Yleiskatsaus Suosittuihin CNN-malleihin
Pyyhkäise näyttääksesi valikon
Konvoluutiohermoverkot (CNN:t) ovat kehittyneet merkittävästi, ja erilaiset arkkitehtuurit ovat parantaneet tarkkuutta, tehokkuutta ja skaalautuvuutta. Tässä luvussa tarkastellaan viittä keskeistä CNN-mallia, jotka ovat muokanneet syväoppimista: LeNet, AlexNet, VGGNet, ResNet ja InceptionNet.
LeNet: CNN-verkkojen perusta
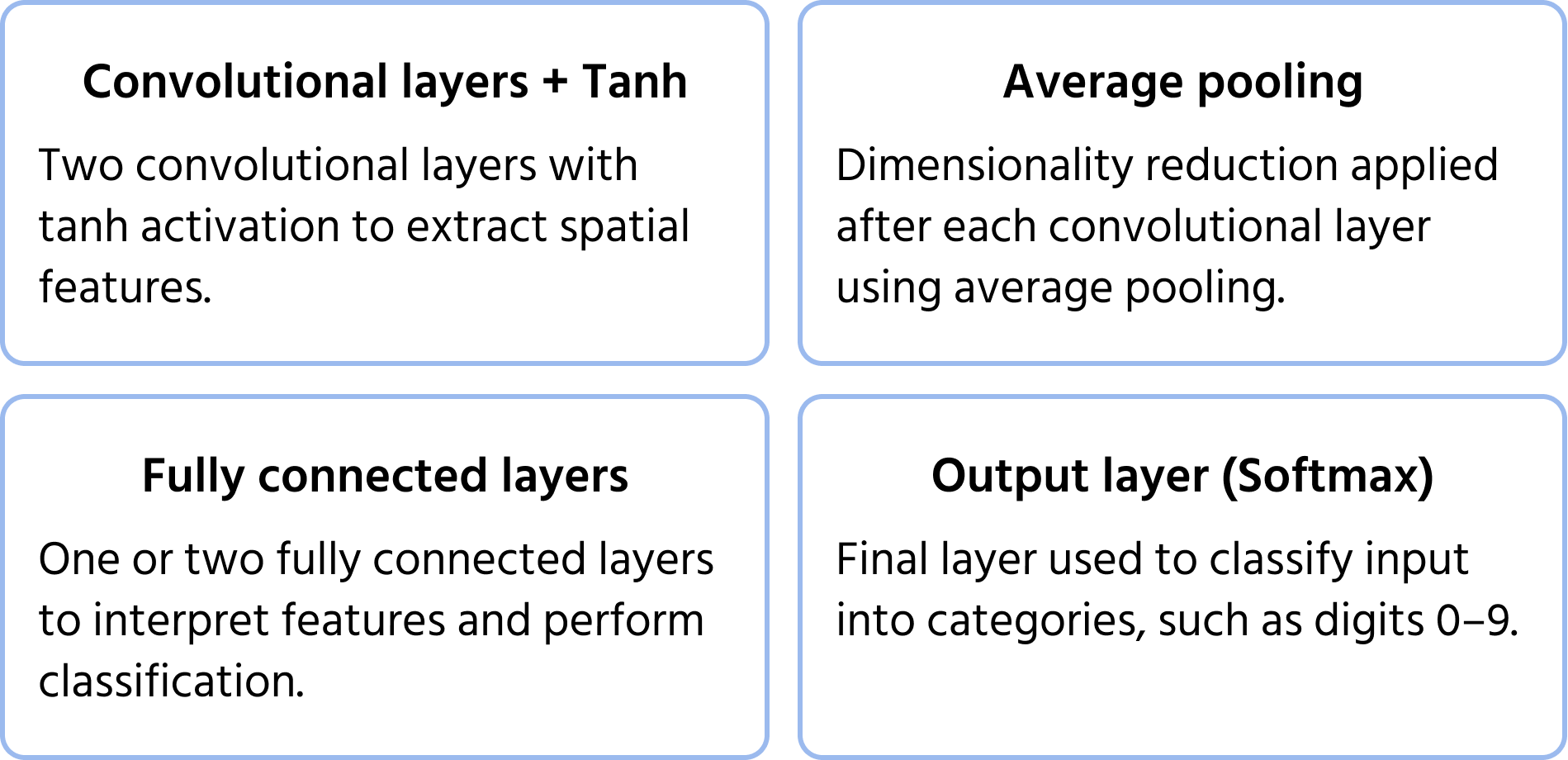
Yksi ensimmäisistä konvoluutiohermoverkkojen arkkitehtuureista, jonka Yann LeCun esitteli vuonna 1998 käsinkirjoitettujen numeroiden tunnistukseen. Se loi perustan nykyaikaisille CNN-verkoille tuomalla käyttöön keskeiset komponentit, kuten konvoluutiot, poolaus- ja täysin kytketyt kerrokset. Lisätietoja mallista löytyy dokumentaatiosta.
