Funciones de Activación
Desliza para mostrar el menú
Por qué las funciones de activación son cruciales en las CNN
Las funciones de activación introducen no linealidad en las CNN, permitiéndoles aprender patrones complejos más allá de lo que puede lograr un modelo lineal simple. Sin funciones de activación, las CNN tendrían dificultades para detectar relaciones intrincadas en los datos, limitando su eficacia en el reconocimiento y la clasificación de imágenes. La función de activación adecuada influye en la velocidad de entrenamiento, la estabilidad y el rendimiento general.
Funciones de activación comunes
- ReLU (unidad lineal rectificada): la función de activación más utilizada en las CNN. Solo permite pasar valores positivos mientras establece todos los valores negativos en cero, lo que la hace computacionalmente eficiente y previene el problema de gradientes que desaparecen. Sin embargo, algunas neuronas pueden volverse inactivas debido al problema de "ReLU muerta";

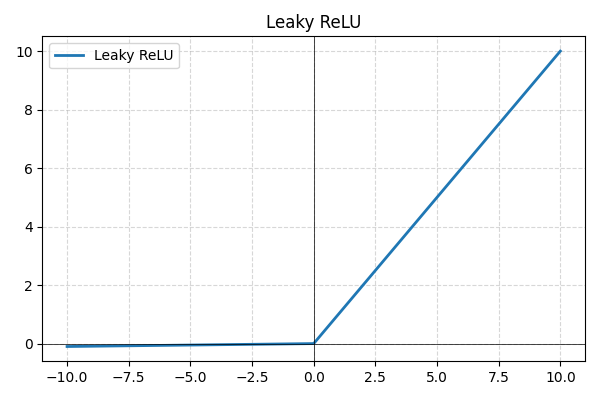
- Leaky ReLU: una variación de ReLU que permite pequeños valores negativos en lugar de establecerlos en cero, evitando neuronas inactivas y mejorando el flujo del gradiente;
- Sigmoide: comprime los valores de entrada en un rango entre 0 y 1, lo que lo hace útil para la clasificación binaria. Sin embargo, presenta el problema de gradientes que desaparecen en redes profundas;

- Tanh: similar a la función sigmoide, pero produce valores entre -1 y 1, centrando las activaciones alrededor de cero;

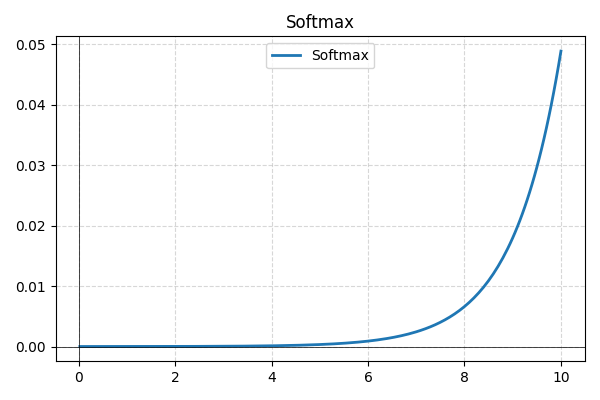
- Softmax: normalmente utilizada en la capa final para clasificación multiclase, Softmax convierte las salidas brutas de la red en probabilidades, asegurando que sumen uno para una mejor interpretabilidad.
Elección de la Función de Activación Adecuada
ReLU es la opción predeterminada para las capas ocultas debido a su eficiencia y alto rendimiento, mientras que Leaky ReLU es una mejor alternativa cuando surge el problema de inactividad neuronal. Sigmoid y Tanh generalmente se evitan en redes neuronales convolucionales profundas, pero pueden ser útiles en aplicaciones específicas. Softmax sigue siendo esencial para tareas de clasificación multiclase, asegurando predicciones claras basadas en probabilidades.
Seleccionar la función de activación adecuada es clave para optimizar el rendimiento de las CNN, equilibrando la eficiencia y previniendo problemas como los gradientes que desaparecen o explotan. Cada función contribuye de manera única a cómo una red procesa y aprende de los datos visuales.
1. ¿Por qué se prefiere ReLU sobre Sigmoid en las CNN profundas?
2. ¿Qué función de activación se utiliza comúnmente en la capa final de una CNN para clasificación multiclase?
3. ¿Cuál es la principal ventaja de Leaky ReLU sobre la ReLU estándar?
¡Gracias por tus comentarios!
Pregunte a AI
Pregunte a AI

Pregunte lo que quiera o pruebe una de las preguntas sugeridas para comenzar nuestra charla
