Kuvantuotannon Yleiskatsaus
Pyyhkäise näyttääksesi valikon
Tekoälyn luomat kuvat muuttavat tapaa, jolla taidetta, suunnittelua ja digitaalista sisältöä tuotetaan. Tekoälyn avulla tietokoneet voivat nyt luoda realistisia kuvia, tukea luovaa työtä ja auttaa myös liiketoiminnassa. Tässä luvussa tarkastellaan, miten tekoäly luo kuvia, millaisia erilaisia kuvien luomiseen tarkoitettuja malleja on olemassa ja miten niitä käytetään käytännössä.
Miten tekoäly luo kuvia
Tekoälypohjainen kuvien generointi perustuu laajaan kokoelmaan kuvia, joista tekoäly oppii. Tekoäly analysoi kuvien rakenteita ja luo sitten uusia, samankaltaisia kuvia. Tämä teknologia on kehittynyt huomattavasti vuosien varrella, ja nykyään sillä voidaan tuottaa entistä realistisempia ja luovempia kuvia. Sitä hyödynnetään muun muassa videopeleissä, elokuvissa, mainonnassa ja jopa muotialalla.
Varhaiset menetelmät: PixelRNN ja PixelCNN
Ennen nykyisiä kehittyneitä tekoälymalleja tutkijat kehittivät varhaisia kuvien generointimenetelmiä, kuten PixelRNN ja PixelCNN. Nämä mallit loivat kuvia ennustamalla yhden pikselin kerrallaan.
- PixelRNN: käyttää järjestelmää nimeltä rekursiivinen neuroverkko (RNN) ennustaakseen pikselien värit yksi kerrallaan. Vaikka se toimi hyvin, se oli erittäin hidas;
- PixelCNN: paransi PixelRNN:ää käyttämällä erilaista verkkoa, konvoluutiokerroksia, mikä nopeutti kuvien luontia.
Vaikka nämä mallit olivat hyvä lähtökohta, ne eivät olleet erityisen hyviä tuottamaan korkealaatuisia kuvia. Tämä johti parempien tekniikoiden kehittämiseen.
Autoregressiiviset mallit
Autoregressiiviset mallit luovat kuvia yksi pikseli kerrallaan, hyödyntäen aiempia pikseleitä seuraavan arvauksen tekemiseen. Nämä mallit olivat hyödyllisiä mutta hitaita, mikä vähensi niiden suosiota ajan myötä. Ne kuitenkin inspiroivat uudempia ja nopeampia malleja.
Miten tekoäly ymmärtää tekstiä kuvien luomisessa
Jotkin tekoälymallit voivat muuntaa kirjoitetut sanat kuviksi. Nämä mallit käyttävät Large Language Models (LLM) -malleja ymmärtääkseen kuvaukset ja luodakseen niitä vastaavia kuvia. Esimerkiksi, jos kirjoitat “a cat sitting on a beach at sunset”, tekoäly luo kuvan tämän kuvauksen perusteella.
Tekoälymallit kuten OpenAI:n DALL-E ja Googlen Imagen hyödyntävät kehittynyttä kielten ymmärrystä parantaakseen tekstikuvausten ja luotujen kuvien yhteensopivuutta. Tämä on mahdollista Natural Language Processing (NLP) -tekniikan avulla, joka auttaa tekoälyä muuntamaan sanat numeroiksi, jotka ohjaavat kuvien luontia.