Keskeiset arkkitehtuuripiirteet
AlexNet: Syväoppimisen läpimurto
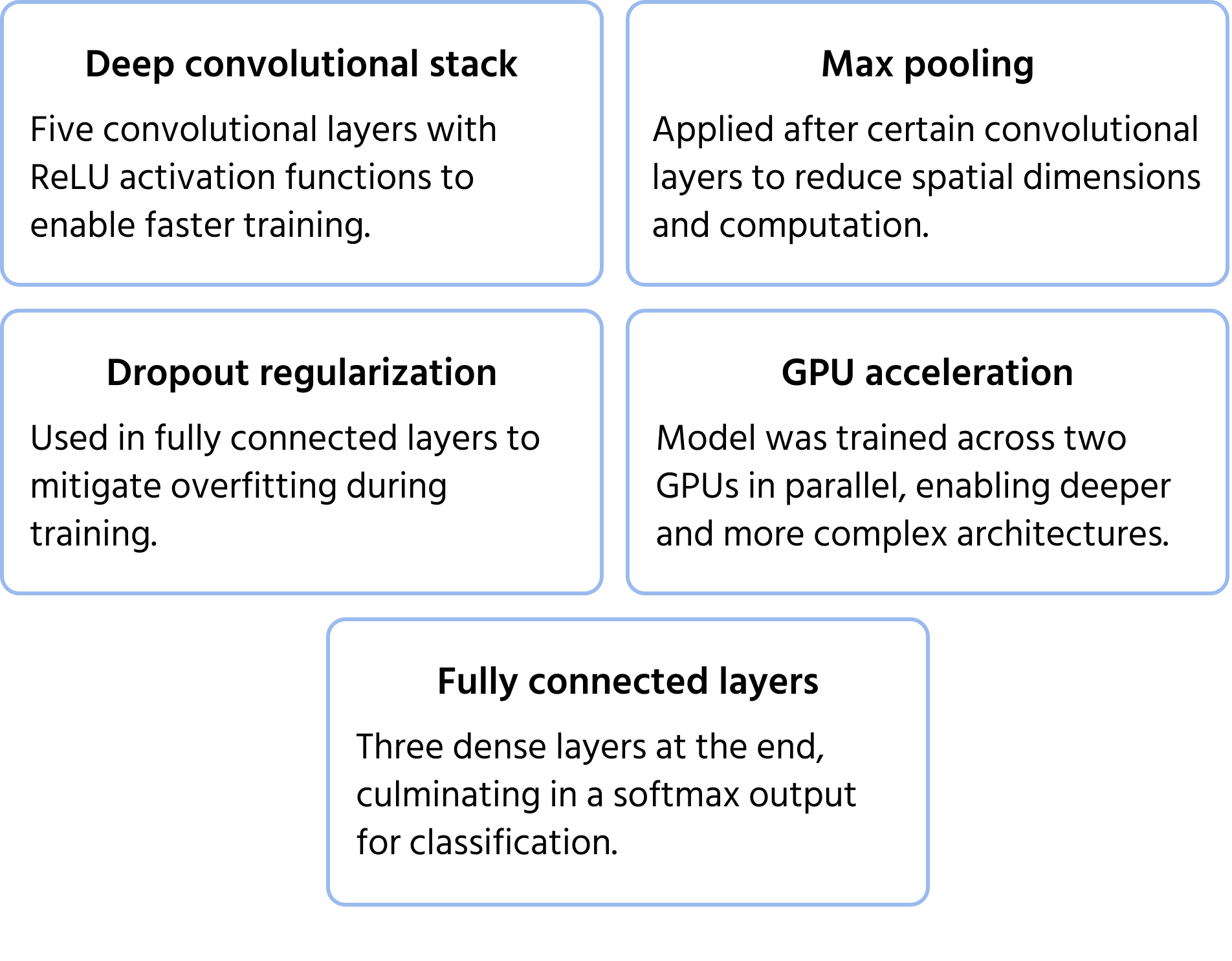
Merkittävä CNN-arkkitehtuuri, joka voitti vuoden 2012 ImageNet-kilpailun. AlexNet osoitti, että syvät konvoluutioverkot voivat ylittää perinteiset koneoppimismenetelmät laajamittaisessa kuvien luokittelussa. Se toi mukanaan innovaatioita, joista tuli standardeja modernissa syväoppimisessa. Lisätietoja mallista löytyy dokumentaatiosta.
