Aprendizaje por Transferencia en Visión por Computadora
Desliza para mostrar el menú
El aprendizaje por transferencia permite reutilizar modelos entrenados en grandes conjuntos de datos para nuevas tareas con datos limitados. En lugar de construir una red neuronal desde cero, se aprovechan modelos preentrenados para mejorar la eficiencia y el rendimiento. A lo largo de este curso, ya se han presentado enfoques similares en secciones anteriores, lo que ha sentado las bases para aplicar el aprendizaje por transferencia de manera efectiva.
¿Qué es el aprendizaje por transferencia?
El aprendizaje por transferencia es una técnica en la que un modelo entrenado en una tarea se adapta a otra tarea relacionada. En visión por computadora, los modelos preentrenados en grandes conjuntos de datos como ImageNet pueden ajustarse para aplicaciones específicas como imágenes médicas o conducción autónoma.
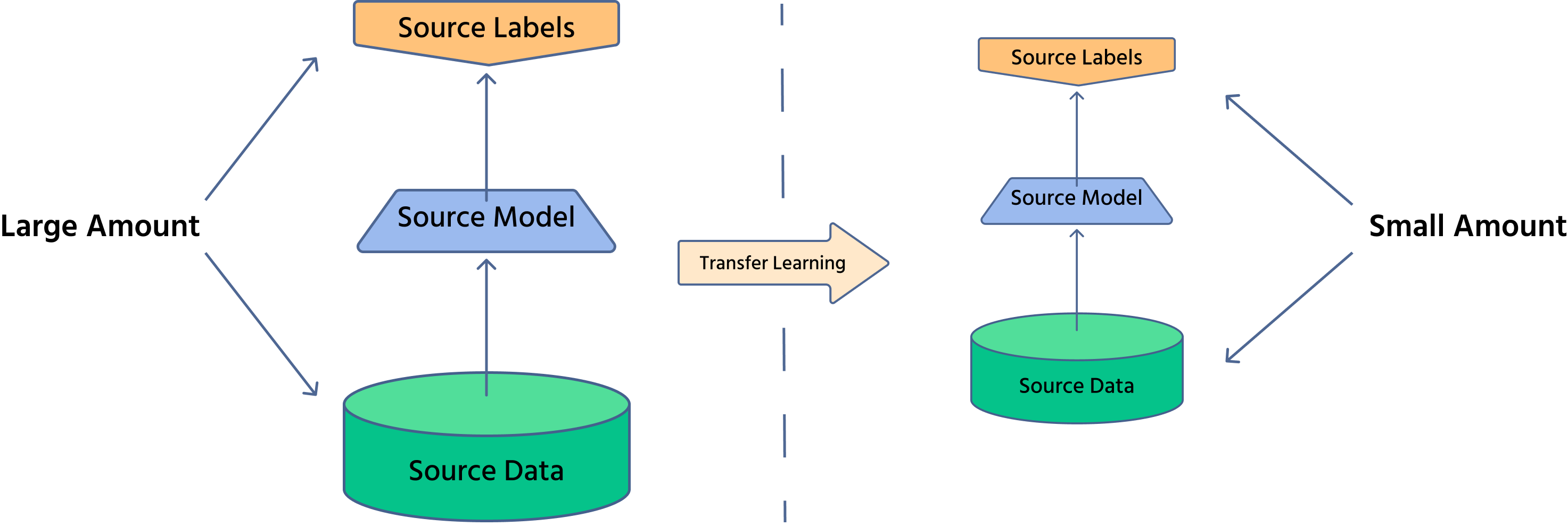
¿Por qué es importante el aprendizaje por transferencia?
- Reduce el tiempo de entrenamiento: dado que el modelo ya ha aprendido características generales, solo se requieren pequeños ajustes;
- Requiere menos datos: útil en casos donde obtener datos etiquetados es costoso;
- Mejora el rendimiento: los modelos preentrenados ofrecen una extracción de características robusta, aumentando la precisión.
