Word2Vecin Toteuttaminen
Pyyhkäise näyttääksesi valikon
Ymmärrettyämme, miten Word2Vec toimii, siirrytään sen toteuttamiseen Pythonilla. Gensim-kirjasto, vankka avoimen lähdekoodin työkalu luonnollisen kielen käsittelyyn, tarjoaa suoraviivaisen toteutuksen Word2Vec-luokan kautta moduulissa gensim.models.
Datan valmistelu
Word2Vec vaatii tekstidatan tokenisoinnin, eli tekstin jakamisen listojen listaksi, jossa jokainen sisempi lista sisältää tietyn lauseen sanat. Tässä esimerkissä käytämme englantilaisen kirjailijan Jane Austenin romaania Emma aineistona. Lataamme CSV-tiedoston, joka sisältää esikäsiteltyjä lauseita, ja jaamme sitten jokaisen lauseen sanoiksi:
12345678import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') # Split each sentence into words sentences = emma_df['Sentence'].str.split() # Print the fourth sentence (list of words) print(sentences[3])
emma_df['Sentence'].str.split() käyttää .split()-metodia jokaiselle lauseelle 'Sentence'-sarakkeessa, jolloin jokaisesta lauseesta muodostuu sanalista. Koska lauseet on jo esikäsitelty niin, että sanat on eroteltu välilyönneillä, .split()-metodi riittää tähän tokenisointiin.
Word2Vec-mallin kouluttaminen
Seuraavaksi keskitytään Word2Vec-mallin kouluttamiseen tokenisoidulla datalla. Word2Vec-luokka tarjoaa useita parametreja mukautusta varten. Yleisimmin käytetyt parametrit ovat:
vector_size(oletus 100): sanavektorien ulottuvuus tai koko;window(oletus 5): kontekstin ikkunan koko;min_count(oletus 5): sanat, joita esiintyy tätä vähemmän, jätetään huomiotta;sg(oletus 0): käytettävä mallin arkkitehtuuri (1 = Skip-gram, 0 = CBoW).cbow_mean(oletus 1): määrittää summataanko (0) vai keskiarvoistetaanko (1) CBoW:n syötekonteksti
Mallin arkkitehtuureista CBoW soveltuu suurille aineistoille ja tilanteisiin, joissa laskennallinen tehokkuus on tärkeää. Skip-gram puolestaan on parempi tehtäviin, joissa tarvitaan yksityiskohtaista ymmärrystä sanayhteyksistä, erityisesti pienissä aineistoissa tai harvinaisten sanojen yhteydessä.
12345678from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() # Initialize the model model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0)
Tässä asetamme upotuksen koon arvoksi 200, kontekstin ikkunan kooksi 5, ja sisällytämme kaikki sanat asettamalla min_count=1. Asettamalla sg=0 valitsemme käytettäväksi CBoW-mallin.
Oikean upotuksen koon ja kontekstin ikkunan valinta vaatii kompromisseja. Suuremmat upotukset vangitsevat enemmän merkityksiä, mutta lisäävät laskennallista kuormitusta ja ylisovittamisen riskiä. Pienemmät kontekstin ikkunat sopivat paremmin syntaksin havaitsemiseen, kun taas suuremmat ovat parempia semantiikan havaitsemisessa.
Samankaltaisten sanojen löytäminen
Kun sanat on esitetty vektoreina, niitä voidaan verrata mittaamalla niiden samankaltaisuutta. Etäisyyden käyttäminen on mahdollista, mutta vektorin suunta kantaa usein enemmän semanttista merkitystä kuin sen pituus, erityisesti sanaupotuksissa.
