Generatiiviset Vastakkaisverkot (GANit)
Pyyhkäise näyttääksesi valikon
Generatiiviset vastakkaiset verkot (GANit) ovat generatiivisten mallien luokka, jonka Ian Goodfellow esitteli vuonna 2014. Ne koostuvat kahdesta neuroverkosta — Generaattorista ja Diskriminaattorista — joita koulutetaan samanaikaisesti peliteoreettisessa viitekehyksessä. Generaattori pyrkii tuottamaan dataa, joka muistuttaa oikeaa dataa, kun taas diskriminaattori pyrkii erottamaan oikean datan generoituun datasta.
GANit oppivat tuottamaan datasampleja kohinasta ratkaisemalla minimax-pelin. Koulutuksen edetessä generaattori kehittyy tuottamaan yhä realistisempaa dataa, ja diskriminaattori paranee erottamaan oikean ja keinotekoisen datan toisistaan.
GANin arkkitehtuuri
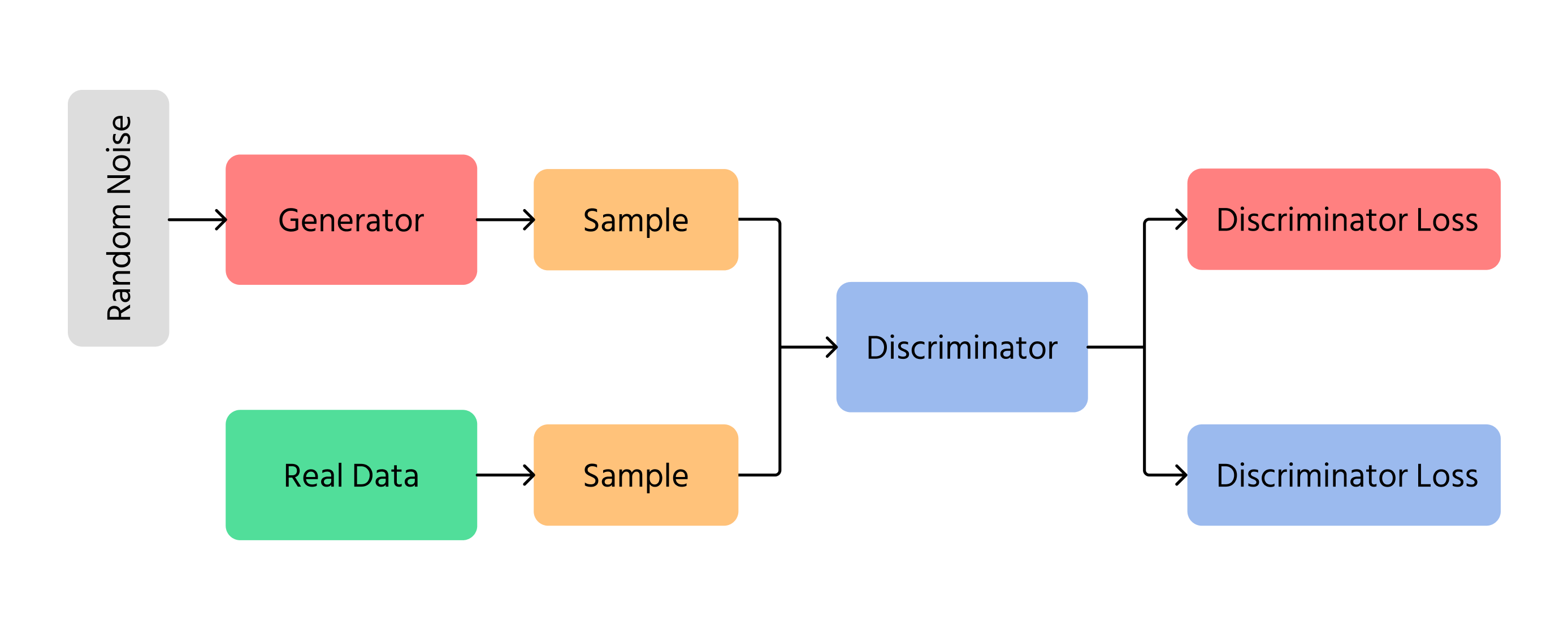
Perus-GAN-malli koostuu kahdesta ydinkomponentista:
1. Generaattori (G)
- Ottaa syötteenä satunnaisen kohinavektorin z∼pz(z);
- Muuntaa sen neuroverkon läpi tietonäytteeksi G(z), jonka tarkoituksena on muistuttaa todellisen jakauman dataa.