Keskeiset arkkitehtuurin ominaisuudet
VGGNet: Syvemmät verkot yhtenäisillä suodattimilla
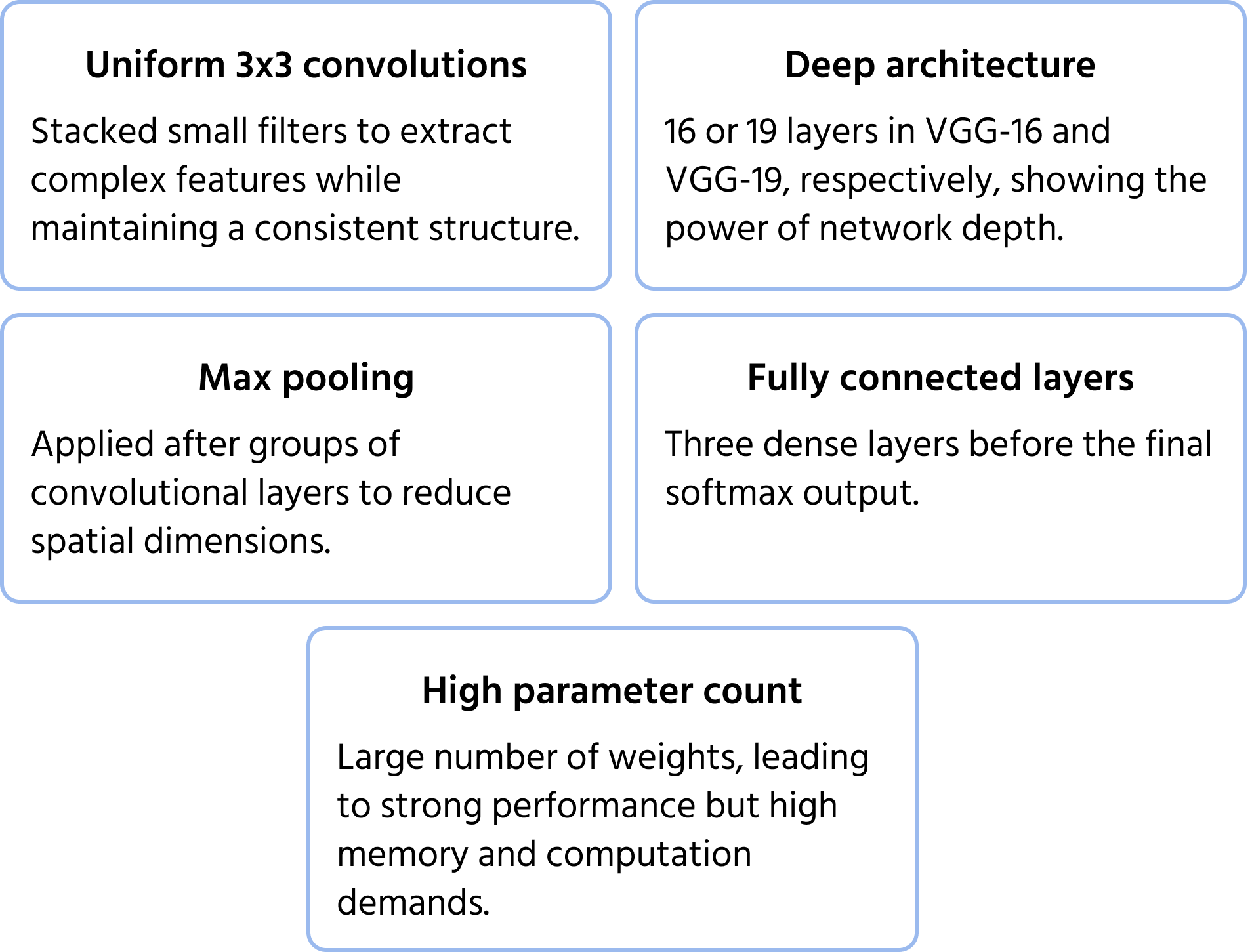
Visual Geometry Groupin (Oxford) kehittämä VGGNet korosti syvyyttä ja yksinkertaisuutta käyttämällä yhtenäisiä 3×3 konvoluutiosuodattimia. Malli osoitti, että pienten suodattimien pinoaminen syviin verkkoihin voi merkittävästi parantaa suorituskykyä, mikä johti laajasti käytettyihin versioihin, kuten VGG-16 ja VGG-19. Lisätietoja mallista löytyy dokumentaatiosta.