Kulman käyttäminen samankaltaisuusmittarina ei kuitenkaan ole kovin kätevää. Sen sijaan voidaan käyttää kahden vektorin kulman kosinia, eli kosinietäisyyttä. Sen arvot vaihtelevat välillä -1 ja 1, ja suuremmat arvot osoittavat vahvempaa samankaltaisuutta. Tämä lähestymistapa keskittyy siihen, kuinka samansuuntaisia vektorit ovat, riippumatta niiden pituudesta, mikä tekee siitä ihanteellisen sanojen merkitysten vertailuun. Tässä on havainnollistus:
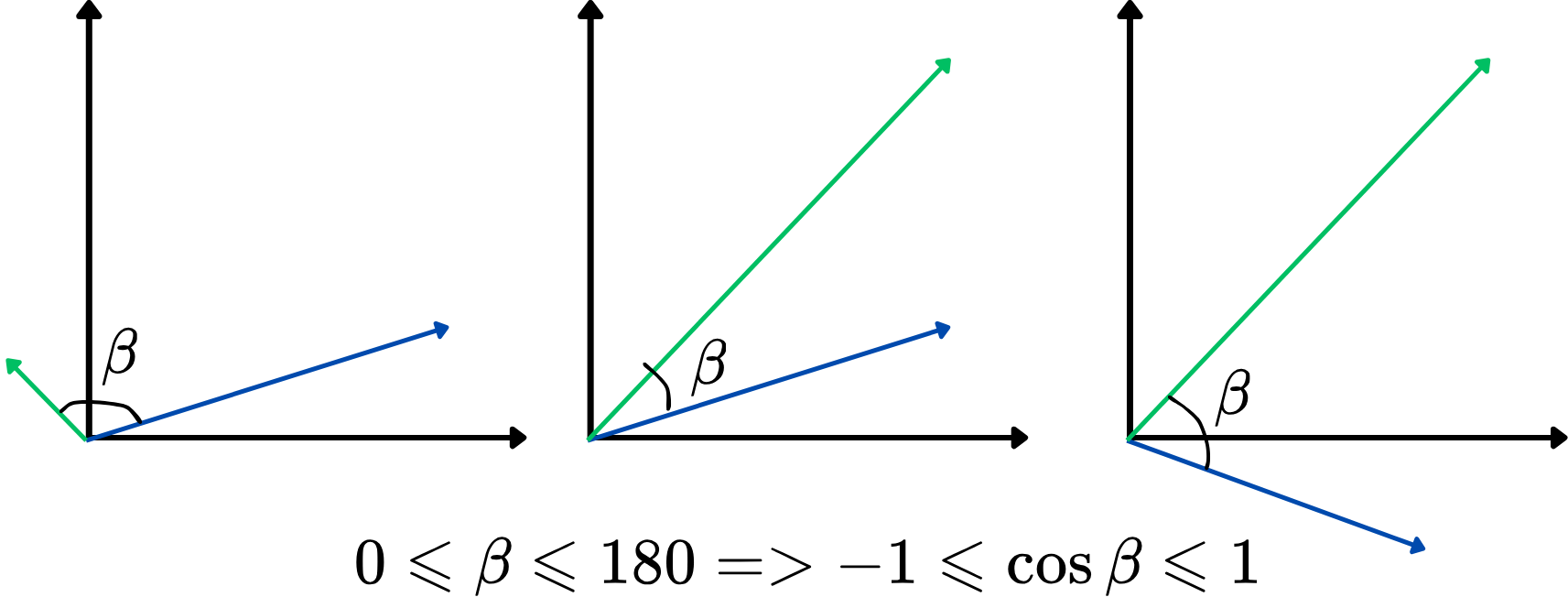
Mitä suurempi kosinietäisyys, sitä samankaltaisempia kaksi vektoria ovat, ja päinvastoin. Esimerkiksi, jos kahden sanavektorin kosinietäisyys on lähellä 1 (kulma lähellä 0 astetta), se osoittaa, että ne ovat läheisesti yhteydessä tai samankaltaisia kontekstissaan vektoriavaruudessa.
Etsitään nyt viisi eniten samankaltaista sanaa sanalle "man" käyttäen kosinietäisyyttä:
12345678910from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0) # Retrieve the top-5 most similar words to 'man' similar_words = model.wv.most_similar('man', topn=5) print(similar_words)
model.wv antaa pääsyn koulutetun mallin sanavektoreihin, kun taas .most_similar()-metodi etsii sanat, joiden upotukset ovat lähimpänä määritellyn sanan upotusta kosinietäisyyden perusteella. topn-parametri määrittää palautettavien top-N samankaltaisimpien sanojen määrän.
Kiitos palautteestasi!
Kysy tekoälyä
Kysy tekoälyä

Kysy mitä tahansa tai kokeile jotakin ehdotetuista kysymyksistä aloittaaksesi keskustelumme
Word2Vecin Toteuttaminen
Ymmärrettyämme, miten Word2Vec toimii, siirrytään sen toteuttamiseen Pythonilla. Gensim-kirjasto, vankka avoimen lähdekoodin työkalu luonnollisen kielen käsittelyyn, tarjoaa suoraviivaisen toteutuksen Word2Vec-luokan kautta moduulissa gensim.models.