Flujo de trabajo del aprendizaje por transferencia
El flujo de trabajo típico del aprendizaje por transferencia implica varios pasos clave:
-
Selección de un modelo preentrenado:
- Elegir un modelo entrenado en un conjunto de datos grande (por ejemplo, ResNet, VGG, YOLO);
- Estos modelos han aprendido representaciones útiles que pueden adaptarse a nuevas tareas.
-
Modificación del modelo preentrenado:
- Extracción de características: congelar las primeras capas y solo reentrenar las capas finales para la nueva tarea;
- Ajuste fino: descongelar algunas o todas las capas y reentrenarlas con el nuevo conjunto de datos.
-
Entrenamiento con el nuevo conjunto de datos:
- Entrenar el modelo modificado utilizando un conjunto de datos más pequeño específico para la tarea objetivo;
- Optimizar utilizando técnicas como retropropagación y funciones de pérdida.
-
Evaluación e iteración:
- Evaluar el rendimiento utilizando métricas como precisión, exactitud, recuperación y mAP;
- Realizar ajustes adicionales si es necesario para mejorar los resultados.
Modelos preentrenados populares
Algunos de los modelos preentrenados más utilizados en visión por computadora incluyen:
- ResNet: redes residuales profundas que permiten entrenar arquitecturas muy profundas;
- VGG: una arquitectura simple con capas convolucionales uniformes;
- EfficientNet: optimizado para alta precisión con menos parámetros;
- YOLO: detección de objetos en tiempo real de última generación (SOTA).
Ajuste fino vs. Extracción de características
La extracción de características implica utilizar las capas de un modelo preentrenado como extractores de características fijos. En este enfoque, la capa de clasificación final del modelo original suele eliminarse y reemplazarse por una nueva específica para la tarea objetivo. Las capas preentrenadas permanecen congeladas, lo que significa que sus pesos no se actualizan durante el entrenamiento, lo que acelera el proceso y requiere menos datos.
from tensorflow.keras.applications import VGG16
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Flatten
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
for layer in base_model.layers:
layer.trainable = False # Freeze base model layers
x = Flatten()(base_model.output)
x = Dense(256, activation='relu')(x)
x = Dense(10, activation='softmax')(x) # Task-specific output
model = Model(inputs=base_model.input, outputs=x)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
El ajuste fino, por otro lado, va un paso más allá al descongelar algunas o todas las capas preentrenadas y reentrenarlas con el nuevo conjunto de datos. Esto permite que el modelo adapte las características aprendidas de manera más precisa a las particularidades de la nueva tarea, lo que a menudo conduce a un mejor rendimiento, especialmente cuando el nuevo conjunto de datos es suficientemente grande o difiere significativamente de los datos de entrenamiento originales.