Generatiiviset vastakkaisverkot (GAN)
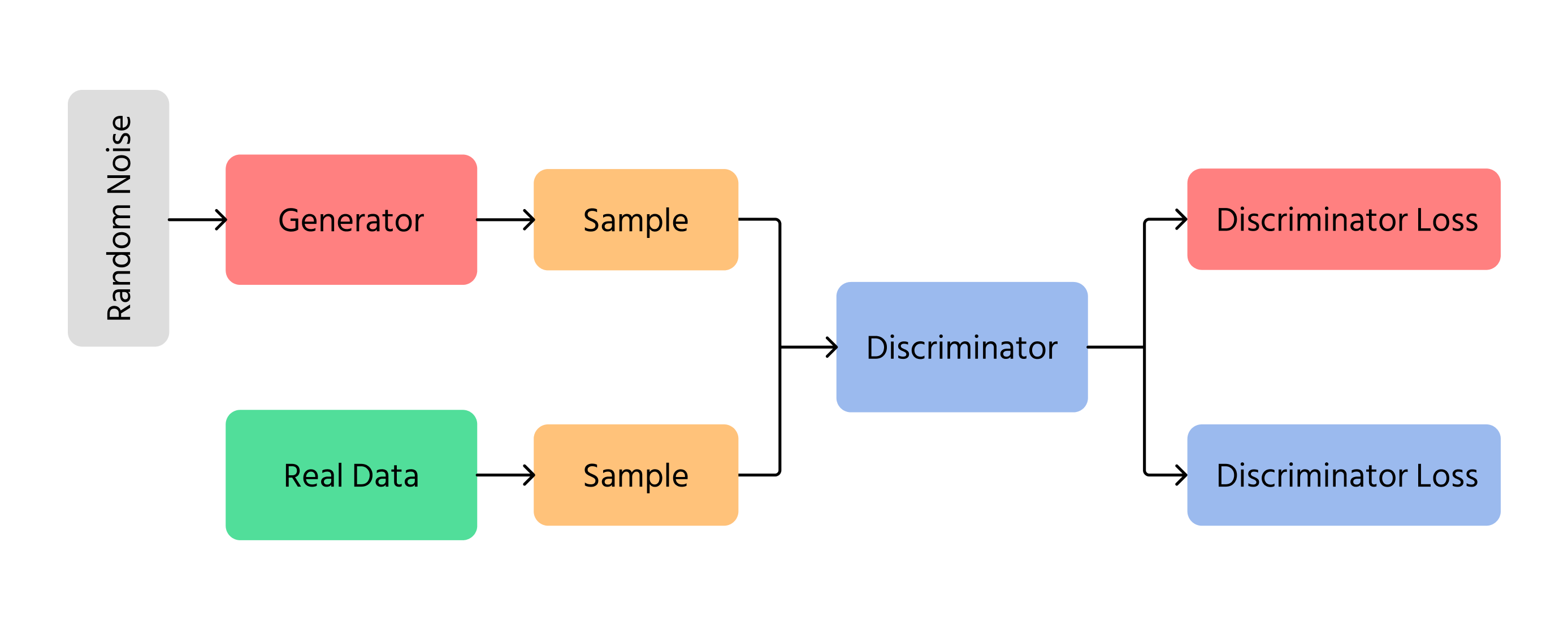
Yksi merkittävimmistä edistysaskeleista tekoälyn kuvageneroinnissa oli Generative Adversarial Networks (GAN). GAN-mallit toimivat kahden erilaisen neuroverkon avulla:
- Generaattori: luo uusia kuvia tyhjästä;
- Erottelija: tarkistaa, näyttävätkö kuvat aidoilta vai keinotekoisilta.
Generaattori pyrkii tekemään kuvista niin realistisia, ettei erottelija tunnista niitä keinotekoisiksi. Ajan myötä kuvat paranevat ja muistuttavat yhä enemmän aitoja valokuvia. GAN-malleja käytetään deepfake-teknologiassa, taiteen luomisessa ja kuvanlaadun parantamisessa.
Variational Autoencoders (VAE:t)
VAE:t ovat toinen tapa, jolla tekoäly voi luoda kuvia. GAN-menetelmän kilpailun sijaan VAE:t koodaavat ja dekoodaavat kuvia todennäköisyyksiin perustuen. Ne oppivat kuvan taustalla olevat rakenteet ja rekonstruoivat sen pienin vaihteluin. VAE:iden todennäköisyyspohjainen lähestymistapa varmistaa, että jokainen luotu kuva on hieman erilainen, mikä tuo vaihtelua ja luovuutta.