Datan valmistelu
Word2Vec vaatii tekstidatan tokenisoinnin, eli tekstin jakamisen listojen listaksi, jossa jokainen sisempi lista sisältää tietyn lauseen sanat. Tässä esimerkissä käytämme englantilaisen kirjailijan Jane Austenin romaania Emma aineistona. Lataamme CSV-tiedoston, joka sisältää esikäsiteltyjä lauseita, ja jaamme sitten jokaisen lauseen sanoiksi:
12345678import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') # Split each sentence into words sentences = emma_df['Sentence'].str.split() # Print the fourth sentence (list of words) print(sentences[3])
emma_df['Sentence'].str.split() käyttää .split()-metodia jokaiselle lauseelle 'Sentence'-sarakkeessa, jolloin jokaisesta lauseesta muodostuu sanalista. Koska lauseet on jo esikäsitelty niin, että sanat on eroteltu välilyönneillä, .split()-metodi riittää tähän tokenisointiin.
Word2Vec-mallin kouluttaminen
Seuraavaksi keskitytään Word2Vec-mallin kouluttamiseen tokenisoidulla datalla. Word2Vec-luokka tarjoaa useita parametreja mukautusta varten. Yleisimmin käytetyt parametrit ovat:
vector_size(oletus 100): sanavektorien ulottuvuus tai koko;window(oletus 5): kontekstin ikkunan koko;min_count(oletus 5): sanat, joita esiintyy tätä vähemmän, jätetään huomiotta;sg(oletus 0): käytettävä mallin arkkitehtuuri (1 = Skip-gram, 0 = CBoW).cbow_mean(oletus 1): määrittää summataanko (0) vai keskiarvoistetaanko (1) CBoW:n syötekonteksti
Mallin arkkitehtuureista CBoW soveltuu suurille aineistoille ja tilanteisiin, joissa laskennallinen tehokkuus on tärkeää. Skip-gram puolestaan on parempi tehtäviin, joissa tarvitaan yksityiskohtaista ymmärrystä sanayhteyksistä, erityisesti pienissä aineistoissa tai harvinaisten sanojen yhteydessä.
12345678from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() # Initialize the model model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0)
Tässä asetamme upotuksen koon arvoksi 200, kontekstin ikkunan kooksi 5, ja sisällytämme kaikki sanat asettamalla min_count=1. Asettamalla sg=0 valitsemme käytettäväksi CBoW-mallin.
Oikean upotuksen koon ja kontekstin ikkunan valinta vaatii kompromisseja. Suuremmat upotukset vangitsevat enemmän merkityksiä, mutta lisäävät laskennallista kuormitusta ja ylisovittamisen riskiä. Pienemmät kontekstin ikkunat sopivat paremmin syntaksin havaitsemiseen, kun taas suuremmat ovat parempia semantiikan havaitsemisessa.
Samankaltaisten sanojen löytäminen
Kun sanat on esitetty vektoreina, niitä voidaan verrata mittaamalla niiden samankaltaisuutta. Etäisyyden käyttäminen on mahdollista, mutta vektorin suunta kantaa usein enemmän semanttista merkitystä kuin sen pituus, erityisesti sanaupotuksissa.
Kulman käyttäminen samankaltaisuusmittarina ei kuitenkaan ole kovin kätevää. Sen sijaan voidaan käyttää kahden vektorin kulman kosinia, eli kosinietäisyyttä. Sen arvot vaihtelevat välillä -1 ja 1, ja suuremmat arvot osoittavat vahvempaa samankaltaisuutta. Tämä lähestymistapa keskittyy siihen, kuinka samansuuntaisia vektorit ovat, riippumatta niiden pituudesta, mikä tekee siitä ihanteellisen sanojen merkitysten vertailuun. Tässä on havainnollistus:
Mitä suurempi kosinietäisyys, sitä samankaltaisempia kaksi vektoria ovat, ja päinvastoin. Esimerkiksi, jos kahden sanavektorin kosinietäisyys on lähellä 1 (kulma lähellä 0 astetta), se osoittaa, että ne ovat läheisesti yhteydessä tai samankaltaisia kontekstissaan vektoriavaruudessa.
Etsitään nyt viisi eniten samankaltaista sanaa sanalle "man" käyttäen kosinietäisyyttä:
12345678910from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0) # Retrieve the top-5 most similar words to 'man' similar_words = model.wv.most_similar('man', topn=5) print(similar_words)
model.wv antaa pääsyn koulutetun mallin sanavektoreihin, kun taas .most_similar()-metodi etsii sanat, joiden upotukset ovat lähimpänä määritellyn sanan upotusta kosinietäisyyden perusteella. topn-parametri määrittää palautettavien top-N samankaltaisimpien sanojen määrän.
Kiitos palautteestasi!
