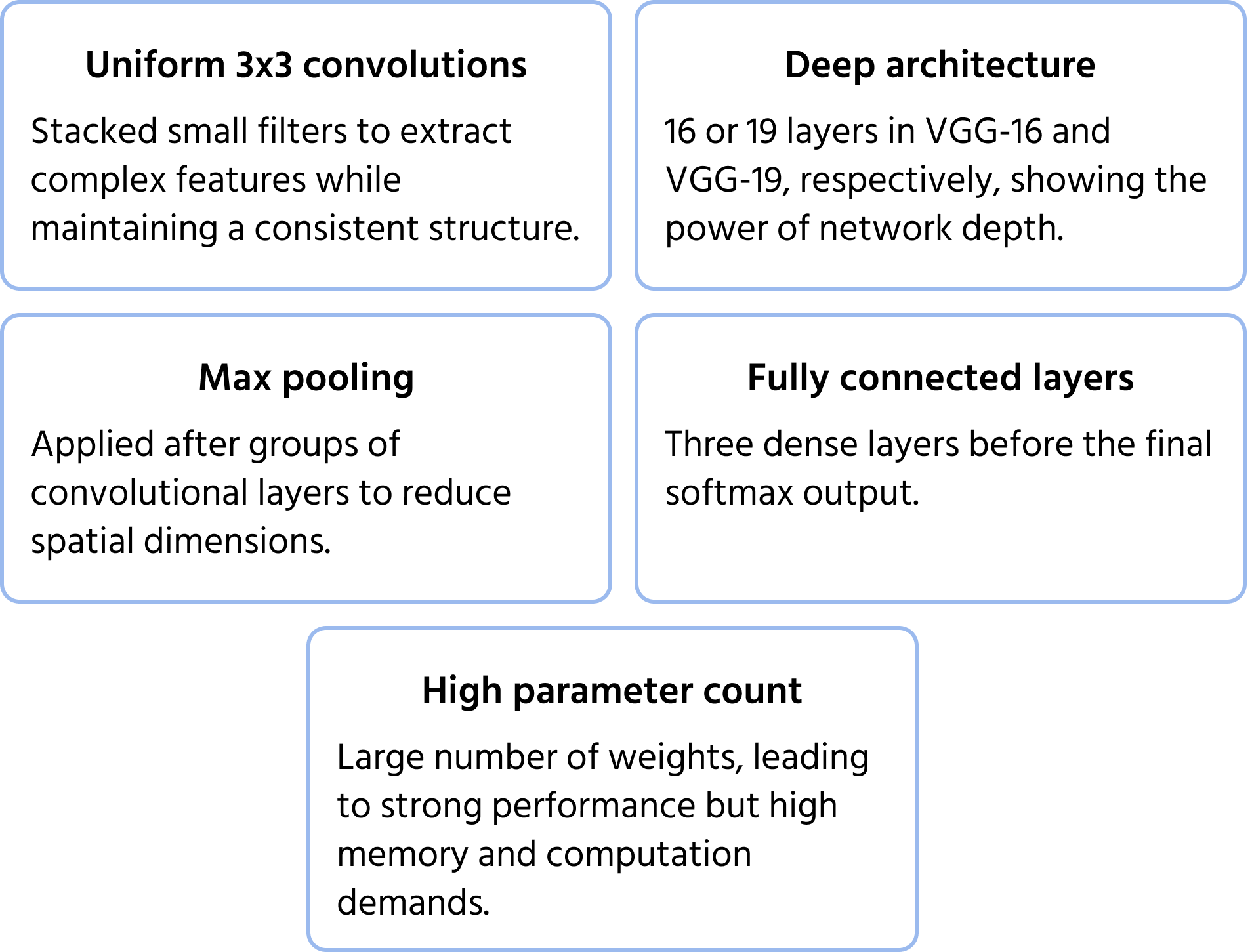
ResNet: Resolución del Problema de Profundidad
ResNet (Redes Residuales), introducida por Microsoft en 2015, abordó el problema del desvanecimiento del gradiente, que ocurre al entrenar redes muy profundas. Las redes profundas tradicionales presentan dificultades en la eficiencia del entrenamiento y degradación del rendimiento, pero ResNet superó este inconveniente mediante conexiones de salto (aprendizaje residual). Estos atajos permiten que la información omita ciertas capas, asegurando que los gradientes sigan propagándose de manera efectiva. Las arquitecturas ResNet, como ResNet-50 y ResNet-101, permitieron el entrenamiento de redes con cientos de capas, mejorando significativamente la precisión en la clasificación de imágenes. Puede obtener más información sobre el modelo en la documentación.
