Descripción General del Modelo YOLO
Desliza para mostrar el menú
El algoritmo YOLO (You Only Look Once) es un modelo de detección de objetos rápido y eficiente. A diferencia de los enfoques tradicionales como R-CNN que utilizan múltiples pasos, YOLO procesa la imagen completa en una sola pasada, lo que lo hace ideal para aplicaciones en tiempo real.
Diferencias entre YOLO y los enfoques R-CNN
Los métodos tradicionales de detección de objetos, como R-CNN y sus variantes, se basan en una tubería de dos etapas: primero generan propuestas de regiones y luego clasifican cada región propuesta. Aunque es efectivo, este enfoque es computacionalmente costoso y ralentiza la inferencia, lo que lo hace menos adecuado para aplicaciones en tiempo real.
YOLO (You Only Look Once) adopta un enfoque radicalmente diferente. Divide la imagen de entrada en una rejilla y predice cajas delimitadoras y probabilidades de clase para cada celda en una sola pasada hacia adelante. Este diseño plantea la detección de objetos como un único problema de regresión, permitiendo que YOLO logre rendimiento en tiempo real.
A diferencia de los métodos basados en R-CNN que se enfocan solo en regiones locales, YOLO procesa la imagen completa a la vez, lo que le permite capturar información contextual global. Esto conduce a un mejor desempeño en la detección de objetos múltiples o superpuestos, manteniendo alta velocidad y precisión.
Arquitectura de YOLO y predicciones basadas en rejilla
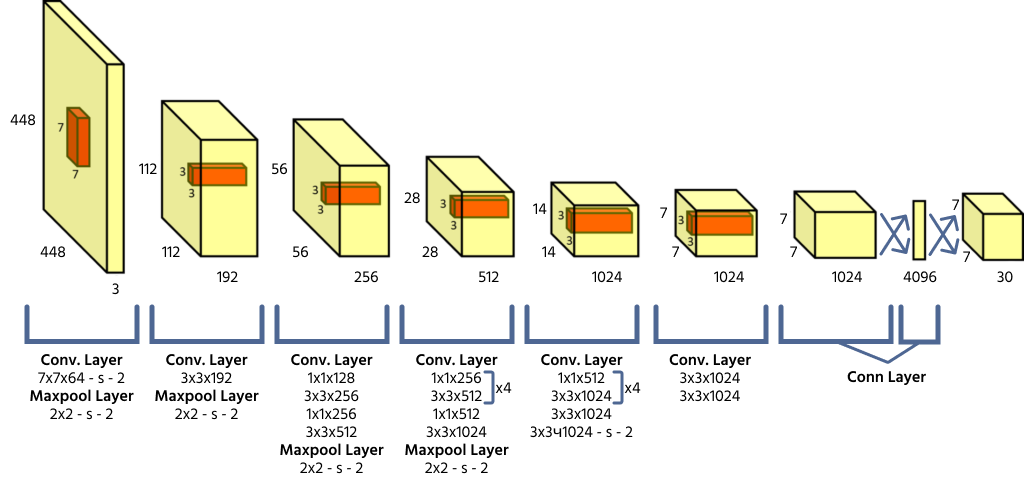
YOLO divide una imagen de entrada en una rejilla de S × S, donde cada celda de la rejilla es responsable de detectar objetos cuyo centro cae dentro de ella. Cada celda predice las coordenadas de la caja delimitadora (x, y, ancho, alto), una puntuación de confianza del objeto y probabilidades de clase. Dado que YOLO procesa la imagen completa en una sola pasada hacia adelante, es altamente eficiente en comparación con los modelos de detección de objetos anteriores.
Función de pérdida y puntuaciones de confianza de clase
YOLO optimiza la precisión de la detección utilizando una función de pérdida personalizada, que incluye:
- Pérdida de localización: mide la precisión de las cajas delimitadoras;
- Pérdida de confianza: garantiza que las predicciones indiquen correctamente la presencia de objetos;
- Pérdida de clasificación: evalúa qué tan bien la clase predicha coincide con la clase real.
Para mejorar los resultados, YOLO aplica cajas ancla y supresión no máxima (NMS) para eliminar detecciones redundantes.
