Visión General de la Generación de Imágenes
Desliza para mostrar el menú
Las imágenes generadas por IA están transformando la manera en que las personas crean arte, diseño y contenido digital. Con la ayuda de la inteligencia artificial, las computadoras ahora pueden crear imágenes realistas, potenciar el trabajo creativo e incluso apoyar a las empresas. En este capítulo, exploraremos cómo la IA genera imágenes, los diferentes tipos de modelos de generación de imágenes y sus aplicaciones en la vida real.
Cómo la IA genera imágenes
La generación de imágenes por IA funciona aprendiendo a partir de una gran colección de imágenes. La IA estudia los patrones en las imágenes y luego crea nuevas que se parecen a las originales. Esta tecnología ha mejorado mucho a lo largo de los años, produciendo imágenes cada vez más realistas y creativas. Actualmente se utiliza en videojuegos, películas, publicidad e incluso en la moda.
Métodos iniciales: PixelRNN y PixelCNN
Antes de los modelos avanzados de IA actuales, los investigadores desarrollaron métodos iniciales de generación de imágenes como PixelRNN y PixelCNN. Estos modelos generaban imágenes prediciendo un píxel a la vez.
- PixelRNN: utiliza un sistema llamado red neuronal recurrente (RNN) para predecir los colores de los píxeles uno tras otro. Aunque funcionaba bien, era muy lento;
- PixelCNN: mejoró PixelRNN utilizando un tipo diferente de red, llamada capas convolucionales, lo que permitió una creación de imágenes más rápida.
Aunque estos modelos fueron un buen comienzo, no lograban generar imágenes de alta calidad. Esto llevó al desarrollo de técnicas más avanzadas.
Modelos autorregresivos
Los modelos autorregresivos también crean imágenes un píxel a la vez, utilizando los píxeles anteriores para predecir el siguiente. Estos modelos fueron útiles pero lentos, lo que hizo que con el tiempo fueran menos populares. Sin embargo, sirvieron de inspiración para modelos más nuevos y rápidos.