Características Clave de la Arquitectura
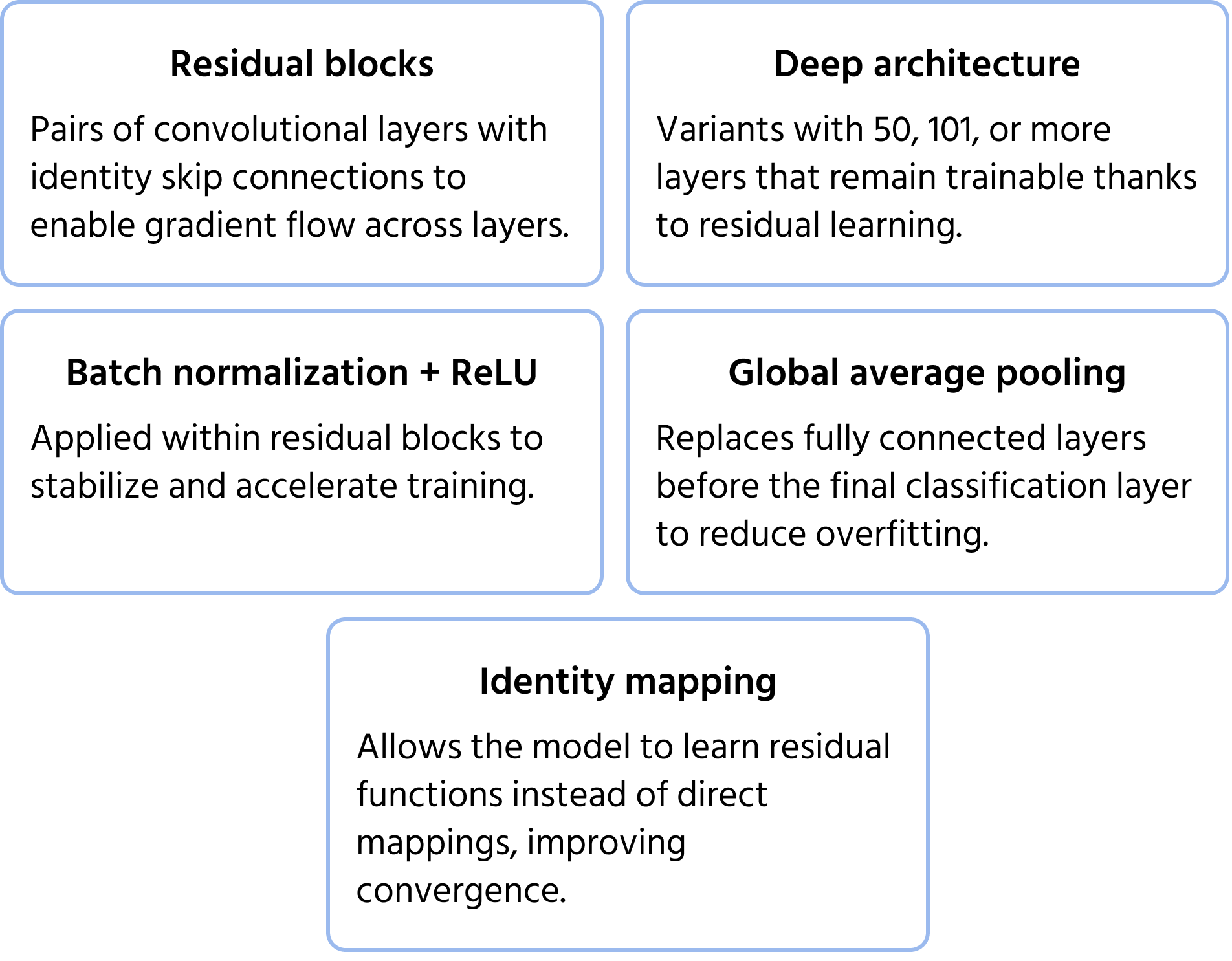
InceptionNet: Extracción de Características a Múltiples Escalas
InceptionNet (también conocido como GoogLeNet) se basa en el módulo de inception para crear una arquitectura profunda pero eficiente. En lugar de apilar capas de forma secuencial, InceptionNet utiliza rutas paralelas para extraer características en diferentes niveles. Puede obtener más información sobre el modelo en la documentación.