for layer in base_model.layers[-10:]: # Unfreeze last 10 layers
layer.trainable = True
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Aplicaciones del aprendizaje por transferencia
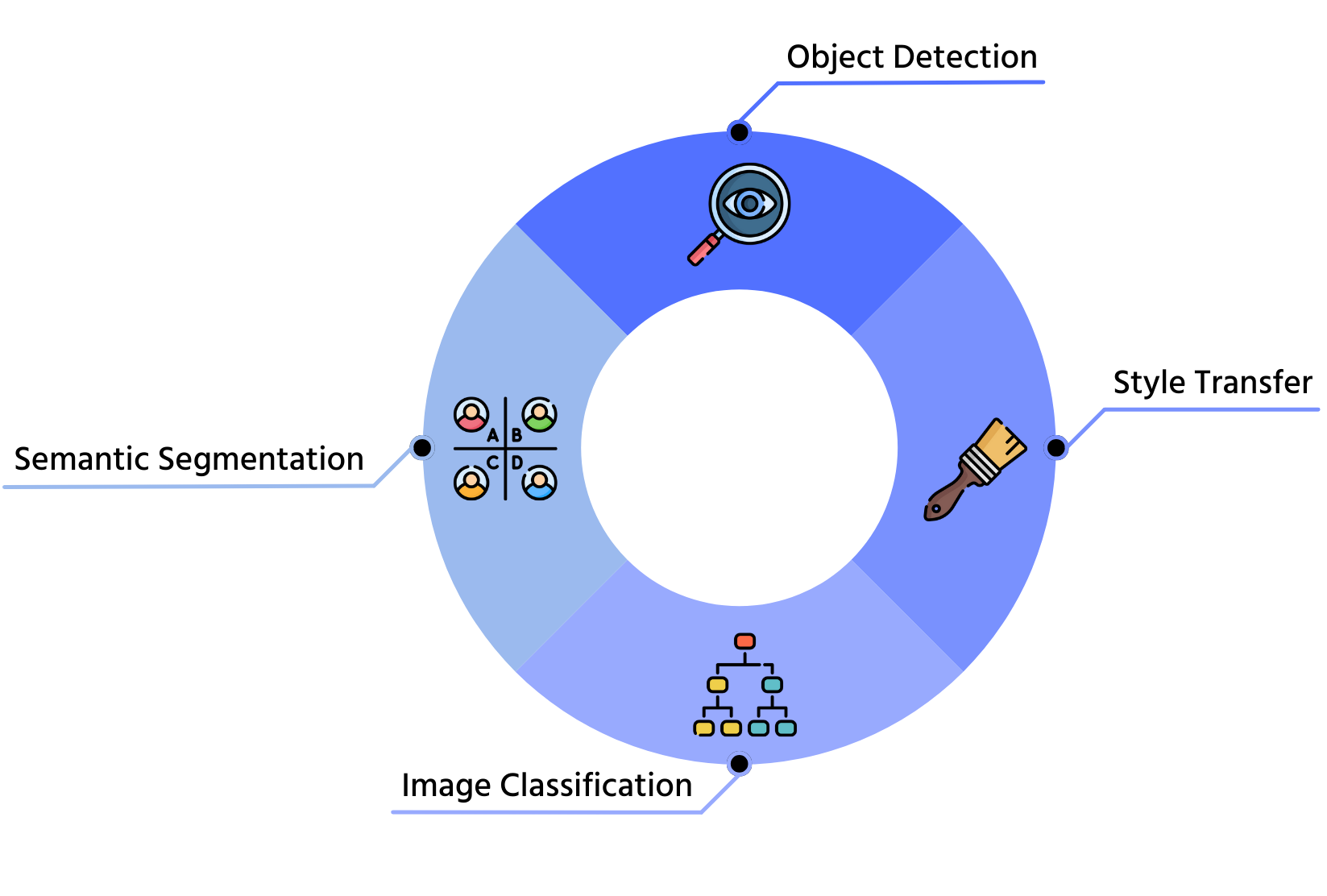
1. Clasificación de Imágenes
La clasificación de imágenes consiste en asignar etiquetas a imágenes según su contenido visual. Modelos preentrenados como ResNet y EfficientNet pueden adaptarse a tareas específicas como imágenes médicas o clasificación de fauna.
Ejemplo:
- Seleccionar un modelo preentrenado (por ejemplo, ResNet);
- Modificar la capa de clasificación para que coincida con las clases objetivo;
- Ajustar con una tasa de aprendizaje baja.
2. Detección de Objetos
La detección de objetos implica tanto identificar objetos como localizarlos dentro de una imagen. El aprendizaje por transferencia permite que modelos como Faster R-CNN, SSD y YOLO detecten objetos específicos en nuevos conjuntos de datos de manera eficiente.
Ejemplo:
- Utilizar un modelo de detección de objetos preentrenado (por ejemplo, YOLOv8);
- Ajustar en un conjunto de datos personalizado con nuevas clases de objetos;
- Evaluar el rendimiento y optimizar según sea necesario.