Keskeiset arkkitehtuuripiirteet
ResNet: Syvyyden ongelman ratkaisu
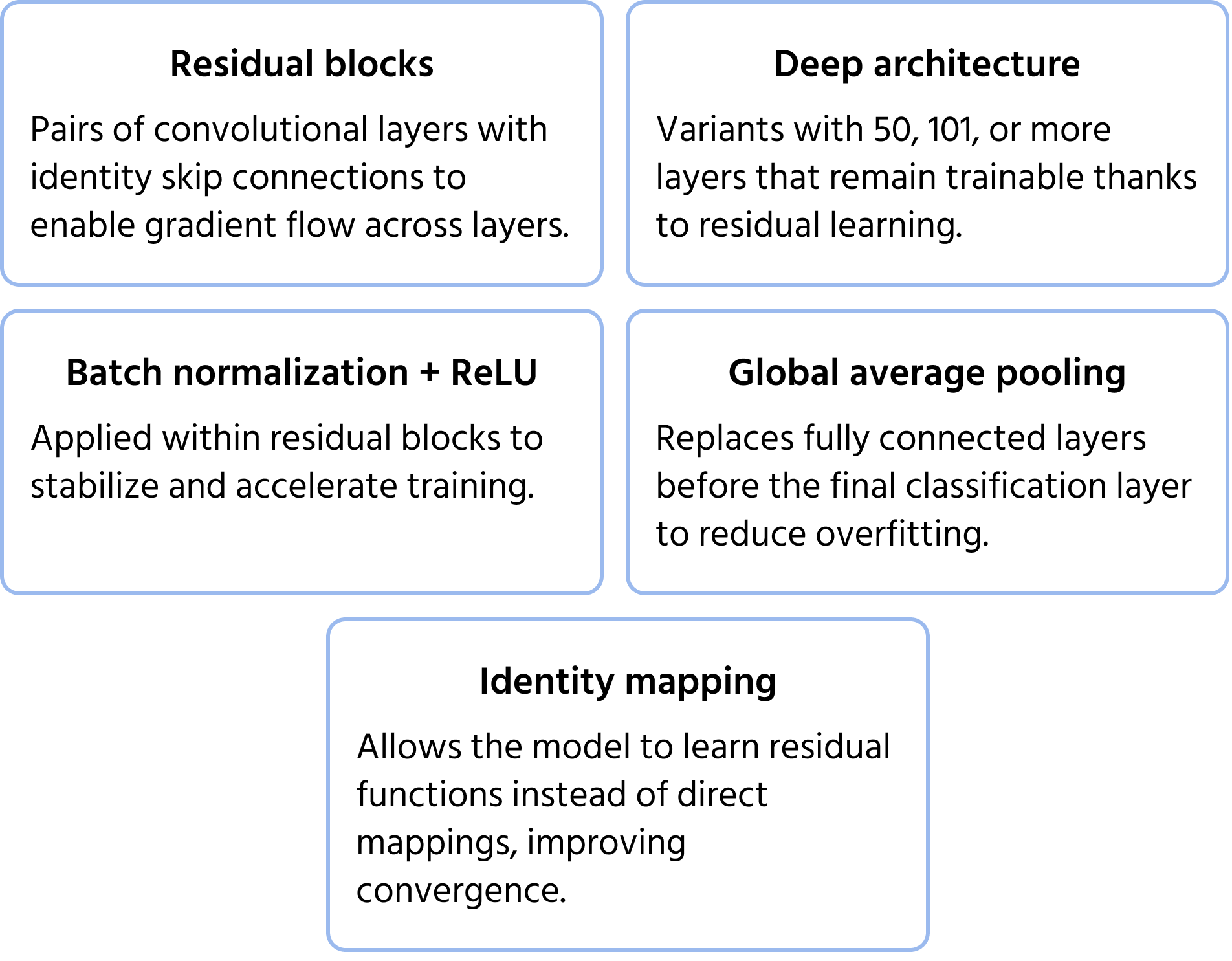
ResNet (Residual Networks), jonka Microsoft esitteli vuonna 2015, ratkaisi katoavan gradientin ongelman, joka ilmenee erittäin syvien verkkojen koulutuksessa. Perinteiset syvät verkot kohtaavat haasteita koulutustehokkuudessa ja suorituskyvyn heikkenemisessä, mutta ResNet ratkaisi tämän ongelman ohitusyhteyksillä (residual learning). Nämä oikopolut mahdollistavat tiedon kulkemisen joidenkin kerrosten ohi, varmistaen gradienttien tehokkaan etenemisen. ResNet-arkkitehtuurit, kuten ResNet-50 ja ResNet-101, mahdollistivat satojen kerrosten verkkojen koulutuksen, mikä paransi merkittävästi kuvien luokittelun tarkkuutta. Lisätietoja mallista löytyy dokumentaatiosta.