Cómo la IA comprende el texto para la creación de imágenes
Algunos modelos de IA pueden convertir palabras escritas en imágenes. Estos modelos utilizan Modelos de Lenguaje de Gran Tamaño (LLMs) para comprender descripciones y generar imágenes que coincidan. Por ejemplo, si escribes “a cat sitting on a beach at sunset”, la IA creará una imagen basada en esa descripción.
Modelos de IA como DALL-E de OpenAI e Imagen de Google emplean comprensión avanzada del lenguaje para mejorar la correspondencia entre las descripciones de texto y las imágenes generadas. Esto es posible gracias al Procesamiento de Lenguaje Natural (NLP), que ayuda a la IA a convertir palabras en números que guían la creación de imágenes.
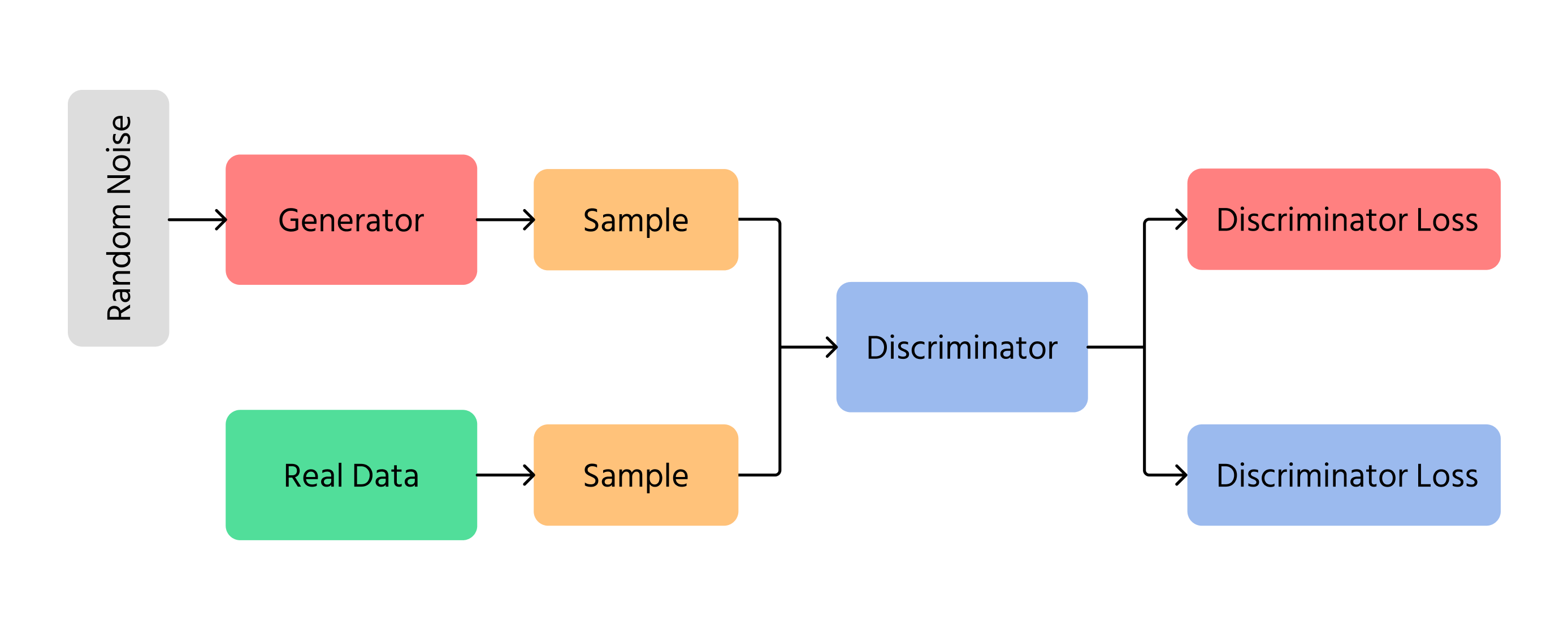
Redes Generativas Antagónicas (GANs)
Uno de los avances más importantes en la generación de imágenes por IA fueron las Redes Generativas Antagónicas (GANs). Las GANs funcionan utilizando dos redes neuronales diferentes:
- Generador: crea nuevas imágenes desde cero;
- Discriminador: verifica si las imágenes parecen reales o falsas.
El generador intenta crear imágenes tan realistas que el discriminador no pueda distinguir que son falsas. Con el tiempo, las imágenes mejoran y se parecen más a fotografías reales. Las GANs se utilizan en tecnología deepfake, creación artística y mejora de calidad de imágenes.
Autoencoders Variacionales (VAE)
Los VAE son otra forma en que la inteligencia artificial puede generar imágenes. En lugar de utilizar competencia como los GAN, los VAE codifican y decodifican imágenes utilizando probabilidad. Funcionan aprendiendo los patrones subyacentes en una imagen y luego reconstruyéndola con ligeras variaciones. El elemento probabilístico en los VAE garantiza que cada imagen generada sea ligeramente diferente, lo que añade variedad y creatividad.