3. Segmentación Semántica
La segmentación semántica clasifica cada píxel de una imagen en categorías predefinidas. Modelos como U-Net y DeepLab se utilizan ampliamente en aplicaciones como conducción autónoma e imágenes médicas.
Ejemplo:
- Utilizar un modelo de segmentación preentrenado (por ejemplo, U-Net);
- Entrenar en un conjunto de datos específico del dominio;
- Ajustar hiperparámetros para mejorar la precisión.
4. Transferencia de Estilo
La transferencia de estilo aplica el estilo visual de una imagen a otra mientras se conserva su contenido original. Esta técnica se utiliza comúnmente en arte digital y mejora de imágenes, aprovechando modelos preentrenados como VGG.
Ejemplo:
- Seleccionar un modelo de transferencia de estilo (por ejemplo, VGG);
- Ingresar imágenes de contenido y de estilo;
- Optimizar para obtener resultados visualmente atractivos.
1. ¿Cuál es la principal ventaja de utilizar aprendizaje por transferencia en visión por computadora?
2. ¿Qué enfoque se utiliza en el aprendizaje por transferencia cuando solo se modifica la última capa de un modelo preentrenado mientras se mantienen fijas las capas anteriores?
3. ¿Cuál de los siguientes modelos se utiliza comúnmente para el aprendizaje por transferencia en la detección de objetos?
¡Gracias por tus comentarios!
Pregunte a AI
Pregunte a AI

Pregunte lo que quiera o pruebe una de las preguntas sugeridas para comenzar nuestra charla
Aprendizaje por Transferencia en Visión por Computadora
El aprendizaje por transferencia permite reutilizar modelos entrenados en grandes conjuntos de datos para nuevas tareas con datos limitados. En lugar de construir una red neuronal desde cero, se aprovechan modelos preentrenados para mejorar la eficiencia y el rendimiento. A lo largo de este curso, ya se han presentado enfoques similares en secciones anteriores, lo que ha sentado las bases para aplicar el aprendizaje por transferencia de manera efectiva.
¿Qué es el aprendizaje por transferencia?
El aprendizaje por transferencia es una técnica en la que un modelo entrenado en una tarea se adapta a otra tarea relacionada. En visión por computadora, los modelos preentrenados en grandes conjuntos de datos como ImageNet pueden ajustarse para aplicaciones específicas como imágenes médicas o conducción autónoma.
¿Por qué es importante el aprendizaje por transferencia?
- Reduce el tiempo de entrenamiento: dado que el modelo ya ha aprendido características generales, solo se requieren pequeños ajustes;
- Requiere menos datos: útil en casos donde obtener datos etiquetados es costoso;
- Mejora el rendimiento: los modelos preentrenados ofrecen una extracción de características robusta, aumentando la precisión.
Flujo de trabajo del aprendizaje por transferencia
El flujo de trabajo típico del aprendizaje por transferencia implica varios pasos clave:
-
Selección de un modelo preentrenado:
- Elegir un modelo entrenado en un conjunto de datos grande (por ejemplo, ResNet, VGG, YOLO);
- Estos modelos han aprendido representaciones útiles que pueden adaptarse a nuevas tareas.
-
Modificación del modelo preentrenado:
- Extracción de características: congelar las primeras capas y solo reentrenar las capas finales para la nueva tarea;
- Ajuste fino: descongelar algunas o todas las capas y reentrenarlas con el nuevo conjunto de datos.
-
Entrenamiento con el nuevo conjunto de datos:
- Entrenar el modelo modificado utilizando un conjunto de datos más pequeño específico para la tarea objetivo;
- Optimizar utilizando técnicas como retropropagación y funciones de pérdida.