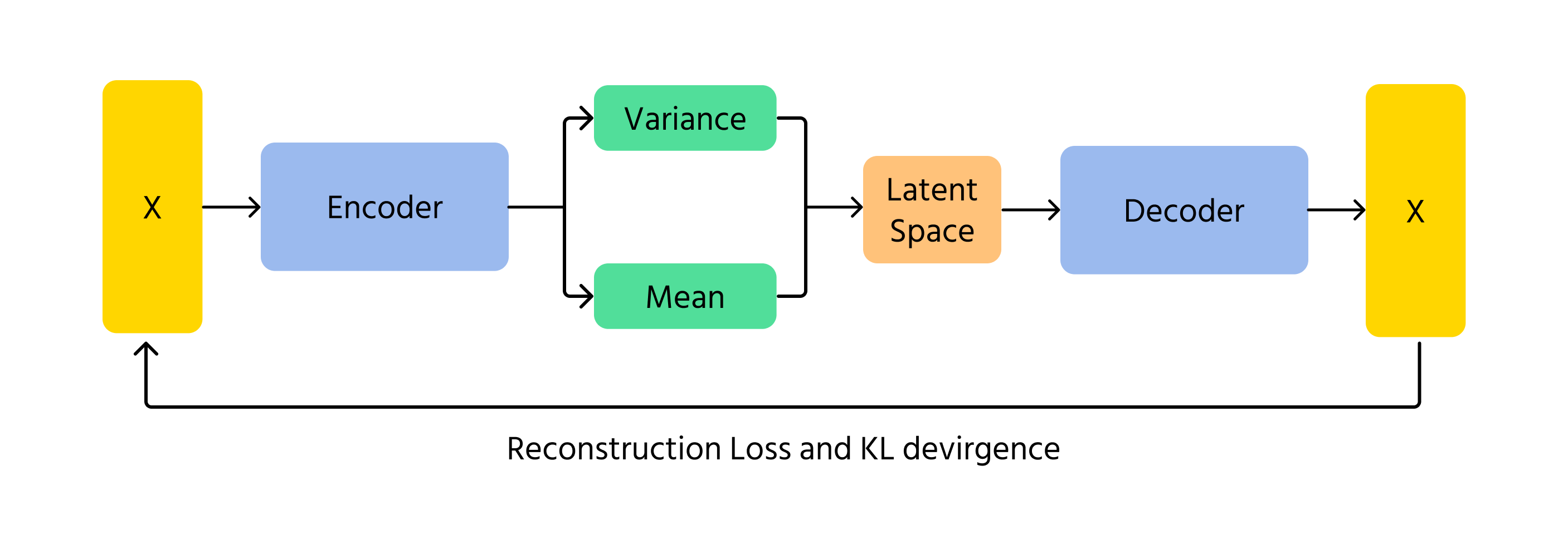
Keskeinen käsite VAE-malleissa on Kullback-Leibler (KL) -divergenssi, joka mittaa opitun jakauman ja standardin normaalijakauman välistä eroa. KL-divergenssiä minimoimalla VAE-mallit varmistavat, että generoitu kuvat pysyvät realistisina, mutta mahdollistavat silti luovat variaatiot.
VAE-mallien toiminta
- Koodaus: syötedata x syötetään kooderiin, joka tuottaa latenttitilan jakauman q(z∣x) (keskiarvo μ ja varianssi σ²) parametrit;
- Latenttitilan näytteenotto: latenttimuuttujat z näytteistetään jakaumasta q(z∣x) käyttäen esimerkiksi reparametrisointikikkaa;
- Dekoodaus ja rekonstruktio: näytteistetty z syötetään dekooderiin, joka tuottaa rekonstruoidun datan x̂, jonka tulisi olla samankaltainen alkuperäisen syötteen x kanssa.
VAE-mallit soveltuvat esimerkiksi kasvojen rekonstruointiin, uusien versioiden luomiseen olemassa olevista kuvista sekä sujuvien siirtymien tekemiseen eri kuvien välillä.