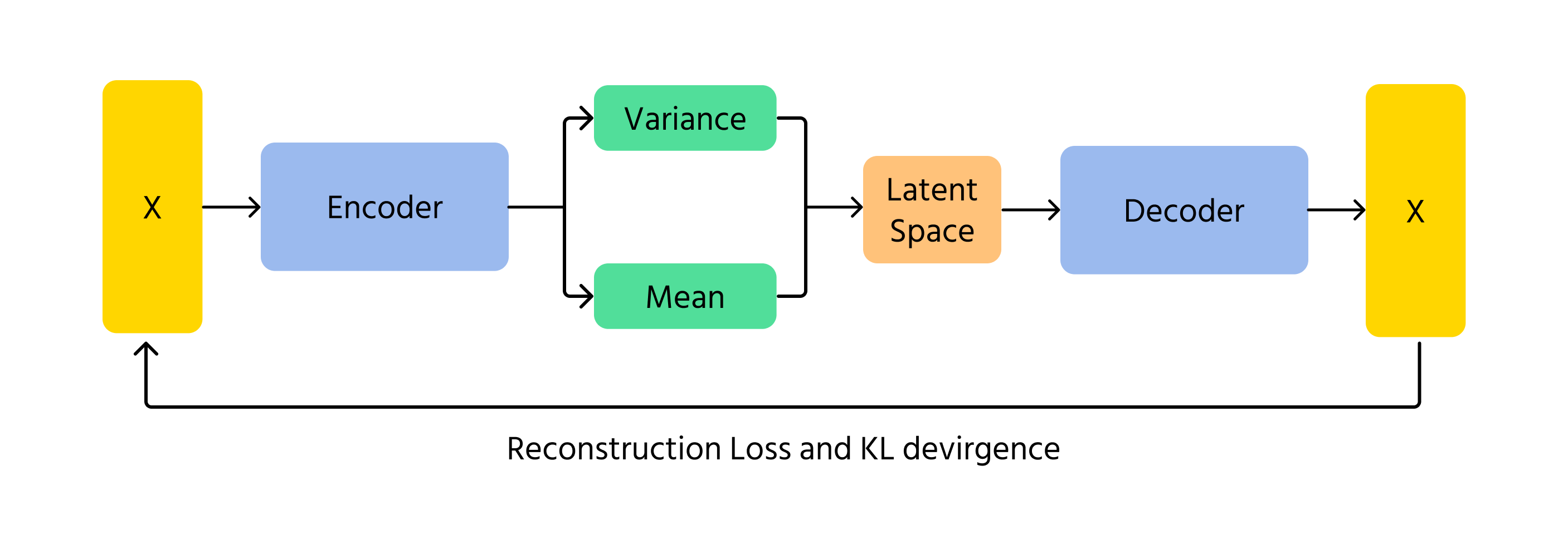
Un concepto clave en los VAE es la divergencia de Kullback-Leibler (KL), que mide la diferencia entre la distribución aprendida y una distribución normal estándar. Al minimizar la divergencia KL, los VAE aseguran que las imágenes generadas se mantengan realistas, permitiendo al mismo tiempo variaciones creativas.
Funcionamiento de los VAE
- Codificación: los datos de entrada x se introducen en el codificador, que produce los parámetros de la distribución del espacio latente q(z∣x) (media μ y varianza σ²);
- Muestreo en el espacio latente: las variables latentes z se muestrean de la distribución q(z∣x) utilizando técnicas como el truco de reparametrización;
- Decodificación y reconstrucción: el z muestreado se pasa por el decodificador para producir los datos reconstruidos x̂, que deben ser similares a la entrada original x.
Los VAE son útiles para tareas como reconstrucción de rostros, generación de nuevas versiones de imágenes existentes e incluso para realizar transiciones suaves entre diferentes imágenes.
Modelos de difusión
Los modelos de difusión representan el avance más reciente en imágenes generadas por IA. Estos modelos comienzan con ruido aleatorio y mejoran gradualmente la imagen paso a paso, como si se eliminara la estática de una foto borrosa. A diferencia de los GAN, que a veces crean variaciones limitadas, los modelos de difusión pueden producir una gama más amplia de imágenes de alta calidad.
