YOLO-mallin Yleiskatsaus
Pyyhkäise näyttääksesi valikon
YOLO (You Only Look Once) -algoritmi on nopea ja tehokas objektintunnistusmalli. Toisin kuin perinteiset lähestymistavat, kuten R-CNN, jotka käyttävät useita vaiheita, YOLO käsittelee koko kuvan yhdellä kertaa, mikä tekee siitä ihanteellisen reaaliaikaisiin sovelluksiin.
Miten YOLO eroaa R-CNN-lähestymistavoista
Perinteiset objektintunnistusmenetelmät, kuten R-CNN ja sen variantit, perustuvat kaksivaiheiseen prosessiin: ensin luodaan alue-ehdotuksia, minkä jälkeen jokainen ehdotettu alue luokitellaan. Vaikka tämä lähestymistapa on tehokas, se on laskennallisesti raskas ja hidastaa päättelyä, mikä tekee siitä vähemmän sopivan reaaliaikaisiin sovelluksiin.
YOLO (You Only Look Once) käyttää täysin erilaista lähestymistapaa. Se jakaa syötekuvan ruudukkoon ja ennustaa rajauslaatikot sekä luokkien todennäköisyydet jokaiselle ruudulle yhdellä eteenpäin suuntautuvalla laskennalla. Tämä malli muotoilee objektintunnistuksen yhtenä regressio-ongelmana, mikä mahdollistaa YOLO:n reaaliaikaisen suorituskyvyn.
Toisin kuin R-CNN-pohjaiset menetelmät, jotka keskittyvät vain paikallisiin alueisiin, YOLO käsittelee koko kuvan kerralla, jolloin se pystyy hyödyntämään globaalia kontekstuaalista tietoa. Tämä parantaa suorituskykyä useiden tai päällekkäisten objektien tunnistuksessa, säilyttäen samalla korkean nopeuden ja tarkkuuden.
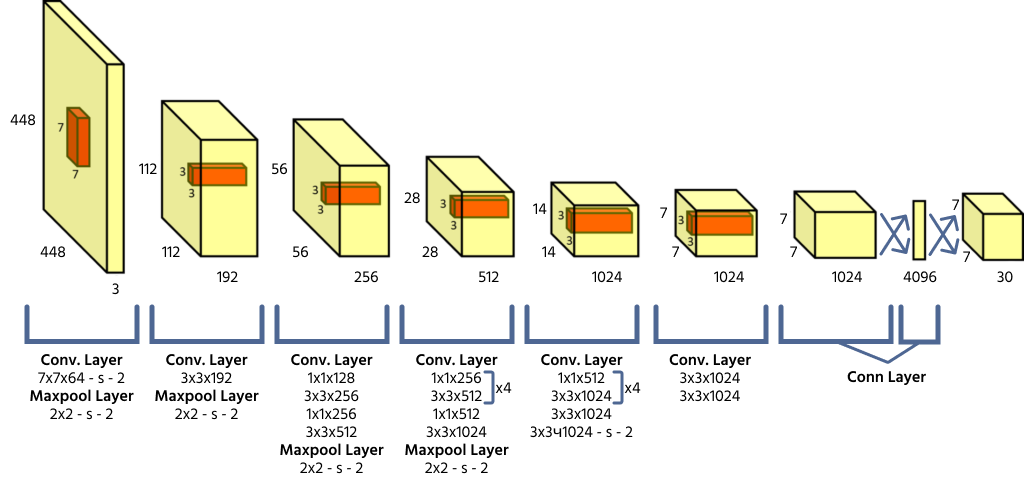
YOLO-arkkitehtuuri ja ruudukkoon perustuvat ennusteet
YOLO jakaa syötekuvan S × S -ruudukkoon, jossa jokainen ruutu vastaa niiden objektien tunnistamisesta, joiden keskipiste sijaitsee kyseisessä ruudussa. Jokainen ruutu ennustaa rajaavan laatikon koordinaatit (x, y, leveys, korkeus), objektin luottamuspisteen sekä luokkien todennäköisyydet. Koska YOLO käsittelee koko kuvan yhdellä eteenpäin suuntautuvalla laskennalla, se on erittäin tehokas verrattuna aiempiin objektintunnistusmalleihin.
Häviöfunktio ja luokkien luottamuspisteet
YOLO optimoi tunnistustarkkuutta mukautetulla häviöfunktiolla, joka sisältää:
- Lokalisointihäviö: mittaa rajaavan laatikon tarkkuutta;
- Luottamushäviö: varmistaa, että ennusteet osoittavat objektin läsnäolon oikein;
- Luokitteluhäviö: arvioi, kuinka hyvin ennustettu luokka vastaa todellista luokkaa.
Tulosten parantamiseksi YOLO käyttää ankkurilaatikoita ja non-max suppression (NMS) -menetelmää päällekkäisten tunnistusten poistamiseen.