Diffuusiomallit
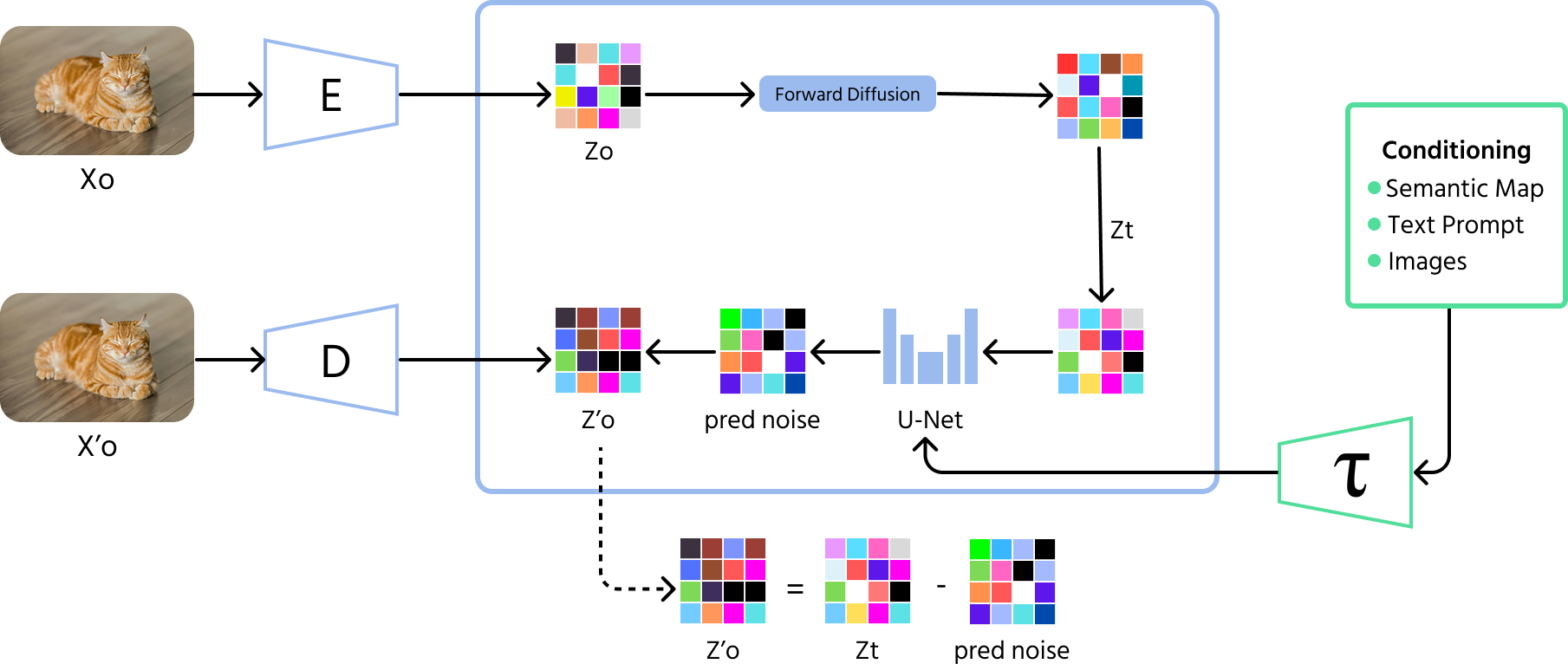
Diffuusiomallit ovat viimeisin läpimurto tekoälyn generoimissa kuvissa. Nämä mallit aloittavat satunnaisesta kohinasta ja parantavat kuvaa vaihe vaiheelta, aivan kuin poistaisivat häiriötä sumeasta valokuvasta. Toisin kuin GAN-mallit, jotka joskus tuottavat rajallisia variaatioita, diffuusiomallit voivat luoda laajemman valikoiman korkealaatuisia kuvia.
Diffuusiomallien toimintaperiaate
- Etenevä prosessi (kohinan lisääminen): malli aloittaa lisäämällä satunnaista kohinaa kuvaan useiden vaiheiden aikana, kunnes kuva muuttuu täysin tunnistamattomaksi;
- Käänteinen prosessi (kohinan poisto): malli oppii tämän jälkeen kääntämään prosessin, poistamalla kohinaa vaihe vaiheelta ja palauttamalla merkityksellisen kuvan;
- Koulutus: diffuusiomallit opetetaan ennustamaan ja poistamaan kohinaa jokaisessa vaiheessa, mikä auttaa niitä tuottamaan selkeitä ja korkealaatuisia kuvia satunnaisesta kohinasta.