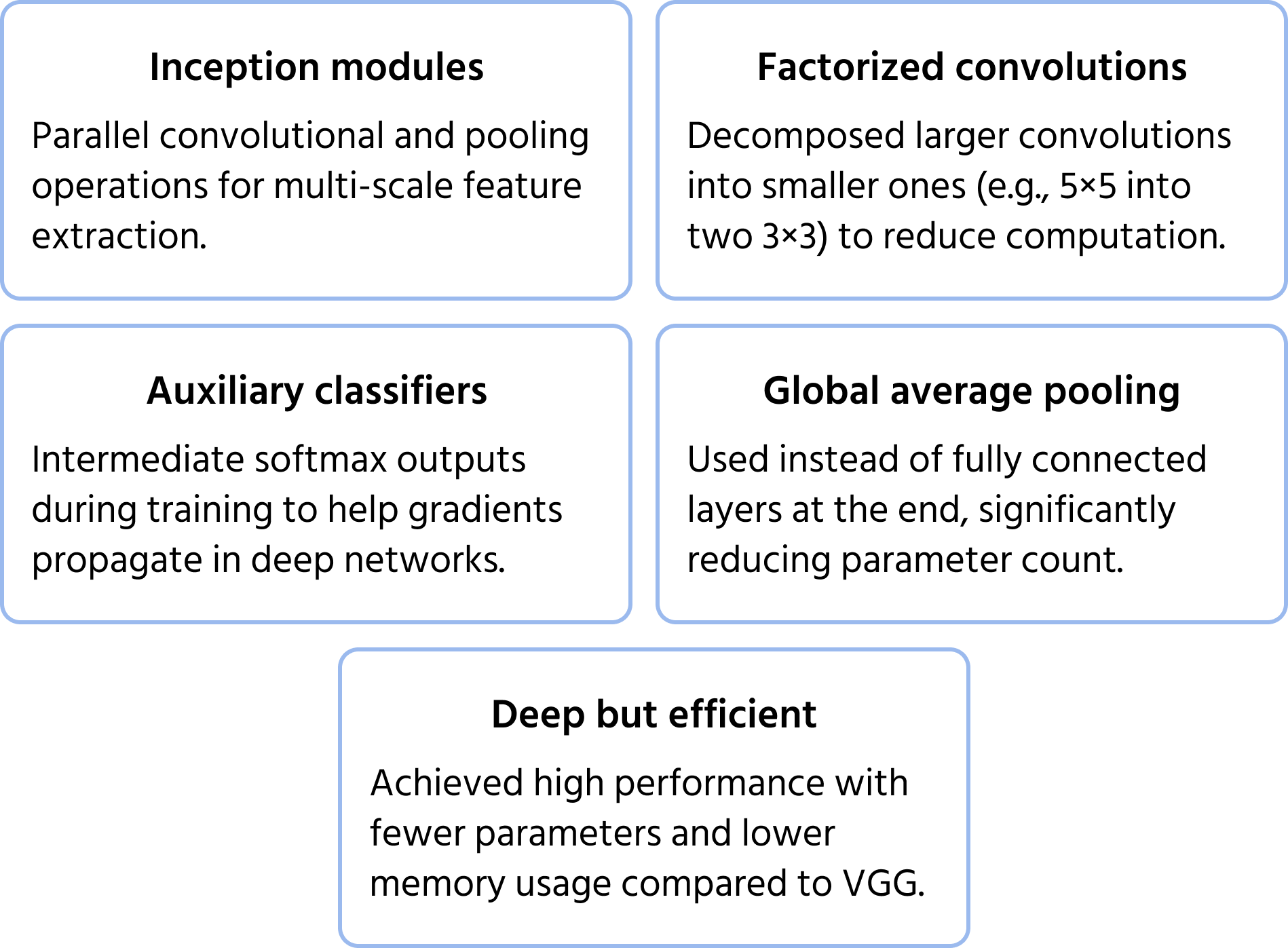
Las principales optimizaciones incluyen:
- Convoluciones factorizadas para reducir el coste computacional;
- Clasificadores auxiliares en capas intermedias para mejorar la estabilidad del entrenamiento;
- Agrupamiento promedio global en lugar de capas completamente conectadas, lo que reduce el número de parámetros manteniendo el rendimiento.