Keskeiset arkkitehtuuripiirteet
InceptionNet: Monitasoisten piirteiden erottelu
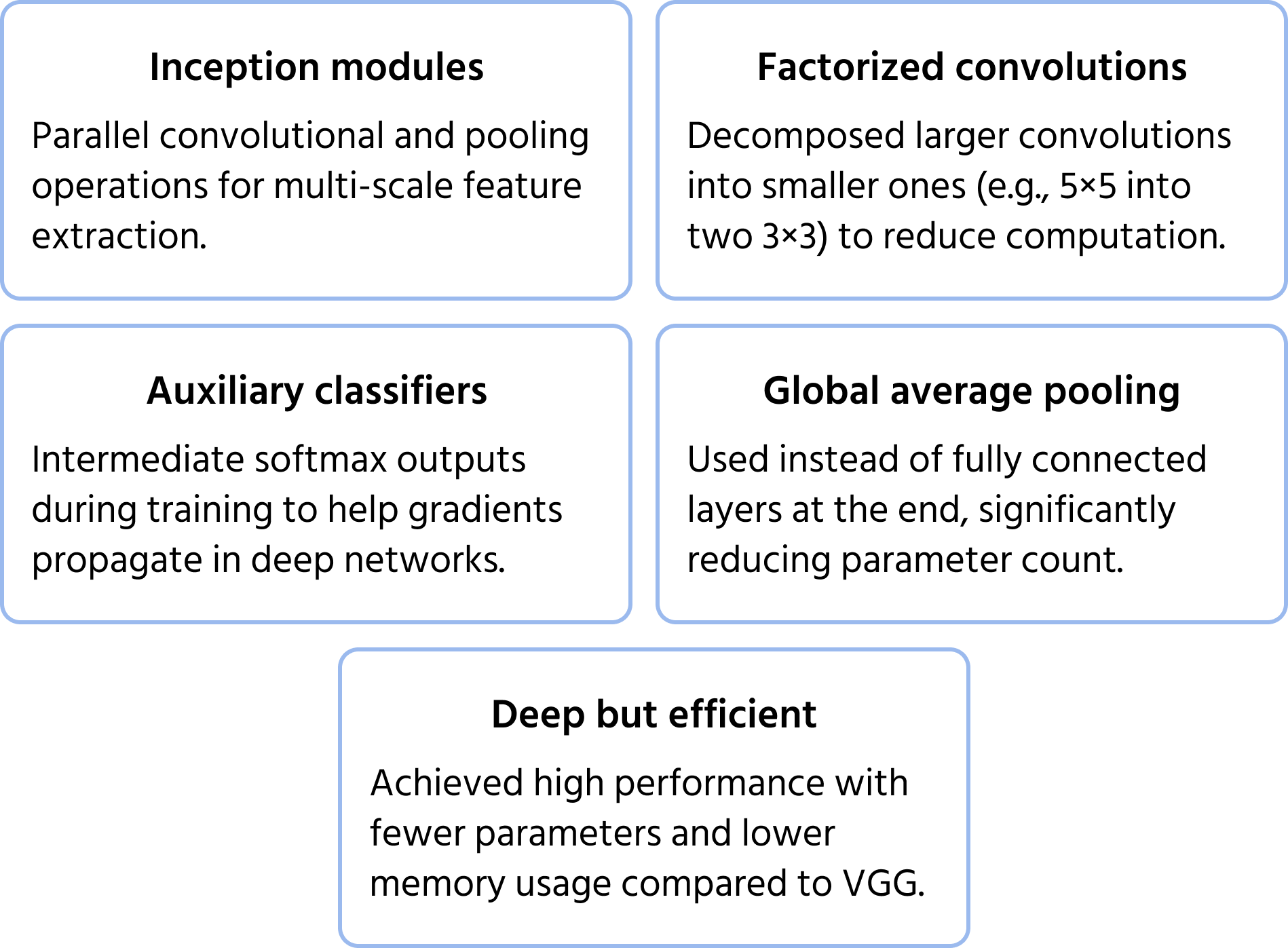
InceptionNet (tunnetaan myös nimellä GoogLeNet) perustuu inception-moduuliin muodostaen syvän mutta tehokkaan arkkitehtuurin. Kerrosten peräkkäisen pinoamisen sijaan InceptionNet hyödyntää rinnakkaisia polkuja piirteiden erotteluun eri tasoilla. Lisätietoja mallista löytyy dokumentaatiosta.
