Cajas Ancla
Desliza para mostrar el menú
Caja ancla es una caja delimitadora predefinida con un tamaño y relación de aspecto fijos, colocada en posiciones específicas a lo largo de una imagen.
Por qué se utilizan las cajas ancla en la detección de objetos
Las cajas ancla son un concepto fundamental en los modelos modernos de detección de objetos como Faster R-CNN y YOLO. Sirven como cajas de referencia predefinidas que ayudan a detectar objetos de diferentes tamaños y relaciones de aspecto, haciendo la detección más rápida y confiable.
En lugar de detectar objetos desde cero, los modelos utilizan cajas ancla como puntos de partida, ajustándolas para que se adapten mejor a los objetos detectados. Este enfoque mejora la eficiencia y la precisión, especialmente para detectar objetos de diferentes escalas.
Diferencia entre caja ancla y caja delimitadora
- Caja ancla: plantilla predefinida que actúa como referencia durante la detección de objetos;
- Caja delimitadora: caja final predicha después de realizar ajustes a una caja ancla para que coincida con el objeto real.

A diferencia de las cajas delimitadoras, que se ajustan dinámicamente durante la predicción, las cajas ancla son fijas en posiciones específicas antes de que ocurra cualquier detección de objetos. Los modelos aprenden a refinar las cajas ancla ajustando su tamaño, posición y relación de aspecto, transformándolas finalmente en cajas delimitadoras finales que representan con precisión los objetos detectados.
Cómo una red genera cajas ancla
Las cajas ancla no se aplican directamente a una imagen, sino a los mapas de características extraídos de la imagen. Después de la extracción de características, se coloca un conjunto de cajas ancla en estos mapas de características, variando en tamaño y relación de aspecto. La elección de las formas de las cajas ancla es crucial e implica un equilibrio entre la detección de objetos pequeños y grandes.
Para definir los tamaños de las cajas ancla, los modelos suelen utilizar una combinación de selección manual y algoritmos de agrupamiento como K-Means para analizar el conjunto de datos y determinar las formas y tamaños de objetos más comunes. Estas cajas ancla predefinidas se aplican luego en diferentes ubicaciones a lo largo de los mapas de características. Por ejemplo, un modelo de detección de objetos puede utilizar cajas ancla de tamaños (16x16), (32x32), (64x64), con relaciones de aspecto como 1:1, 1:2, and 2:1.
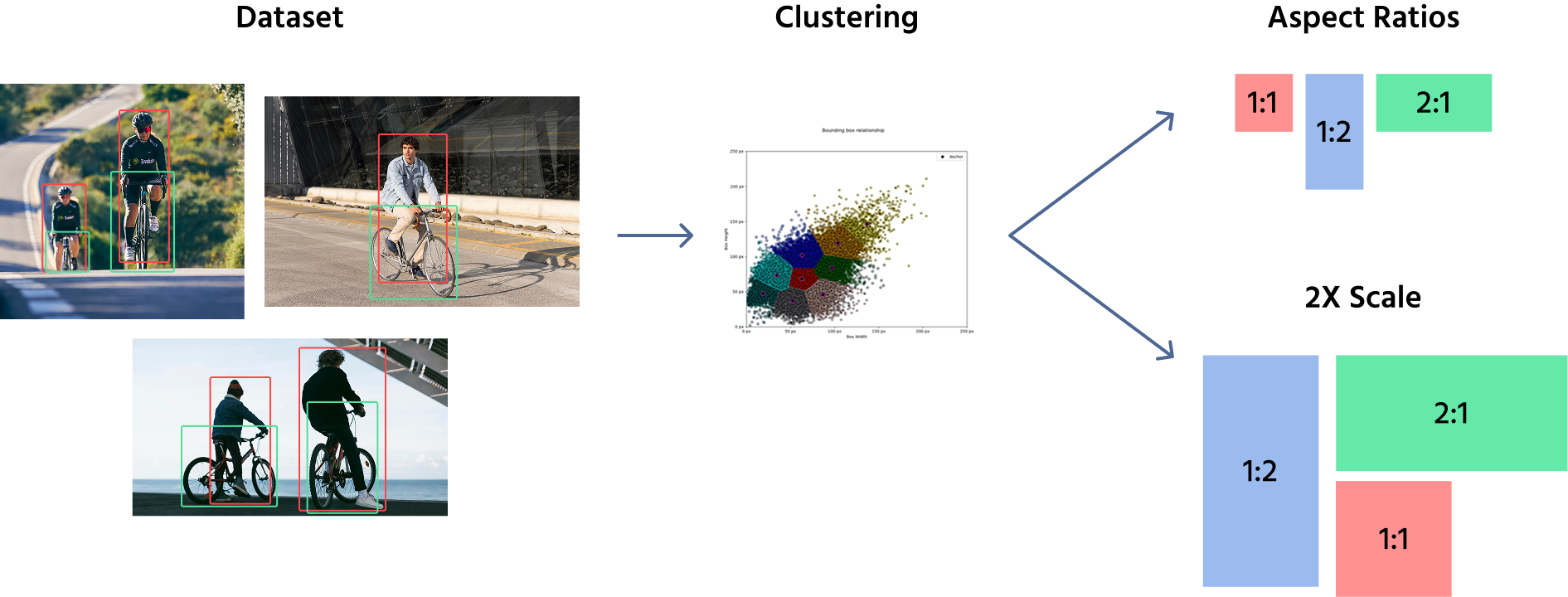
Una vez que se definen estas cajas ancla, se aplican a los mapas de características, no a la imagen original. El modelo asigna múltiples cajas ancla a cada ubicación del mapa de características, cubriendo diferentes formas y tamaños. Durante el entrenamiento, la red ajusta las cajas ancla prediciendo desplazamientos, refinando su tamaño y posición para adaptarse mejor a los objetos.