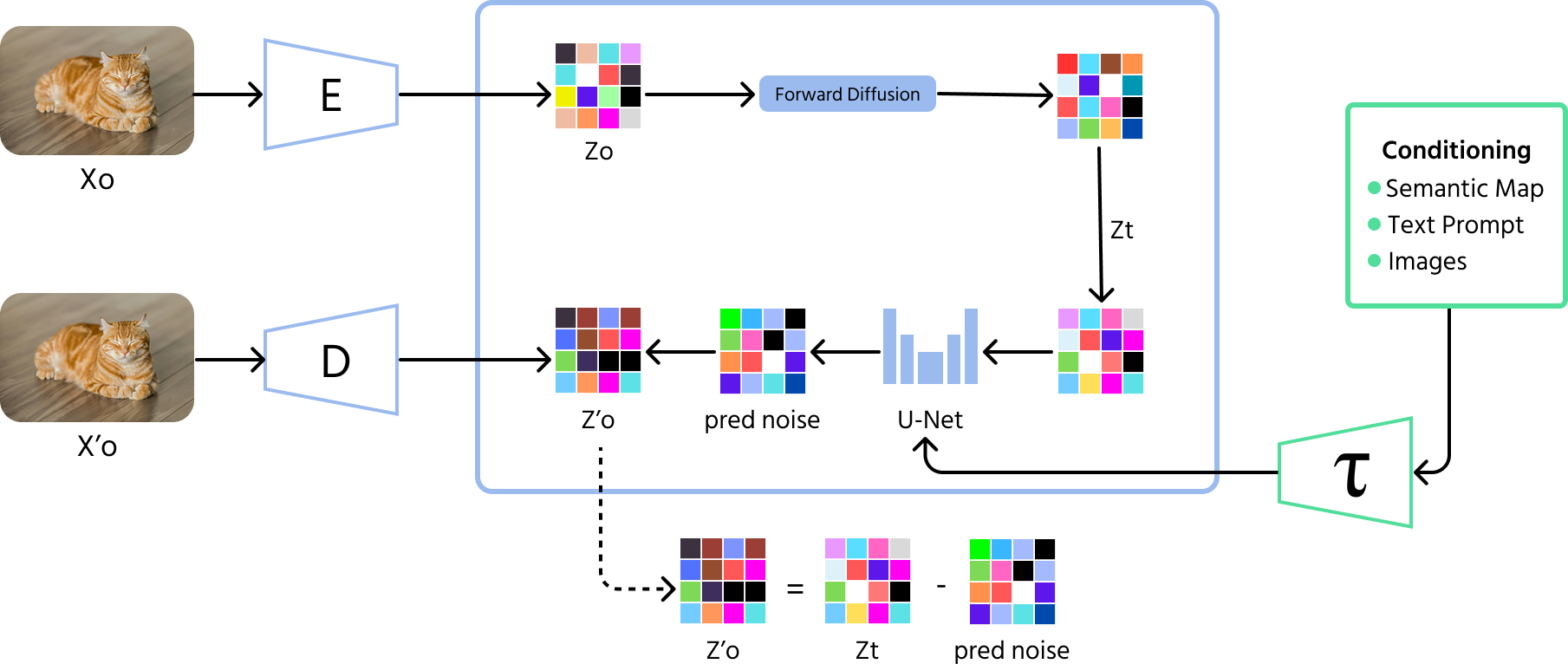
Funcionamiento de los modelos de difusión
- Proceso directo (adición de ruido): el modelo comienza añadiendo ruido aleatorio a una imagen durante muchos pasos hasta que se vuelve completamente irreconocible;
- Proceso inverso (eliminación de ruido): luego el modelo aprende a revertir este proceso, eliminando gradualmente el ruido paso a paso para recuperar una imagen significativa;
- Entrenamiento: los modelos de difusión se entrenan para predecir y eliminar el ruido en cada paso, lo que les ayuda a generar imágenes claras y de alta calidad a partir de ruido aleatorio.
Un ejemplo popular es MidJourney, DALL-E y Stable Diffusion, conocido por crear imágenes realistas y artísticas. Los modelos de difusión se utilizan ampliamente para arte generado por IA, síntesis de imágenes de alta resolución y aplicaciones de diseño creativo.
Ejemplos de imágenes generadas por modelos de difusión

Imagen realista de un jugador de baloncesto con barba, vistiendo un uniforme amarillo-violeta, realizando una volcada y derrotando demonios en un partido de baloncesto; toda la acción ocurre en el infierno.