Keskeisiä optimointeja ovat:
- Faktoroidut konvoluutiot laskennallisen kustannuksen pienentämiseksi;
- Apu-luokittelijat välikerroksissa parantamaan oppimisen vakautta;
- Globaali keskiarvopoolaus täysin yhdistettyjen kerrosten sijaan, mikä vähentää parametrien määrää suorituskyvyn säilyessä.
Tämä rakenne mahdollistaa InceptionNetin olevan syvempi kuin aiemmat CNN:t, kuten VGG, ilman merkittävää laskennallisen vaatimuksen kasvua.
Keskeiset arkkitehtuuripiirteet
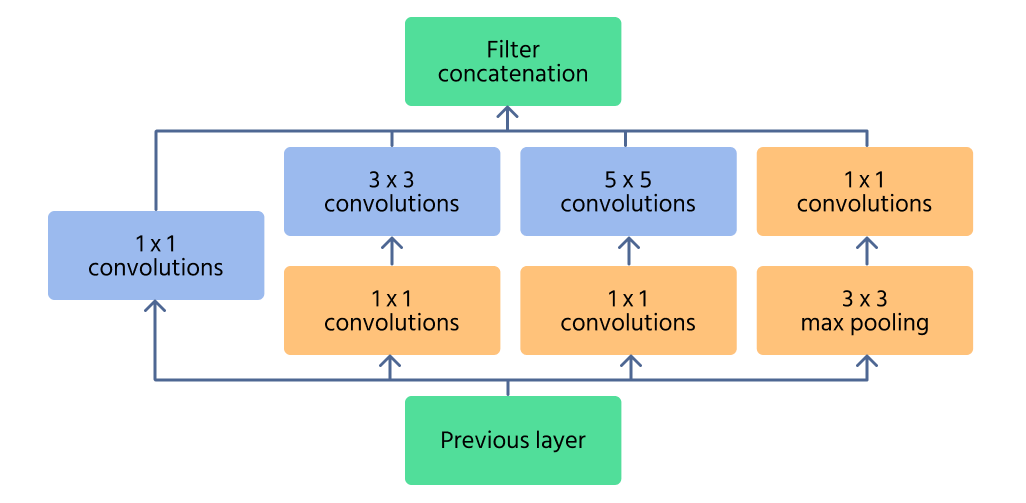
Inception-moduuli
Inception-moduuli on InceptionNetin ydinosa, joka on suunniteltu tehokkaasti havaitsemaan piirteitä useilla eri mittakaavoilla. Yhden konvoluution sijaan moduuli käsittelee syötteen rinnakkain useilla suodinkoolla (1×1, 3×3, 5×5). Tämä mahdollistaa sekä pienten yksityiskohtien että suurten kuvioiden tunnistamisen kuvasta.
Laskennallisen tehon vähentämiseksi käytetään 1×1 convolutions ennen suurempia suodattimia. Näiden avulla vähennetään syötekanavien määrää, mikä tekee verkosta tehokkaamman. Lisäksi moduulin maksimipoolauskerrokset auttavat säilyttämään olennaiset piirteet ja hallitsemaan ulottuvuuksia.