Tunnettuja esimerkkejä ovat MidJourney, DALL-E ja Stable Diffusion, joka tunnetaan realististen ja taiteellisten kuvien tuottamisesta. Diffuusiomalleja käytetään laajasti tekoälypohjaisessa taiteessa, korkean resoluution kuvien synteesissä ja luovissa suunnittelusovelluksissa.
Diffuusiomallien tuottamien kuvien esimerkkejä

Realistinen kuva koripalloilijasta, jolla on parta ja kelta-violetti peliasu, tekemässä donkkia ja voittamassa demoneita koripallo-ottelussa, kaikki tapahtuu helvetissä.

Surrealistinen kaunis taiteellinen valokuva valkoisesta 1990 Volkswagen Golf GTI:stä loputtomalla valkoisten kukkien niityllä, harmoniassa luonnon kanssa, keskellä loputtomia kukkuloita täynnä kukkia, kasvitieteellinen, luonnonvalo, taiteellinen, sumuinen ja utuinen valokuvarealistinen surrealistinen erittäin yksityiskohtainen, kodak-filmi, luonnonvalo, laajakulmaobjektiivi, f 1.20

Beigenvärisen villakoiran maalaus, joka makaa vihreällä sohvalla vihreä-valkoraidallisen tyynyn kanssa, Fairfield Porterin tyyliin, abstrakti ekspressionismi, rohkeat siveltimenvedot beigellä taustalla

Äärimmäisen lähikuva välimerellisen tai latinalaisamerikkalaisen naisen ihosta, jossa korostuu sekaihotyyppi: otsa ja nenä ovat selvästi rasvaisemmat, kun taas posket näyttävät kuivemmilta ja hieman hilseileviltä. T-alueen ihohuokoset ovat näkyvämmät, ja luonnollinen kiilto heijastaa talintuotantoa. Iho sisältää lämpimiä ja kultaisia pohjasävyjä, ja sen rakenne on epätasainen vaihtelevan kosteustasapainon vuoksi. Pehmeä, luonnollinen valaistus korostaa realistista kontrastia kuivien ja rasvaisten alueiden välillä. Tausta on sumennettu, jotta huomio kiinnittyy ihon sävyyn.
Haasteet ja eettiset kysymykset
Vaikka tekoälyn tuottamat kuvat ovat vaikuttavia, niihin liittyy haasteita:
- Hallinnan puute: tekoäly ei aina tuota juuri käyttäjän toivomaa lopputulosta;
- Laskentateho: laadukkaiden tekoälykuvien luominen vaatii kalliita ja tehokkaita tietokoneita;
- Vinoumat malleissa: koska tekoäly oppii olemassa olevista kuvista, se voi toisinaan toistaa datassa esiintyviä vinoumia.
Lisäksi on olemassa eettisiä kysymyksiä:
- Kuka omistaa tekoälytaiteen?: jos tekoäly luo taideteoksen, kuuluuko omistajuus käyttäjälle vai tekoälyä kehittävälle yritykselle?
- Väärennetyt kuvat ja deepfake-teknologia: GAN-malleilla voidaan luoda aidon näköisiä väärennettyjä kuvia, mikä voi johtaa harhaanjohtamiseen ja yksityisyysongelmiin.
Tekoälykuvien nykyiset käyttökohteet
Tekoälyn tuottamat kuvat vaikuttavat jo monilla toimialoilla:
- Viihde: videopeleissä, elokuvissa ja animaatioissa käytetään tekoälyä taustojen, hahmojen ja tehosteiden luomiseen;
- Muoti: suunnittelijat hyödyntävät tekoälyä uusien vaatteiden suunnittelussa, ja verkkokaupat tarjoavat virtuaalisia sovituksia asiakkaille;
- Graafinen suunnittelu: tekoäly auttaa taiteilijoita ja suunnittelijoita luomaan nopeasti logoja, julisteita ja markkinointimateriaaleja.