Una foto artística surrealista y hermosa de un Volkswagen Golf GTI blanco de 1990 en un campo interminable de flores blancas en armonía con la naturaleza, en medio de colinas infinitas llenas de flores, botánico, luz natural, artístico, niebla brumosa, fotorrealista, surrealista, ultra detallado, película Kodak, luz natural, lente gran angular, f 1.20

Pintura de un perro caniche beige acostado en un sofá verde con un cojín verde y blanco a rayas, al estilo de Fairfield Porter, expresionismo abstracto, con pinceladas audaces sobre fondo beige

Primer plano extremo de la piel de una mujer mediterránea o latina, destacando un tipo de piel mixta con oleosidad visible en la frente y la nariz, mientras que las mejillas parecen más secas y ligeramente escamosas. Los poros son más notorios en la zona T, y hay un brillo natural que refleja la producción de aceite. La piel presenta una mezcla de matices cálidos y dorados, con una textura desigual debido a los diferentes niveles de hidratación. La iluminación suave y natural enfatiza el contraste realista entre las áreas secas y oleosas. El fondo está desenfocado, manteniendo la atención en su cutis.
Desafíos y preocupaciones éticas
Aunque las imágenes generadas por IA son impresionantes, presentan desafíos:
- Falta de control: la IA no siempre genera exactamente lo que el usuario desea;
- Potencia de cómputo: crear imágenes de alta calidad con IA requiere computadoras potentes y costosas;
- Sesgo en los modelos de IA: como la IA aprende de imágenes existentes, a veces puede repetir sesgos presentes en los datos.
También existen preocupaciones éticas:
- ¿Quién es el dueño del arte generado por IA?: si una IA crea una obra de arte, ¿la persona que usó la IA es la propietaria o pertenece a la empresa de IA?
- Imágenes falsas y deepfakes: las GAN pueden usarse para crear imágenes falsas que parecen reales, lo que puede llevar a desinformación y problemas de privacidad.
Usos actuales de la generación de imágenes por IA
Las imágenes generadas por IA ya están teniendo un gran impacto en diferentes industrias:
- Entretenimiento: los videojuegos, películas y animaciones utilizan IA para crear fondos, personajes y efectos;
- Moda: los diseñadores emplean IA para crear nuevos estilos de ropa, y las tiendas en línea ofrecen pruebas virtuales a los clientes;
- Diseño gráfico: la IA ayuda a artistas y diseñadores a crear rápidamente logotipos, carteles y materiales de marketing.
El futuro de la generación de imágenes con IA
A medida que la generación de imágenes con IA sigue mejorando, continuará transformando la manera en que las personas crean y utilizan imágenes. Ya sea en el arte, los negocios o el entretenimiento, la IA está abriendo nuevas posibilidades y facilitando el trabajo creativo, haciéndolo más sencillo y emocionante.
1. ¿Cuál es el propósito principal de la generación de imágenes con IA?
2. ¿Cómo funcionan las Redes Generativas Antagónicas (GANs)?
3. ¿Qué modelo de IA comienza con ruido aleatorio y mejora la imagen paso a paso?
¡Gracias por tus comentarios!
Pregunte a AI
Pregunte a AI

Pregunte lo que quiera o pruebe una de las preguntas sugeridas para comenzar nuestra charla
Visión General de la Generación de Imágenes
Las imágenes generadas por IA están transformando la manera en que las personas crean arte, diseño y contenido digital. Con la ayuda de la inteligencia artificial, las computadoras ahora pueden crear imágenes realistas, potenciar el trabajo creativo e incluso apoyar a las empresas. En este capítulo, exploraremos cómo la IA genera imágenes, los diferentes tipos de modelos de generación de imágenes y sus aplicaciones en la vida real.
Cómo la IA genera imágenes
La generación de imágenes por IA funciona aprendiendo a partir de una gran colección de imágenes. La IA estudia los patrones en las imágenes y luego crea nuevas que se parecen a las originales. Esta tecnología ha mejorado mucho a lo largo de los años, produciendo imágenes cada vez más realistas y creativas. Actualmente se utiliza en videojuegos, películas, publicidad e incluso en la moda.
Métodos iniciales: PixelRNN y PixelCNN
Antes de los modelos avanzados de IA actuales, los investigadores desarrollaron métodos iniciales de generación de imágenes como PixelRNN y PixelCNN. Estos modelos generaban imágenes prediciendo un píxel a la vez.