Esimerkki
Tarkastellaan esimerkkiä, jossa ulottuvuuksien pienentäminen vähentää laskennallista kuormitusta. Oletetaan, että meidän täytyy konvoloida 28 × 28 × 192 input feature maps käyttäen 5 × 5 × 32 filters. Tämä operaatio vaatii noin 120,42 miljoonaa laskutoimitusta.

Number of operations = (2828192) * (5532) = 120,422,400 operations
Suoritetaan laskelmat uudelleen, mutta tällä kertaa lisätään 1×1 convolutional layer ennen kuin sovelletaan 5×5 convolution samoihin syötekarttoihin.

Number of operations for 1x1 convolution = (2828192) * (1116) = 2.408.448 operations
Number of operations for 5x5 convolution = (282816) * (5532) = 10.035.200 operations
Total number of operations 2.408.448 + 10.035.200 = 12.443.648 operations
Jokainen näistä CNN-arkkitehtuureista on ollut keskeisessä roolissa tietokonenäön kehityksessä, vaikuttaen sovelluksiin kuten terveydenhuolto, autonomiset järjestelmät, turvallisuus ja reaaliaikainen kuvankäsittely. LeNetin perustavanlaatuisista periaatteista InceptionNetin moniskaalaiseen piirre-ekstraktioon, nämä mallit ovat jatkuvasti vieneet syväoppimisen rajoja eteenpäin, luoden pohjan entistä kehittyneemmille arkkitehtuureille tulevaisuudessa.
1. Mikä oli ResNetin ensisijainen innovaatio, joka mahdollisti erittäin syvien verkkojen kouluttamisen?
2. Miten InceptionNet parantaa laskennallista tehokkuutta verrattuna perinteisiin CNN-malleihin?
3. Mikä CNN-arkkitehtuuri esitteli ensimmäisenä käsitteen käyttää pieniä 3×3 konvoluutiosuodattimia koko verkossa?
Kiitos palautteestasi!
Kysy tekoälyä
Kysy tekoälyä

Kysy mitä tahansa tai kokeile jotakin ehdotetuista kysymyksistä aloittaaksesi keskustelumme
Yleiskatsaus Suosittuihin CNN-malleihin
Konvoluutiohermoverkot (CNN:t) ovat kehittyneet merkittävästi, ja erilaiset arkkitehtuurit ovat parantaneet tarkkuutta, tehokkuutta ja skaalautuvuutta. Tässä luvussa tarkastellaan viittä keskeistä CNN-mallia, jotka ovat muokanneet syväoppimista: LeNet, AlexNet, VGGNet, ResNet ja InceptionNet.
LeNet: CNN-verkkojen perusta
Yksi ensimmäisistä konvoluutiohermoverkkojen arkkitehtuureista, jonka Yann LeCun esitteli vuonna 1998 käsinkirjoitettujen numeroiden tunnistukseen. Se loi perustan nykyaikaisille CNN-verkoille tuomalla käyttöön keskeiset komponentit, kuten konvoluutiot, poolaus- ja täysin kytketyt kerrokset. Lisätietoja mallista löytyy dokumentaatiosta.
Keskeiset arkkitehtuuripiirteet
AlexNet: Syväoppimisen läpimurto
Merkittävä CNN-arkkitehtuuri, joka voitti vuoden 2012 ImageNet-kilpailun. AlexNet osoitti, että syvät konvoluutioverkot voivat ylittää perinteiset koneoppimismenetelmät laajamittaisessa kuvien luokittelussa. Se toi mukanaan innovaatioita, joista tuli standardeja modernissa syväoppimisessa. Lisätietoja mallista löytyy dokumentaatiosta.
Keskeiset arkkitehtuurin ominaisuudet
VGGNet: Syvemmät verkot yhtenäisillä suodattimilla
Visual Geometry Groupin (Oxford) kehittämä VGGNet korosti syvyyttä ja yksinkertaisuutta käyttämällä yhtenäisiä 3×3 konvoluutiosuodattimia. Malli osoitti, että pienten suodattimien pinoaminen syviin verkkoihin voi merkittävästi parantaa suorituskykyä, mikä johti laajasti käytettyihin versioihin, kuten VGG-16 ja VGG-19. Lisätietoja mallista löytyy dokumentaatiosta.