Tekoälyn kuvageneroinnin tulevaisuus
Tekoälypohjaisen kuvageneroinnin kehittyessä se muuttaa jatkuvasti tapaa, jolla ihmiset luovat ja käyttävät kuvia. Taiteessa, liiketoiminnassa tai viihteessä tekoäly avaa uusia mahdollisuuksia ja tekee luovasta työstä helpompaa ja innostavampaa.
1. Mikä on tekoälypohjaisen kuvageneroinnin päätarkoitus?
2. Miten generatiiviset vastakkaisverkot (GAN) toimivat?
3. Mikä tekoälymalli aloittaa satunnaisesta kohinasta ja parantaa kuvaa vaihe vaiheelta?
Kiitos palautteestasi!
Kysy tekoälyä
Kysy tekoälyä

Kysy mitä tahansa tai kokeile jotakin ehdotetuista kysymyksistä aloittaaksesi keskustelumme
Kuvantuotannon Yleiskatsaus
Tekoälyn luomat kuvat muuttavat tapaa, jolla taidetta, suunnittelua ja digitaalista sisältöä tuotetaan. Tekoälyn avulla tietokoneet voivat nyt luoda realistisia kuvia, tukea luovaa työtä ja auttaa myös liiketoiminnassa. Tässä luvussa tarkastellaan, miten tekoäly luo kuvia, millaisia erilaisia kuvien luomiseen tarkoitettuja malleja on olemassa ja miten niitä käytetään käytännössä.
Miten tekoäly luo kuvia
Tekoälypohjainen kuvien generointi perustuu laajaan kokoelmaan kuvia, joista tekoäly oppii. Tekoäly analysoi kuvien rakenteita ja luo sitten uusia, samankaltaisia kuvia. Tämä teknologia on kehittynyt huomattavasti vuosien varrella, ja nykyään sillä voidaan tuottaa entistä realistisempia ja luovempia kuvia. Sitä hyödynnetään muun muassa videopeleissä, elokuvissa, mainonnassa ja jopa muotialalla.
Varhaiset menetelmät: PixelRNN ja PixelCNN
Ennen nykyisiä kehittyneitä tekoälymalleja tutkijat kehittivät varhaisia kuvien generointimenetelmiä, kuten PixelRNN ja PixelCNN. Nämä mallit loivat kuvia ennustamalla yhden pikselin kerrallaan.
- PixelRNN: käyttää järjestelmää nimeltä rekursiivinen neuroverkko (RNN) ennustaakseen pikselien värit yksi kerrallaan. Vaikka se toimi hyvin, se oli erittäin hidas;
- PixelCNN: paransi PixelRNN:ää käyttämällä erilaista verkkoa, konvoluutiokerroksia, mikä nopeutti kuvien luontia.
Vaikka nämä mallit olivat hyvä lähtökohta, ne eivät olleet erityisen hyviä tuottamaan korkealaatuisia kuvia. Tämä johti parempien tekniikoiden kehittämiseen.
Autoregressiiviset mallit
Autoregressiiviset mallit luovat kuvia yksi pikseli kerrallaan, hyödyntäen aiempia pikseleitä seuraavan arvauksen tekemiseen. Nämä mallit olivat hyödyllisiä mutta hitaita, mikä vähensi niiden suosiota ajan myötä. Ne kuitenkin inspiroivat uudempia ja nopeampia malleja.
Miten tekoäly ymmärtää tekstiä kuvien luomisessa
Jotkin tekoälymallit voivat muuntaa kirjoitetut sanat kuviksi. Nämä mallit käyttävät Large Language Models (LLM) -malleja ymmärtääkseen kuvaukset ja luodakseen niitä vastaavia kuvia. Esimerkiksi, jos kirjoitat “a cat sitting on a beach at sunset”, tekoäly luo kuvan tämän kuvauksen perusteella.
Tekoälymallit kuten OpenAI:n DALL-E ja Googlen Imagen hyödyntävät kehittynyttä kielten ymmärrystä parantaakseen tekstikuvausten ja luotujen kuvien yhteensopivuutta. Tämä on mahdollista Natural Language Processing (NLP) -tekniikan avulla, joka auttaa tekoälyä muuntamaan sanat numeroiksi, jotka ohjaavat kuvien luontia.