Esta estructura permite que InceptionNet sea más profundo que CNNs anteriores como VGG, sin aumentar drásticamente los requisitos computacionales.
Características Clave de la Arquitectura
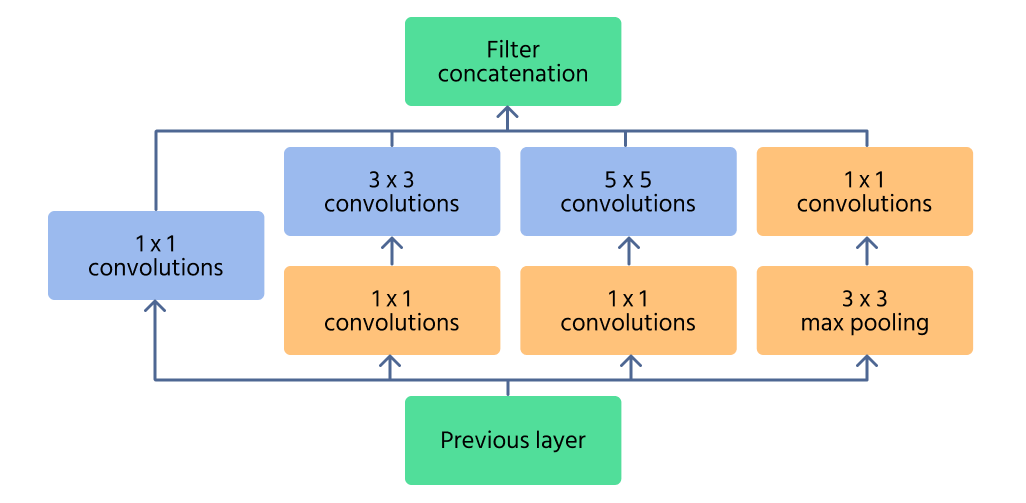
Módulo Inception
El módulo Inception es el componente principal de InceptionNet, diseñado para capturar características de manera eficiente en múltiples escalas. En lugar de aplicar una sola operación de convolución, el módulo procesa la entrada con múltiples tamaños de filtro (1×1, 3×3, 5×5) en paralelo. Esto permite que la red reconozca tanto detalles finos como patrones grandes en una imagen.
Para reducir el costo computacional, se utilizan 1×1 convolutions antes de aplicar filtros más grandes. Estas reducen la cantidad de canales de entrada, haciendo la red más eficiente. Además, las capas de max pooling dentro del módulo ayudan a retener características esenciales mientras controlan la dimensionalidad.
Ejemplo
Considere un ejemplo para observar cómo la reducción de dimensiones disminuye la carga computacional. Suponga que se necesita convolucionar 28 × 28 × 192 input feature maps con 5 × 5 × 32 filters. Esta operación requeriría aproximadamente 120,42 millones de cálculos.

Number of operations = (2828192) * (5532) = 120,422,400 operations
Realicemos los cálculos nuevamente, pero esta vez, coloque una 1×1 convolutional layer antes de aplicar la 5×5 convolution a los mismos mapas de características de entrada.

Number of operations for 1x1 convolution = (2828192) * (1116) = 2,408,448 operations
Number of operations for 5x5 convolution = (282816) * (5532) = 10,035,200 operations
Total number of operations 2,408,448 + 10,035,200 = 12,443,648 operations
Cada una de estas arquitecturas de CNN ha desempeñado un papel fundamental en el avance de la visión por computadora, influyendo en aplicaciones en salud, sistemas autónomos, seguridad y procesamiento de imágenes en tiempo real. Desde los principios fundamentales de LeNet hasta la extracción de características a múltiples escalas de InceptionNet, estos modelos han impulsado continuamente los límites del aprendizaje profundo, allanando el camino para arquitecturas aún más avanzadas en el futuro.
1. ¿Cuál fue la innovación principal introducida por ResNet que permitió entrenar redes extremadamente profundas?
2. ¿Cómo mejora InceptionNet la eficiencia computacional en comparación con las CNN tradicionales?
3. ¿Qué arquitectura de CNN introdujo por primera vez el concepto de utilizar pequeños filtros de convolución de 3×3 en toda la red?
¡Gracias por tus comentarios!
Pregunte a AI
Pregunte a AI

Pregunte lo que quiera o pruebe una de las preguntas sugeridas para comenzar nuestra charla