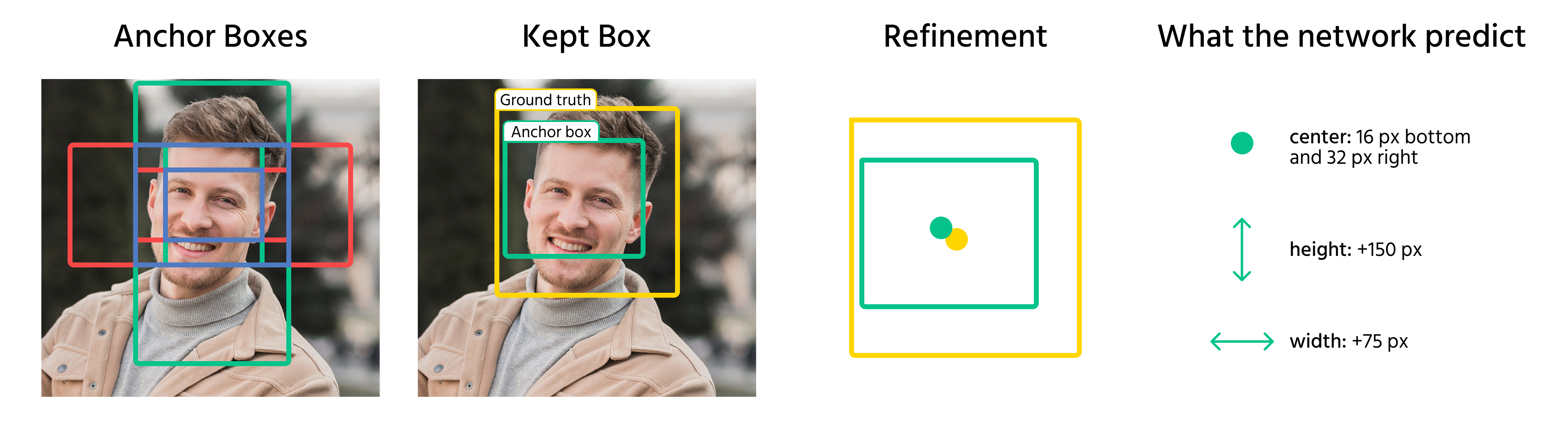
De la caja ancla a la caja delimitadora
Una vez que las cajas ancla se asignan a los objetos, el modelo predice desplazamientos para refinarlas. Estos desplazamientos incluyen:
- Ajuste de las coordenadas centrales de la caja;
- Escalado del ancho y la altura;
- Desplazamiento de la caja para alinearla mejor con el objeto.
Al aplicar estas transformaciones, el modelo convierte las cajas ancla en cajas delimitadoras finales que se ajustan estrechamente a los objetos en una imagen.
Enfoques que no utilizan anclas o reducen su cantidad
Aunque las cajas ancla se utilizan ampliamente, algunos modelos buscan reducir su dependencia o eliminarlas por completo:
- Métodos sin anclas: modelos como
CenterNetyFCOSpredicen directamente la ubicación de los objetos sin anclas predefinidas, lo que reduce la complejidad; - Enfoques con menos anclas:
EfficientDetyYOLOv4optimizan la cantidad de cajas ancla utilizadas, equilibrando la velocidad de detección y la precisión.
Estos enfoques buscan mejorar la eficiencia en la detección de objetos manteniendo un alto rendimiento, especialmente en aplicaciones en tiempo real.
En resumen, las cajas ancla son una parte fundamental de la detección de objetos, ya que ayudan a los modelos a detectar objetos de manera eficiente en diferentes tamaños y proporciones. Sin embargo, los nuevos avances exploran formas de reducir o eliminar las cajas ancla para lograr una detección aún más rápida y flexible.