2. Diskriminaattori (D)
- Ottaa syötteenä joko todellisen tietonäytteen x∼px(x) tai generoitu näyte G(z);
- Tuottaa skalaariarvon välillä 0 ja 1, arvioiden syötteen todennäköisyyttä olla aito.
Näitä kahta komponenttia koulutetaan samanaikaisesti. Generaattorin tavoitteena on tuottaa realistisia näytteitä huijatakseen diskriminaattoria, kun taas diskriminaattorin tavoitteena on tunnistaa oikein aidot ja generoidut näytteet.
GANien minimax-peli
GANien ytimessä on minimax-peli, joka on peräisin peliteoriasta. Tässä asetelmassa:
- Generaattori G ja diskriminaattori D ovat kilpailevia osapuolia;
- D pyrkii maksimoimaan kykynsä erottaa aidot ja generoitu data toisistaan;
- G pyrkii minimoimaan D:n kyvyn havaita sen tuottama väärennetty data.
Tämä dynamiikka määrittelee nollasummapelin, jossa toisen voitto on toisen tappio. Optimointi määritellään seuraavasti:
GminDmaxV(D,G)=Ex∼px[logD(x)]+Ez∼pz[log(1−D(G(z)))]Generaattori pyrkii huijaamaan diskriminaattoria tuottamalla näytteitä G(z), jotka ovat mahdollisimman lähellä aitoa dataa.
Tappiofunktiot
Vaikka alkuperäinen GAN-tavoite määrittelee minimax-pelin, käytännössä käytetään vaihtoehtoisia tappiofunktioita oppimisen vakauttamiseksi.
- Ei-saturaatioinen generaattorin tappio:
Tämä auttaa generaattoria saamaan vahvoja gradientteja, vaikka diskriminaattori suoriutuisi hyvin.
- Diskriminaattorin tappio:
Nämä tappiotoiminnot kannustavat generaattoria tuottamaan näytteitä, jotka lisäävät diskriminaattorin epävarmuutta ja parantavat konvergenssia oppimisen aikana.
GAN-arkkitehtuurien keskeiset variantit
Useita GAN-tyyppejä on kehitetty ratkaisemaan tiettyjä rajoituksia tai parantamaan suorituskykyä:

Ehdollinen GAN (cGAN)
Ehdolliset GANit laajentavat perinteistä GAN-kehystä lisäämällä lisätietoa (yleensä luokkia) sekä generaattorille että diskriminaattorille. Sen sijaan, että generaattori loisi dataa pelkästä satunnaismelusta, se saa syötteenä sekä melun z että ehdon y (esim. luokkatunnisteen). Myös diskriminaattori saa y arvioidakseen, onko näyte realistinen kyseisellä ehdolla.
- Käyttökohteet: luokkakohtainen kuvagenerointi, kuva-kuva-muunnos, tekstistä kuvaan -generointi.
Syväkonvoluutio-GAN (DCGAN)
DCGANit korvaavat alkuperäisten GANien täysin kytketyt kerrokset konvoluutio- ja transponoiduilla konvoluutiokerroksilla, mikä tekee niistä tehokkaampia kuvien generoinnissa. Ne tuovat myös arkkitehtonisia ohjeita, kuten täysin kytkettyjen kerrosten poistaminen, batch-normalisoinnin käyttö ja ReLU/LeakyReLU-aktivointien hyödyntäminen.