Ventajas de YOLO: equilibrio entre velocidad y precisión
La principal ventaja de YOLO es la velocidad. Dado que la detección ocurre en una sola pasada, YOLO es mucho más rápido que los métodos basados en R-CNN, lo que lo hace adecuado para aplicaciones en tiempo real como la conducción autónoma y la vigilancia. Sin embargo, las primeras versiones de YOLO tenían dificultades para detectar objetos pequeños, lo cual fue mejorado en versiones posteriores.
YOLO: Una breve historia
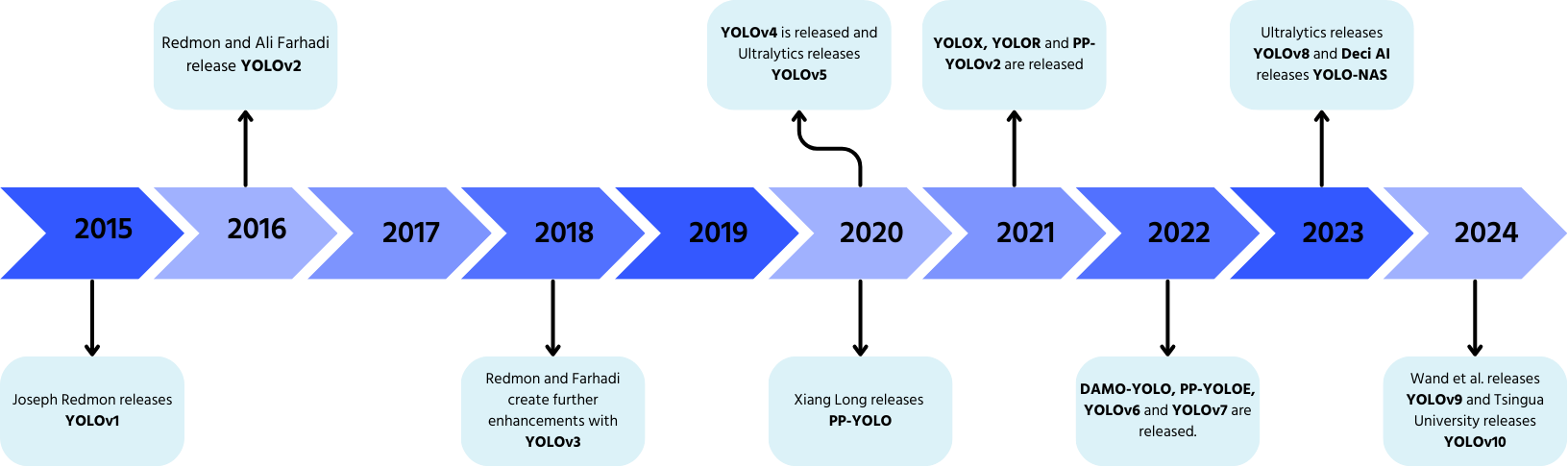
YOLO, desarrollado por Joseph Redmon y Ali Farhadi en 2015, revolucionó la detección de objetos mediante el procesamiento en una sola pasada.
- YOLOv2 (2016): incorporó normalización por lotes, cajas ancla y agrupaciones de dimensiones;
- YOLOv3 (2018): introdujo una columna vertebral más eficiente, múltiples anclas y agrupamiento piramidal espacial;
- YOLOv4 (2020): añadió aumento de datos Mosaic, una cabeza de detección sin anclas y una nueva función de pérdida;
- YOLOv5: mejoró el rendimiento con optimización de hiperparámetros, seguimiento de experimentos y funciones automáticas de exportación;
- YOLOv6 (2022): código abierto por Meituan y utilizado en robots autónomos de entrega;
- YOLOv7: amplió capacidades para incluir estimación de pose;
- YOLOv8 (2023): mejoró la velocidad, flexibilidad y eficiencia para tareas de visión artificial;
- YOLOv9: introdujo Información de Gradiente Programable (PGI) y la Red Generalizada de Agregación de Capas Eficientes (GELAN);
- YOLOv10: desarrollado por la Universidad de Tsinghua, eliminando la Supresión No Máxima (NMS) con una cabeza de detección de extremo a extremo;
- YOLOv11: el modelo más reciente que ofrece rendimiento de última generación en detección de objetos, segmentación y clasificación.
¡Gracias por tus comentarios!