Keskeiset arkkitehtuuripiirteet
ResNet: Syvyyden ongelman ratkaisu
ResNet (Residual Networks), jonka Microsoft esitteli vuonna 2015, ratkaisi katoavan gradientin ongelman, joka ilmenee erittäin syvien verkkojen koulutuksessa. Perinteiset syvät verkot kohtaavat haasteita koulutustehokkuudessa ja suorituskyvyn heikkenemisessä, mutta ResNet ratkaisi tämän ongelman ohitusyhteyksillä (residual learning). Nämä oikopolut mahdollistavat tiedon kulkemisen joidenkin kerrosten ohi, varmistaen gradienttien tehokkaan etenemisen. ResNet-arkkitehtuurit, kuten ResNet-50 ja ResNet-101, mahdollistivat satojen kerrosten verkkojen koulutuksen, mikä paransi merkittävästi kuvien luokittelun tarkkuutta. Lisätietoja mallista löytyy dokumentaatiosta.
Keskeiset arkkitehtuuripiirteet
InceptionNet: Monitasoisten piirteiden erottelu
InceptionNet (tunnetaan myös nimellä GoogLeNet) perustuu inception-moduuliin muodostaen syvän mutta tehokkaan arkkitehtuurin. Kerrosten peräkkäisen pinoamisen sijaan InceptionNet hyödyntää rinnakkaisia polkuja piirteiden erotteluun eri tasoilla. Lisätietoja mallista löytyy dokumentaatiosta.
Keskeisiä optimointeja ovat:
- Faktoroidut konvoluutiot laskennallisen kustannuksen pienentämiseksi;
- Apu-luokittelijat välikerroksissa parantamaan oppimisen vakautta;
- Globaali keskiarvopoolaus täysin yhdistettyjen kerrosten sijaan, mikä vähentää parametrien määrää suorituskyvyn säilyessä.
Tämä rakenne mahdollistaa InceptionNetin olevan syvempi kuin aiemmat CNN:t, kuten VGG, ilman merkittävää laskennallisen vaatimuksen kasvua.
Keskeiset arkkitehtuuripiirteet
Inception-moduuli
Inception-moduuli on InceptionNetin ydinosa, joka on suunniteltu tehokkaasti havaitsemaan piirteitä useilla eri mittakaavoilla. Yhden konvoluution sijaan moduuli käsittelee syötteen rinnakkain useilla suodinkoolla (1×1, 3×3, 5×5). Tämä mahdollistaa sekä pienten yksityiskohtien että suurten kuvioiden tunnistamisen kuvasta.
Laskennallisen tehon vähentämiseksi käytetään 1×1 convolutions ennen suurempia suodattimia. Näiden avulla vähennetään syötekanavien määrää, mikä tekee verkosta tehokkaamman. Lisäksi moduulin maksimipoolauskerrokset auttavat säilyttämään olennaiset piirteet ja hallitsemaan ulottuvuuksia.
Esimerkki
Tarkastellaan esimerkkiä, jossa ulottuvuuksien pienentäminen vähentää laskennallista kuormitusta. Oletetaan, että meidän täytyy konvoloida 28 × 28 × 192 input feature maps käyttäen 5 × 5 × 32 filters. Tämä operaatio vaatii noin 120,42 miljoonaa laskutoimitusta.
Number of operations = (2828192) * (5532) = 120,422,400 operations
Suoritetaan laskelmat uudelleen, mutta tällä kertaa lisätään 1×1 convolutional layer ennen kuin sovelletaan 5×5 convolution samoihin syötekarttoihin.
Number of operations for 1x1 convolution = (2828192) * (1116) = 2.408.448 operations
Number of operations for 5x5 convolution = (282816) * (5532) = 10.035.200 operations
Total number of operations 2.408.448 + 10.035.200 = 12.443.648 operations
Jokainen näistä CNN-arkkitehtuureista on ollut keskeisessä roolissa tietokonenäön kehityksessä, vaikuttaen sovelluksiin kuten terveydenhuolto, autonomiset järjestelmät, turvallisuus ja reaaliaikainen kuvankäsittely. LeNetin perustavanlaatuisista periaatteista InceptionNetin moniskaalaiseen piirre-ekstraktioon, nämä mallit ovat jatkuvasti vieneet syväoppimisen rajoja eteenpäin, luoden pohjan entistä kehittyneemmille arkkitehtuureille tulevaisuudessa.
Kiitos palautteestasi!