YOLO:n edut: Nopeuden ja tarkkuuden tasapaino
YOLO:n merkittävin etu on nopeus. Koska tunnistus tapahtuu yhdellä läpikäynnillä, YOLO on huomattavasti nopeampi kuin R-CNN-pohjaiset menetelmät, mikä tekee siitä sopivan reaaliaikaisiin sovelluksiin, kuten autonomiseen ajamiseen ja valvontaan. Varhaiset YOLO-versiot olivat heikompia pienten objektien tunnistuksessa, mutta myöhemmät versiot ovat parantaneet tätä.
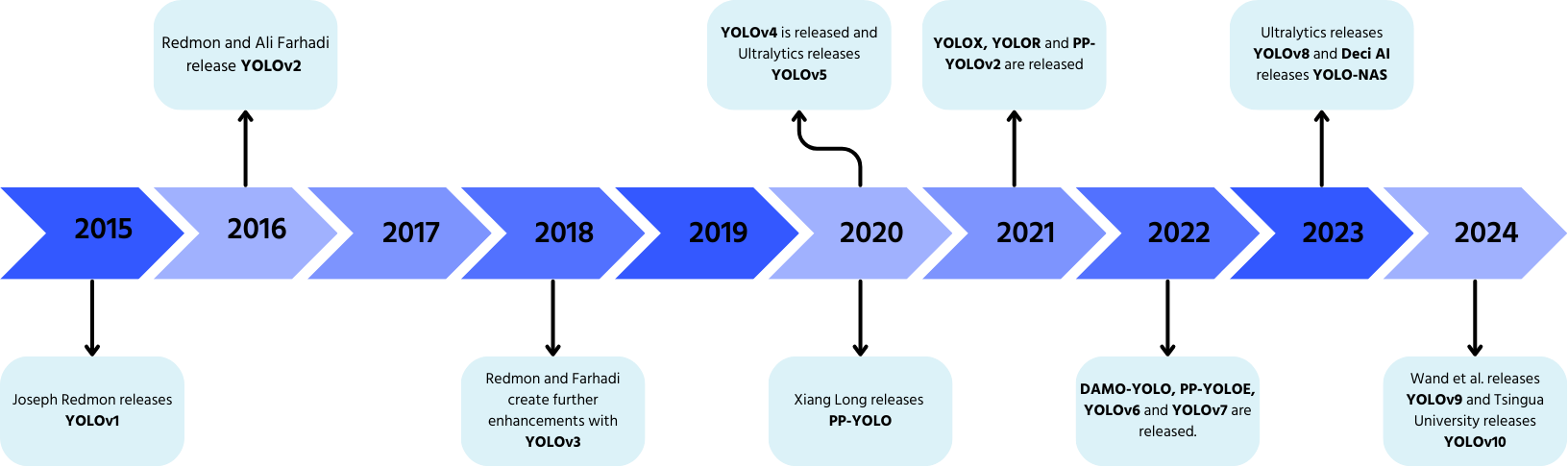
YOLO: Lyhyt historia
YOLO, jonka kehittivät Joseph Redmon ja Ali Farhadi vuonna 2015, mullisti objektien tunnistuksen yhden läpikäynnin prosessoinnilla.
- YOLOv2 (2016): lisäsi batch-normalisoinnin, ankkurilaatikot ja dimensio-klusterit;
- YOLOv3 (2018): esitteli tehokkaamman selkärangan, useita ankkureita ja spatiaalisen pyramidipoolauksen;
- YOLOv4 (2020): toi Mosaic-datan augmentoinnin, ankkurittoman tunnistuspään ja uuden tappiofunktion;
- YOLOv5: paransi suorituskykyä hyperparametrien optimoinnilla, kokeilujen seurannalla ja automaattisilla vientiominaisuuksilla;
- YOLOv6 (2022): Meituanin avoimeksi lähdekoodiksi julkaisema ja käytössä autonomisissa toimitusroboteissa;
- YOLOv7: laajensi ominaisuuksia kattamaan asentojen tunnistuksen;
- YOLOv8 (2023): paransi nopeutta, joustavuutta ja tehokkuutta visuaalisen tekoälyn tehtävissä;
- YOLOv9: esitteli ohjelmoitavan gradientti-informaation (PGI) ja yleistetyn tehokkaan kerrosten aggregointiverkon (GELAN);
- YOLOv10: Tsinghuan yliopiston kehittämä, poisti Non-Maximum Suppressionin (NMS) päätepisteestä päätepisteeseen -tunnistuspäällä;
- YOLOv11: uusin malli, joka tarjoaa huipputason suorituskykyä objektien tunnistuksessa, segmentoinnissa ja luokittelussa.
Kiitos palautteestasi!
Kysy tekoälyä
Kysy tekoälyä

Kysy mitä tahansa tai kokeile jotakin ehdotetuista kysymyksistä aloittaaksesi keskustelumme
