Rajauslaatikkoennusteet
Pyyhkäise näyttääksesi valikon
Rajat laatikot ovat keskeisiä objektien tunnistuksessa, tarjoten tavan merkitä objektien sijainnit. Objektien tunnistusmallit käyttävät näitä laatikoita määrittääkseen havaittujen objektien sijainnin ja mitat kuvassa. Rajalaatikoiden tarkka ennustaminen on olennaista luotettavan objektien tunnistuksen varmistamiseksi.
Kuinka CNN:t ennustavat rajalaatikoiden koordinaatit
Konvoluutioneuroverkot (CNN:t) käsittelevät kuvia konvoluutio- ja poolauskerrosten kautta piirteiden erottamiseksi. Objektien tunnistuksessa CNN:t tuottavat piirteiden karttoja, jotka kuvaavat kuvan eri osia. Rajalaatikoiden ennustaminen tapahtuu tyypillisesti seuraavasti:
- Piirre-edustusten erottaminen kuvasta;
- Regressiofunktion soveltaminen rajalaatikoiden koordinaattien ennustamiseen;
- Havaittujen objektien luokittelu jokaisessa laatikossa.
Rajalaatikoiden ennusteet esitetään numeerisina arvoina, jotka vastaavat:
- (x, y): laatikon keskikohdan koordinaatit;
- (w, h): laatikon leveys ja korkeus.
Esimerkki: Rajalaatikoiden ennustaminen valmiiksi koulutetulla mallilla
Sen sijaan, että koulutetaan CNN alusta alkaen, voidaan käyttää valmiiksi koulutettua mallia, kuten Faster R-CNN TensorFlow'n model zoo -kokoelmasta, ennustamaan rajalaatikot kuvasta. Alla on esimerkki valmiiksi koulutetun mallin lataamisesta, kuvan lataamisesta, ennusteiden tekemisestä ja rajalaatikoiden visualisoinnista luokkamerkintöjen kanssa.
Kirjastojen tuonti
import cv2
import tensorflow as tf
import tensorflow_hub as hub
import matplotlib.pyplot as plt
from tensorflow.image import draw_bounding_boxes
Mallin ja kuvan lataus
# Load a pretrained Faster R-CNN model from TensorFlow Hub
model = hub.load("https://www.kaggle.com/models/tensorflow/faster-rcnn-resnet-v1/TensorFlow2/faster-rcnn-resnet101-v1-1024x1024/1")
# Load and preprocess the image
img_path = "../../../Documents/Codefinity/CV/Pictures/Section 4/object_detection/bikes_n_persons.png"
img = cv2.imread(img_path)
Kuvan esikäsittely
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_resized = tf.image.resize(img, (1024, 1024))
# Convert to uint8
img_resized = tf.cast(img_resized, dtype=tf.uint8)
# Convert to tensor
img_tensor = tf.convert_to_tensor(img_resized)[tf.newaxis, ...]
Ennusteen tekeminen ja rajoituslaatikon ominaisuuksien poiminta
# Make predictions
output = model(img_tensor)
# Extract bounding box coordinates
num_detections = int(output['num_detections'][0])
bboxes = output['detection_boxes'][0][:num_detections].numpy()
class_names = output['detection_classes'][0][:num_detections].numpy().astype(int)
scores = output['detection_scores'][0][:num_detections].numpy()
# Example labels from COCO dataset
labels = {1: "Person", 2: "Bike"}
Rajoituslaatikoiden piirtäminen
# Draw bounding boxes with labels
for i in range(num_detections):
# Confidence threshold
if scores[i] > 0.5:
y1, x1, y2, x2 = bboxes[i]
start_point = (int(x1 * img.shape[1]), int(y1 * img.shape[0]))
end_point = (int(x2 * img.shape[1]), int(y2 * img.shape[0]))
cv2.rectangle(img, start_point, end_point, (0, 255, 0), 2)
# Get label or 'Unknown'
label = labels.get(class_names[i], "Unknown")
cv2.putText(img, f"{label} ({scores[i]:.2f})", (start_point[0], start_point[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), 2)
Visualisointi
# Display image with bounding boxes and labels
plt.figure()
plt.imshow(img)
plt.axis("off")
plt.title("Object Detection with Bounding Boxes and Labels")
plt.show()
Tulokset:

Regressiopohjaiset rajaavan laatikon ennusteet
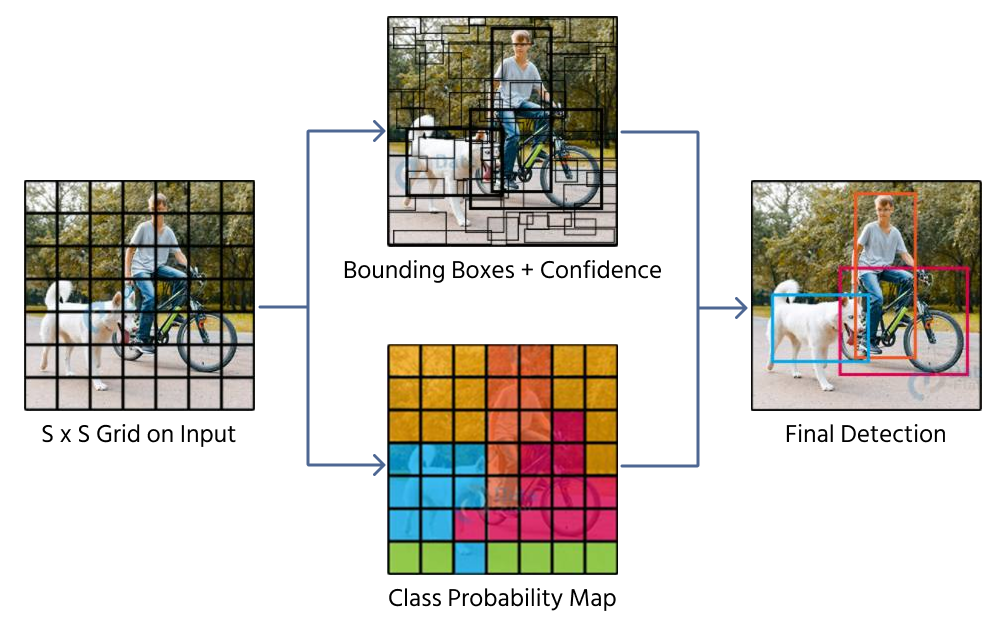
Yksi tapa ennustaa rajaavia laatikoita on suora regressio, jossa CNN tuottaa neljä numeerista arvoa, jotka kuvaavat laatikon sijaintia ja kokoa. Mallit kuten YOLO (You Only Look Once) käyttävät tätä tekniikkaa jakamalla kuvan ruudukkoon ja liittämällä rajaavan laatikon ennusteet ruutuihin.
Suoralla regressiolla on kuitenkin rajoituksia:
- Vaikeudet erikokoisten ja -muotoisten kohteiden kanssa;
- Ei käsittele päällekkäisiä kohteita tehokkaasti;
- Rajaavat laatikot voivat siirtyä arvaamattomasti, mikä johtaa epäjohdonmukaisuuksiin.
Ankkuripohjaiset vs. ankkurittomat lähestymistavat
Ankkuripohjaiset menetelmät
Ankkurilaatikot ovat ennalta määriteltyjä rajauslaatikoita, joilla on kiinteät koot ja kuvasuhteet. Mallit kuten Faster R-CNN ja SSD (Single Shot MultiBox Detector) käyttävät ankkurilaatikoita parantaakseen ennustetarkkuutta. Malli ennustaa säätöjä ankkurilaatikoihin sen sijaan, että se ennustaisi rajauslaatikot alusta alkaen. Tämä menetelmä soveltuu hyvin erikokoisten kohteiden tunnistamiseen, mutta lisää laskennallista monimutkaisuutta.
Ankkurittomat menetelmät
Ankkurittomat menetelmät, kuten CenterNet ja FCOS (Fully Convolutional One-Stage Object Detection), poistavat ennalta määritellyt ankkurilaatikot ja ennustavat sen sijaan kohteiden keskikohdat suoraan. Näiden menetelmien etuja ovat:
- Yksinkertaisemmat mallirakenteet;
- Nopeammat päättelyajat;
- Parempi yleistettävyys tuntemattomiin kohdekokoihin.

A (Ankkuriin perustuva): ennustaa siirtymät (vihreät viivat) ennalta määritellyistä ankkureista (sininen) vastaamaan todellista arvoa (punainen). B (Ankkuriton): arvioi suoraan siirtymät pisteestä sen rajoihin.
Rajatunnuksen ennustaminen on olennainen osa objektin tunnistusta, ja eri lähestymistavat tasapainottavat tarkkuutta ja tehokkuutta. Ankkuriin perustuvat menetelmät parantavat tarkkuutta käyttämällä ennalta määriteltyjä muotoja, kun taas ankkurittomat menetelmät yksinkertaistavat tunnistusta ennustamalla kohteen sijainnit suoraan. Näiden tekniikoiden ymmärtäminen auttaa suunnittelemaan parempia objektin tunnistusjärjestelmiä erilaisiin tosielämän sovelluksiin.
1. Mitä tietoja rajoittavan laatikon ennuste yleensä sisältää?
2. Mikä on ankkuripohjaisten menetelmien ensisijainen etu objektin tunnistuksessa?
3. Minkä haasteen suora regressio kohtaa rajoittavan laatikon ennustamisessa?
Kiitos palautteestasi!
Kysy tekoälyä
Kysy tekoälyä

Kysy mitä tahansa tai kokeile jotakin ehdotetuista kysymyksistä aloittaaksesi keskustelumme