Generatiiviset vastakkaisverkot (GAN)
Yksi merkittävimmistä edistysaskeleista tekoälyn kuvageneroinnissa oli Generative Adversarial Networks (GAN). GAN-mallit toimivat kahden erilaisen neuroverkon avulla:
- Generaattori: luo uusia kuvia tyhjästä;
- Erottelija: tarkistaa, näyttävätkö kuvat aidoilta vai keinotekoisilta.
Generaattori pyrkii tekemään kuvista niin realistisia, ettei erottelija tunnista niitä keinotekoisiksi. Ajan myötä kuvat paranevat ja muistuttavat yhä enemmän aitoja valokuvia. GAN-malleja käytetään deepfake-teknologiassa, taiteen luomisessa ja kuvanlaadun parantamisessa.
Variational Autoencoders (VAE:t)
VAE:t ovat toinen tapa, jolla tekoäly voi luoda kuvia. GAN-menetelmän kilpailun sijaan VAE:t koodaavat ja dekoodaavat kuvia todennäköisyyksiin perustuen. Ne oppivat kuvan taustalla olevat rakenteet ja rekonstruoivat sen pienin vaihteluin. VAE:iden todennäköisyyspohjainen lähestymistapa varmistaa, että jokainen luotu kuva on hieman erilainen, mikä tuo vaihtelua ja luovuutta.
Keskeinen käsite VAE-malleissa on Kullback-Leibler (KL) -divergenssi, joka mittaa opitun jakauman ja standardin normaalijakauman välistä eroa. KL-divergenssiä minimoimalla VAE-mallit varmistavat, että generoitu kuvat pysyvät realistisina, mutta mahdollistavat silti luovat variaatiot.
VAE-mallien toiminta
- Koodaus: syötedata x syötetään kooderiin, joka tuottaa latenttitilan jakauman q(z∣x) (keskiarvo μ ja varianssi σ²) parametrit;
- Latenttitilan näytteenotto: latenttimuuttujat z näytteistetään jakaumasta q(z∣x) käyttäen esimerkiksi reparametrisointikikkaa;
- Dekoodaus ja rekonstruktio: näytteistetty z syötetään dekooderiin, joka tuottaa rekonstruoidun datan x̂, jonka tulisi olla samankaltainen alkuperäisen syötteen x kanssa.
VAE-mallit soveltuvat esimerkiksi kasvojen rekonstruointiin, uusien versioiden luomiseen olemassa olevista kuvista sekä sujuvien siirtymien tekemiseen eri kuvien välillä.
Diffuusiomallit
Diffuusiomallit ovat viimeisin läpimurto tekoälyn generoimissa kuvissa. Nämä mallit aloittavat satunnaisesta kohinasta ja parantavat kuvaa vaihe vaiheelta, aivan kuin poistaisivat häiriötä sumeasta valokuvasta. Toisin kuin GAN-mallit, jotka joskus tuottavat rajallisia variaatioita, diffuusiomallit voivat luoda laajemman valikoiman korkealaatuisia kuvia.
Diffuusiomallien toimintaperiaate
- Etenevä prosessi (kohinan lisääminen): malli aloittaa lisäämällä satunnaista kohinaa kuvaan useiden vaiheiden aikana, kunnes kuva muuttuu täysin tunnistamattomaksi;
- Käänteinen prosessi (kohinan poisto): malli oppii tämän jälkeen kääntämään prosessin, poistamalla kohinaa vaihe vaiheelta ja palauttamalla merkityksellisen kuvan;
- Koulutus: diffuusiomallit opetetaan ennustamaan ja poistamaan kohinaa jokaisessa vaiheessa, mikä auttaa niitä tuottamaan selkeitä ja korkealaatuisia kuvia satunnaisesta kohinasta.
Tunnettuja esimerkkejä ovat MidJourney, DALL-E ja Stable Diffusion, joka tunnetaan realististen ja taiteellisten kuvien tuottamisesta. Diffuusiomalleja käytetään laajasti tekoälypohjaisessa taiteessa, korkean resoluution kuvien synteesissä ja luovissa suunnittelusovelluksissa.