- PixelRNN: utiliza un sistema llamado red neuronal recurrente (RNN) para predecir los colores de los píxeles uno tras otro. Aunque funcionaba bien, era muy lento;
- PixelCNN: mejoró PixelRNN utilizando un tipo diferente de red, llamada capas convolucionales, lo que permitió una creación de imágenes más rápida.
Aunque estos modelos fueron un buen comienzo, no lograban generar imágenes de alta calidad. Esto llevó al desarrollo de técnicas más avanzadas.
Modelos autorregresivos
Los modelos autorregresivos también crean imágenes un píxel a la vez, utilizando los píxeles anteriores para predecir el siguiente. Estos modelos fueron útiles pero lentos, lo que hizo que con el tiempo fueran menos populares. Sin embargo, sirvieron de inspiración para modelos más nuevos y rápidos.
Cómo la IA comprende el texto para la creación de imágenes
Algunos modelos de IA pueden convertir palabras escritas en imágenes. Estos modelos utilizan Modelos de Lenguaje de Gran Tamaño (LLMs) para comprender descripciones y generar imágenes que coincidan. Por ejemplo, si escribes “a cat sitting on a beach at sunset”, la IA creará una imagen basada en esa descripción.
Modelos de IA como DALL-E de OpenAI e Imagen de Google emplean comprensión avanzada del lenguaje para mejorar la correspondencia entre las descripciones de texto y las imágenes generadas. Esto es posible gracias al Procesamiento de Lenguaje Natural (NLP), que ayuda a la IA a convertir palabras en números que guían la creación de imágenes.
Redes Generativas Antagónicas (GANs)
Uno de los avances más importantes en la generación de imágenes por IA fueron las Redes Generativas Antagónicas (GANs). Las GANs funcionan utilizando dos redes neuronales diferentes:
- Generador: crea nuevas imágenes desde cero;
- Discriminador: verifica si las imágenes parecen reales o falsas.
El generador intenta crear imágenes tan realistas que el discriminador no pueda distinguir que son falsas. Con el tiempo, las imágenes mejoran y se parecen más a fotografías reales. Las GANs se utilizan en tecnología deepfake, creación artística y mejora de calidad de imágenes.
Autoencoders Variacionales (VAE)
Los VAE son otra forma en que la inteligencia artificial puede generar imágenes. En lugar de utilizar competencia como los GAN, los VAE codifican y decodifican imágenes utilizando probabilidad. Funcionan aprendiendo los patrones subyacentes en una imagen y luego reconstruyéndola con ligeras variaciones. El elemento probabilístico en los VAE garantiza que cada imagen generada sea ligeramente diferente, lo que añade variedad y creatividad.
Un concepto clave en los VAE es la divergencia de Kullback-Leibler (KL), que mide la diferencia entre la distribución aprendida y una distribución normal estándar. Al minimizar la divergencia KL, los VAE aseguran que las imágenes generadas se mantengan realistas, permitiendo al mismo tiempo variaciones creativas.
Funcionamiento de los VAE
- Codificación: los datos de entrada x se introducen en el codificador, que produce los parámetros de la distribución del espacio latente q(z∣x) (media μ y varianza σ²);
- Muestreo en el espacio latente: las variables latentes z se muestrean de la distribución q(z∣x) utilizando técnicas como el truco de reparametrización;
- Decodificación y reconstrucción: el z muestreado se pasa por el decodificador para producir los datos reconstruidos x̂, que deben ser similares a la entrada original x.
Los VAE son útiles para tareas como reconstrucción de rostros, generación de nuevas versiones de imágenes existentes e incluso para realizar transiciones suaves entre diferentes imágenes.
Modelos de difusión
Los modelos de difusión representan el avance más reciente en imágenes generadas por IA. Estos modelos comienzan con ruido aleatorio y mejoran gradualmente la imagen paso a paso, como si se eliminara la estática de una foto borrosa. A diferencia de los GAN, que a veces crean variaciones limitadas, los modelos de difusión pueden producir una gama más amplia de imágenes de alta calidad.