- Käyttökohteet: valokuvamainen kuvagenerointi, visuaalisten representaatioiden oppiminen, ohjaamaton piirreoppiminen.
CycleGAN CycleGANit ratkaisevat parittoman kuva-kuva-muunnoksen ongelman. Toisin kuin muut mallit, jotka vaativat parillisia aineistoja (esim. sama valokuva kahdessa eri tyylissä), CycleGANit voivat oppia muunnoksia kahden domainin välillä ilman parillisia esimerkkejä. Ne käyttävät kahta generaattoria ja kahta diskriminaattoria, joista kukin vastaa muunnoksesta yhteen suuntaan (esim. valokuvista maalauksiin ja päinvastoin), ja ne ottavat käyttöön cycle-consistency-tappion varmistaakseen, että muunnos domainista toiseen ja takaisin palauttaa alkuperäisen kuvan. Tämä tappio on keskeinen sisällön ja rakenteen säilyttämisessä.
Cycle-consistency-tappio varmistaa:
GBA(GAB(x))≈x ja GAB(GBA(y))≈ymissä:
- GAB muuntaa kuvat domainista A domainiin B;
- GBA muuntaa domainista B domainiin A.
- x∈A,y∈B.
Käyttökohteet: valokuvien muuntaminen taiteeksi, hevosen ja seepran välinen muunnos, äänen muuntaminen puhujien välillä.
StyleGAN
StyleGAN, jonka on kehittänyt NVIDIA, tuo generaattoriin tyyliin perustuvan ohjauksen. Sen sijaan, että kohinavektori syötettäisiin suoraan generaattorille, se kulkee läpi muunnosverkon, joka tuottaa "tyylivektoreita" vaikuttamaan generaattorin jokaiseen kerrokseen. Tämä mahdollistaa yksityiskohtaisen hallinnan visuaalisista ominaisuuksista, kuten hiusten väristä, kasvonilmeistä tai valaistuksesta.
Merkittäviä innovaatioita:
- Style mixing, mahdollistaa useiden latenttikoodien yhdistämisen;
- Adaptive Instance Normalization (AdaIN), ohjaa generaattorin ominaisuuskarttoja;
- Progressiivinen kasvu, koulutus alkaa matalalla resoluutiolla ja kasvaa ajan myötä.
Käyttökohteet: erittäin korkean resoluution kuvien generointi (esim. kasvot), visuaalisten ominaisuuksien hallinta, taiteen generointi.
Vertailu: GANit vs VAE:t
GANit ovat tehokas generatiivisten mallien luokka, joka kykenee tuottamaan erittäin realistista dataa adversaarisen koulutusprosessin avulla. Mallin ytimessä on minimax-peli kahden verkon välillä, joissa käytetään adversaarisia häviöitä molempien osien iteratiiviseen parantamiseen. Vahva ymmärrys niiden arkkitehtuurista, häviöfunktioista—mukaan lukien variantit kuten cGAN, DCGAN, CycleGAN ja StyleGAN—sekä niiden eroista muihin malleihin, kuten VAEihin, antaa tarvittavan pohjan sovelluksille esimerkiksi kuvageneroinnissa, videon synteesissä, datan augmentoinnissa ja muilla alueilla.
1. Mikä seuraavista kuvaa parhaiten perus-GAN-arkkitehtuurin osat?
2. Mikä on minimax-pelin tavoite GAN-malleissa?
3. Mikä seuraavista väittämistä pitää paikkansa GAN- ja VAE-mallien eroista?
Kiitos palautteestasi!
Kysy tekoälyä
Kysy tekoälyä

Kysy mitä tahansa tai kokeile jotakin ehdotetuista kysymyksistä aloittaaksesi keskustelumme