Diffuusiomallien tuottamien kuvien esimerkkejä
Realistinen kuva koripalloilijasta, jolla on parta ja kelta-violetti peliasu, tekemässä donkkia ja voittamassa demoneita koripallo-ottelussa, kaikki tapahtuu helvetissä.
Surrealistinen kaunis taiteellinen valokuva valkoisesta 1990 Volkswagen Golf GTI:stä loputtomalla valkoisten kukkien niityllä, harmoniassa luonnon kanssa, keskellä loputtomia kukkuloita täynnä kukkia, kasvitieteellinen, luonnonvalo, taiteellinen, sumuinen ja utuinen valokuvarealistinen surrealistinen erittäin yksityiskohtainen, kodak-filmi, luonnonvalo, laajakulmaobjektiivi, f 1.20
Beigenvärisen villakoiran maalaus, joka makaa vihreällä sohvalla vihreä-valkoraidallisen tyynyn kanssa, Fairfield Porterin tyyliin, abstrakti ekspressionismi, rohkeat siveltimenvedot beigellä taustalla
Äärimmäisen lähikuva välimerellisen tai latinalaisamerikkalaisen naisen ihosta, jossa korostuu sekaihotyyppi: otsa ja nenä ovat selvästi rasvaisemmat, kun taas posket näyttävät kuivemmilta ja hieman hilseileviltä. T-alueen ihohuokoset ovat näkyvämmät, ja luonnollinen kiilto heijastaa talintuotantoa. Iho sisältää lämpimiä ja kultaisia pohjasävyjä, ja sen rakenne on epätasainen vaihtelevan kosteustasapainon vuoksi. Pehmeä, luonnollinen valaistus korostaa realistista kontrastia kuivien ja rasvaisten alueiden välillä. Tausta on sumennettu, jotta huomio kiinnittyy ihon sävyyn.
Haasteet ja eettiset kysymykset
Vaikka tekoälyn tuottamat kuvat ovat vaikuttavia, niihin liittyy haasteita:
- Hallinnan puute: tekoäly ei aina tuota juuri käyttäjän toivomaa lopputulosta;
- Laskentateho: laadukkaiden tekoälykuvien luominen vaatii kalliita ja tehokkaita tietokoneita;
- Vinoumat malleissa: koska tekoäly oppii olemassa olevista kuvista, se voi toisinaan toistaa datassa esiintyviä vinoumia.
Lisäksi on olemassa eettisiä kysymyksiä:
- Kuka omistaa tekoälytaiteen?: jos tekoäly luo taideteoksen, kuuluuko omistajuus käyttäjälle vai tekoälyä kehittävälle yritykselle?
- Väärennetyt kuvat ja deepfake-teknologia: GAN-malleilla voidaan luoda aidon näköisiä väärennettyjä kuvia, mikä voi johtaa harhaanjohtamiseen ja yksityisyysongelmiin.
Tekoälykuvien nykyiset käyttökohteet
Tekoälyn tuottamat kuvat vaikuttavat jo monilla toimialoilla:
- Viihde: videopeleissä, elokuvissa ja animaatioissa käytetään tekoälyä taustojen, hahmojen ja tehosteiden luomiseen;
- Muoti: suunnittelijat hyödyntävät tekoälyä uusien vaatteiden suunnittelussa, ja verkkokaupat tarjoavat virtuaalisia sovituksia asiakkaille;
- Graafinen suunnittelu: tekoäly auttaa taiteilijoita ja suunnittelijoita luomaan nopeasti logoja, julisteita ja markkinointimateriaaleja.
Tekoälyn kuvageneroinnin tulevaisuus
Tekoälypohjaisen kuvageneroinnin kehittyessä se muuttaa jatkuvasti tapaa, jolla ihmiset luovat ja käyttävät kuvia. Taiteessa, liiketoiminnassa tai viihteessä tekoäly avaa uusia mahdollisuuksia ja tekee luovasta työstä helpompaa ja innostavampaa.
Kiitos palautteestasi!