Pregunte a AI
Pregunte a AI

Pregunte lo que quiera o pruebe una de las preguntas sugeridas para comenzar nuestra charla
Descripción General del Modelo YOLO
El algoritmo YOLO (You Only Look Once) es un modelo de detección de objetos rápido y eficiente. A diferencia de los enfoques tradicionales como R-CNN que utilizan múltiples pasos, YOLO procesa la imagen completa en una sola pasada, lo que lo hace ideal para aplicaciones en tiempo real.
Diferencias entre YOLO y los enfoques R-CNN
Los métodos tradicionales de detección de objetos, como R-CNN y sus variantes, se basan en una tubería de dos etapas: primero generan propuestas de regiones y luego clasifican cada región propuesta. Aunque es efectivo, este enfoque es computacionalmente costoso y ralentiza la inferencia, lo que lo hace menos adecuado para aplicaciones en tiempo real.
YOLO (You Only Look Once) adopta un enfoque radicalmente diferente. Divide la imagen de entrada en una rejilla y predice cajas delimitadoras y probabilidades de clase para cada celda en una sola pasada hacia adelante. Este diseño plantea la detección de objetos como un único problema de regresión, permitiendo que YOLO logre rendimiento en tiempo real.
A diferencia de los métodos basados en R-CNN que se enfocan solo en regiones locales, YOLO procesa la imagen completa a la vez, lo que le permite capturar información contextual global. Esto conduce a un mejor desempeño en la detección de objetos múltiples o superpuestos, manteniendo alta velocidad y precisión.
Arquitectura de YOLO y predicciones basadas en rejilla
YOLO divide una imagen de entrada en una rejilla de S × S, donde cada celda de la rejilla es responsable de detectar objetos cuyo centro cae dentro de ella. Cada celda predice las coordenadas de la caja delimitadora (x, y, ancho, alto), una puntuación de confianza del objeto y probabilidades de clase. Dado que YOLO procesa la imagen completa en una sola pasada hacia adelante, es altamente eficiente en comparación con los modelos de detección de objetos anteriores.
Función de pérdida y puntuaciones de confianza de clase
YOLO optimiza la precisión de la detección utilizando una función de pérdida personalizada, que incluye:
- Pérdida de localización: mide la precisión de las cajas delimitadoras;
- Pérdida de confianza: garantiza que las predicciones indiquen correctamente la presencia de objetos;
- Pérdida de clasificación: evalúa qué tan bien la clase predicha coincide con la clase real.
Para mejorar los resultados, YOLO aplica cajas ancla y supresión no máxima (NMS) para eliminar detecciones redundantes.
Ventajas de YOLO: equilibrio entre velocidad y precisión
La principal ventaja de YOLO es la velocidad. Dado que la detección ocurre en una sola pasada, YOLO es mucho más rápido que los métodos basados en R-CNN, lo que lo hace adecuado para aplicaciones en tiempo real como la conducción autónoma y la vigilancia. Sin embargo, las primeras versiones de YOLO tenían dificultades para detectar objetos pequeños, lo cual fue mejorado en versiones posteriores.
YOLO: Una breve historia
YOLO, desarrollado por Joseph Redmon y Ali Farhadi en 2015, revolucionó la detección de objetos mediante el procesamiento en una sola pasada.
- YOLOv2 (2016): incorporó normalización por lotes, cajas ancla y agrupaciones de dimensiones;
- YOLOv3 (2018): introdujo una columna vertebral más eficiente, múltiples anclas y agrupamiento piramidal espacial;
- YOLOv4 (2020): añadió aumento de datos Mosaic, una cabeza de detección sin anclas y una nueva función de pérdida;
- YOLOv5: mejoró el rendimiento con optimización de hiperparámetros, seguimiento de experimentos y funciones automáticas de exportación;
- YOLOv6 (2022): código abierto por Meituan y utilizado en robots autónomos de entrega;
- YOLOv7: amplió capacidades para incluir estimación de pose;
- YOLOv8 (2023): mejoró la velocidad, flexibilidad y eficiencia para tareas de visión artificial;
- YOLOv9: introdujo Información de Gradiente Programable (PGI) y la Red Generalizada de Agregación de Capas Eficientes (GELAN);
- YOLOv10: desarrollado por la Universidad de Tsinghua, eliminando la Supresión No Máxima (NMS) con una cabeza de detección de extremo a extremo;
- YOLOv11: el modelo más reciente que ofrece rendimiento de última generación en detección de objetos, segmentación y clasificación.
¡Gracias por tus comentarios!