Funcionamiento de los modelos de difusión
- Proceso directo (adición de ruido): el modelo comienza añadiendo ruido aleatorio a una imagen durante muchos pasos hasta que se vuelve completamente irreconocible;
- Proceso inverso (eliminación de ruido): luego el modelo aprende a revertir este proceso, eliminando gradualmente el ruido paso a paso para recuperar una imagen significativa;
- Entrenamiento: los modelos de difusión se entrenan para predecir y eliminar el ruido en cada paso, lo que les ayuda a generar imágenes claras y de alta calidad a partir de ruido aleatorio.
Un ejemplo popular es MidJourney, DALL-E y Stable Diffusion, conocido por crear imágenes realistas y artísticas. Los modelos de difusión se utilizan ampliamente para arte generado por IA, síntesis de imágenes de alta resolución y aplicaciones de diseño creativo.
Ejemplos de imágenes generadas por modelos de difusión
Imagen realista de un jugador de baloncesto con barba, vistiendo un uniforme amarillo-violeta, realizando una volcada y derrotando demonios en un partido de baloncesto; toda la acción ocurre en el infierno.
Una foto artística surrealista y hermosa de un Volkswagen Golf GTI blanco de 1990 en un campo interminable de flores blancas en armonía con la naturaleza, en medio de colinas infinitas llenas de flores, botánico, luz natural, artístico, niebla brumosa, fotorrealista, surrealista, ultra detallado, película Kodak, luz natural, lente gran angular, f 1.20
Pintura de un perro caniche beige acostado en un sofá verde con un cojín verde y blanco a rayas, al estilo de Fairfield Porter, expresionismo abstracto, con pinceladas audaces sobre fondo beige
Primer plano extremo de la piel de una mujer mediterránea o latina, destacando un tipo de piel mixta con oleosidad visible en la frente y la nariz, mientras que las mejillas parecen más secas y ligeramente escamosas. Los poros son más notorios en la zona T, y hay un brillo natural que refleja la producción de aceite. La piel presenta una mezcla de matices cálidos y dorados, con una textura desigual debido a los diferentes niveles de hidratación. La iluminación suave y natural enfatiza el contraste realista entre las áreas secas y oleosas. El fondo está desenfocado, manteniendo la atención en su cutis.
Desafíos y preocupaciones éticas
Aunque las imágenes generadas por IA son impresionantes, presentan desafíos:
- Falta de control: la IA no siempre genera exactamente lo que el usuario desea;
- Potencia de cómputo: crear imágenes de alta calidad con IA requiere computadoras potentes y costosas;
- Sesgo en los modelos de IA: como la IA aprende de imágenes existentes, a veces puede repetir sesgos presentes en los datos.
También existen preocupaciones éticas:
- ¿Quién es el dueño del arte generado por IA?: si una IA crea una obra de arte, ¿la persona que usó la IA es la propietaria o pertenece a la empresa de IA?
- Imágenes falsas y deepfakes: las GAN pueden usarse para crear imágenes falsas que parecen reales, lo que puede llevar a desinformación y problemas de privacidad.
Usos actuales de la generación de imágenes por IA
Las imágenes generadas por IA ya están teniendo un gran impacto en diferentes industrias:
- Entretenimiento: los videojuegos, películas y animaciones utilizan IA para crear fondos, personajes y efectos;
- Moda: los diseñadores emplean IA para crear nuevos estilos de ropa, y las tiendas en línea ofrecen pruebas virtuales a los clientes;
- Diseño gráfico: la IA ayuda a artistas y diseñadores a crear rápidamente logotipos, carteles y materiales de marketing.
El futuro de la generación de imágenes con IA
A medida que la generación de imágenes con IA sigue mejorando, continuará transformando la manera en que las personas crean y utilizan imágenes. Ya sea en el arte, los negocios o el entretenimiento, la IA está abriendo nuevas posibilidades y facilitando el trabajo creativo, haciéndolo más sencillo y emocionante.
¡Gracias por tus comentarios!