1. ¿Cuál es la función principal de las cajas ancla en la detección de objetos?
2. ¿En qué se diferencian las cajas ancla de las cajas delimitadoras?
3. ¿Qué método se utiliza comúnmente para determinar los tamaños óptimos de las cajas ancla?
¡Gracias por tus comentarios!
Pregunte a AI
Pregunte a AI

Pregunte lo que quiera o pruebe una de las preguntas sugeridas para comenzar nuestra charla
Cajas Ancla
Caja ancla es una caja delimitadora predefinida con un tamaño y relación de aspecto fijos, colocada en posiciones específicas a lo largo de una imagen.
Por qué se utilizan las cajas ancla en la detección de objetos
Las cajas ancla son un concepto fundamental en los modelos modernos de detección de objetos como Faster R-CNN y YOLO. Sirven como cajas de referencia predefinidas que ayudan a detectar objetos de diferentes tamaños y relaciones de aspecto, haciendo la detección más rápida y confiable.
En lugar de detectar objetos desde cero, los modelos utilizan cajas ancla como puntos de partida, ajustándolas para que se adapten mejor a los objetos detectados. Este enfoque mejora la eficiencia y la precisión, especialmente para detectar objetos de diferentes escalas.
Diferencia entre caja ancla y caja delimitadora
- Caja ancla: plantilla predefinida que actúa como referencia durante la detección de objetos;
- Caja delimitadora: caja final predicha después de realizar ajustes a una caja ancla para que coincida con el objeto real.
A diferencia de las cajas delimitadoras, que se ajustan dinámicamente durante la predicción, las cajas ancla son fijas en posiciones específicas antes de que ocurra cualquier detección de objetos. Los modelos aprenden a refinar las cajas ancla ajustando su tamaño, posición y relación de aspecto, transformándolas finalmente en cajas delimitadoras finales que representan con precisión los objetos detectados.
Cómo una red genera cajas ancla
Las cajas ancla no se aplican directamente a una imagen, sino a los mapas de características extraídos de la imagen. Después de la extracción de características, se coloca un conjunto de cajas ancla en estos mapas de características, variando en tamaño y relación de aspecto. La elección de las formas de las cajas ancla es crucial e implica un equilibrio entre la detección de objetos pequeños y grandes.
Para definir los tamaños de las cajas ancla, los modelos suelen utilizar una combinación de selección manual y algoritmos de agrupamiento como K-Means para analizar el conjunto de datos y determinar las formas y tamaños de objetos más comunes. Estas cajas ancla predefinidas se aplican luego en diferentes ubicaciones a lo largo de los mapas de características. Por ejemplo, un modelo de detección de objetos puede utilizar cajas ancla de tamaños (16x16), (32x32), (64x64), con relaciones de aspecto como 1:1, 1:2, and 2:1.
Una vez que se definen estas cajas ancla, se aplican a los mapas de características, no a la imagen original. El modelo asigna múltiples cajas ancla a cada ubicación del mapa de características, cubriendo diferentes formas y tamaños. Durante el entrenamiento, la red ajusta las cajas ancla prediciendo desplazamientos, refinando su tamaño y posición para adaptarse mejor a los objetos.
De la caja ancla a la caja delimitadora
Una vez que las cajas ancla se asignan a los objetos, el modelo predice desplazamientos para refinarlas. Estos desplazamientos incluyen:
- Ajuste de las coordenadas centrales de la caja;
- Escalado del ancho y la altura;
- Desplazamiento de la caja para alinearla mejor con el objeto.
Al aplicar estas transformaciones, el modelo convierte las cajas ancla en cajas delimitadoras finales que se ajustan estrechamente a los objetos en una imagen.
Enfoques que no utilizan anclas o reducen su cantidad
Aunque las cajas ancla se utilizan ampliamente, algunos modelos buscan reducir su dependencia o eliminarlas por completo:
- Métodos sin anclas: modelos como
CenterNetyFCOSpredicen directamente la ubicación de los objetos sin anclas predefinidas, lo que reduce la complejidad; - Enfoques con menos anclas:
EfficientDetyYOLOv4optimizan la cantidad de cajas ancla utilizadas, equilibrando la velocidad de detección y la precisión.
Estos enfoques buscan mejorar la eficiencia en la detección de objetos manteniendo un alto rendimiento, especialmente en aplicaciones en tiempo real.
En resumen, las cajas ancla son una parte fundamental de la detección de objetos, ya que ayudan a los modelos a detectar objetos de manera eficiente en diferentes tamaños y proporciones. Sin embargo, los nuevos avances exploran formas de reducir o eliminar las cajas ancla para lograr una detección aún más rápida y flexible.
¡Gracias por tus comentarios!