-
Evaluación e iteración:
- Evaluar el rendimiento utilizando métricas como precisión, exactitud, recuperación y mAP;
- Realizar ajustes adicionales si es necesario para mejorar los resultados.
Modelos preentrenados populares
Algunos de los modelos preentrenados más utilizados en visión por computadora incluyen:
- ResNet: redes residuales profundas que permiten entrenar arquitecturas muy profundas;
- VGG: una arquitectura simple con capas convolucionales uniformes;
- EfficientNet: optimizado para alta precisión con menos parámetros;
- YOLO: detección de objetos en tiempo real de última generación (SOTA).
Ajuste fino vs. Extracción de características
La extracción de características implica utilizar las capas de un modelo preentrenado como extractores de características fijos. En este enfoque, la capa de clasificación final del modelo original suele eliminarse y reemplazarse por una nueva específica para la tarea objetivo. Las capas preentrenadas permanecen congeladas, lo que significa que sus pesos no se actualizan durante el entrenamiento, lo que acelera el proceso y requiere menos datos.
from tensorflow.keras.applications import VGG16
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Flatten
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
for layer in base_model.layers:
layer.trainable = False # Freeze base model layers
x = Flatten()(base_model.output)
x = Dense(256, activation='relu')(x)
x = Dense(10, activation='softmax')(x) # Task-specific output
model = Model(inputs=base_model.input, outputs=x)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
El ajuste fino, por otro lado, va un paso más allá al descongelar algunas o todas las capas preentrenadas y reentrenarlas con el nuevo conjunto de datos. Esto permite que el modelo adapte las características aprendidas de manera más precisa a las particularidades de la nueva tarea, lo que a menudo conduce a un mejor rendimiento, especialmente cuando el nuevo conjunto de datos es suficientemente grande o difiere significativamente de los datos de entrenamiento originales.
for layer in base_model.layers[-10:]: # Unfreeze last 10 layers
layer.trainable = True
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Aplicaciones del aprendizaje por transferencia
1. Clasificación de Imágenes
La clasificación de imágenes consiste en asignar etiquetas a imágenes según su contenido visual. Modelos preentrenados como ResNet y EfficientNet pueden adaptarse a tareas específicas como imágenes médicas o clasificación de fauna.
Ejemplo:
- Seleccionar un modelo preentrenado (por ejemplo, ResNet);
- Modificar la capa de clasificación para que coincida con las clases objetivo;
- Ajustar con una tasa de aprendizaje baja.
2. Detección de Objetos
La detección de objetos implica tanto identificar objetos como localizarlos dentro de una imagen. El aprendizaje por transferencia permite que modelos como Faster R-CNN, SSD y YOLO detecten objetos específicos en nuevos conjuntos de datos de manera eficiente.
Ejemplo:
- Utilizar un modelo de detección de objetos preentrenado (por ejemplo, YOLOv8);
- Ajustar en un conjunto de datos personalizado con nuevas clases de objetos;
- Evaluar el rendimiento y optimizar según sea necesario.
3. Segmentación Semántica
La segmentación semántica clasifica cada píxel de una imagen en categorías predefinidas. Modelos como U-Net y DeepLab se utilizan ampliamente en aplicaciones como conducción autónoma e imágenes médicas.
Ejemplo:
- Utilizar un modelo de segmentación preentrenado (por ejemplo, U-Net);
- Entrenar en un conjunto de datos específico del dominio;
- Ajustar hiperparámetros para mejorar la precisión.
4. Transferencia de Estilo
La transferencia de estilo aplica el estilo visual de una imagen a otra mientras se conserva su contenido original. Esta técnica se utiliza comúnmente en arte digital y mejora de imágenes, aprovechando modelos preentrenados como VGG.
Ejemplo:
- Seleccionar un modelo de transferencia de estilo (por ejemplo, VGG);
- Ingresar imágenes de contenido y de estilo;
- Optimizar para obtener resultados visualmente atractivos.
¡Gracias por tus comentarios!
