Réseaux Antagonistes Génératifs (GANs)
Glissez pour afficher le menu
Réseaux antagonistes génératifs (GANs), une catégorie de modèles génératifs introduite par Ian Goodfellow en 2014. Ils se composent de deux réseaux de neurones — le Générateur et le Discriminateur — entraînés simultanément dans un cadre de théorie des jeux. Le générateur tente de produire des données ressemblant aux données réelles, tandis que le discriminateur cherche à distinguer les données réelles des données générées.
Les GANs apprennent à générer des échantillons de données à partir de bruit en résolvant un jeu à somme nulle. Au fil de l'entraînement, le générateur s'améliore dans la production de données réalistes, et le discriminateur devient plus performant pour différencier les données réelles des données artificielles.
Architecture d'un GAN
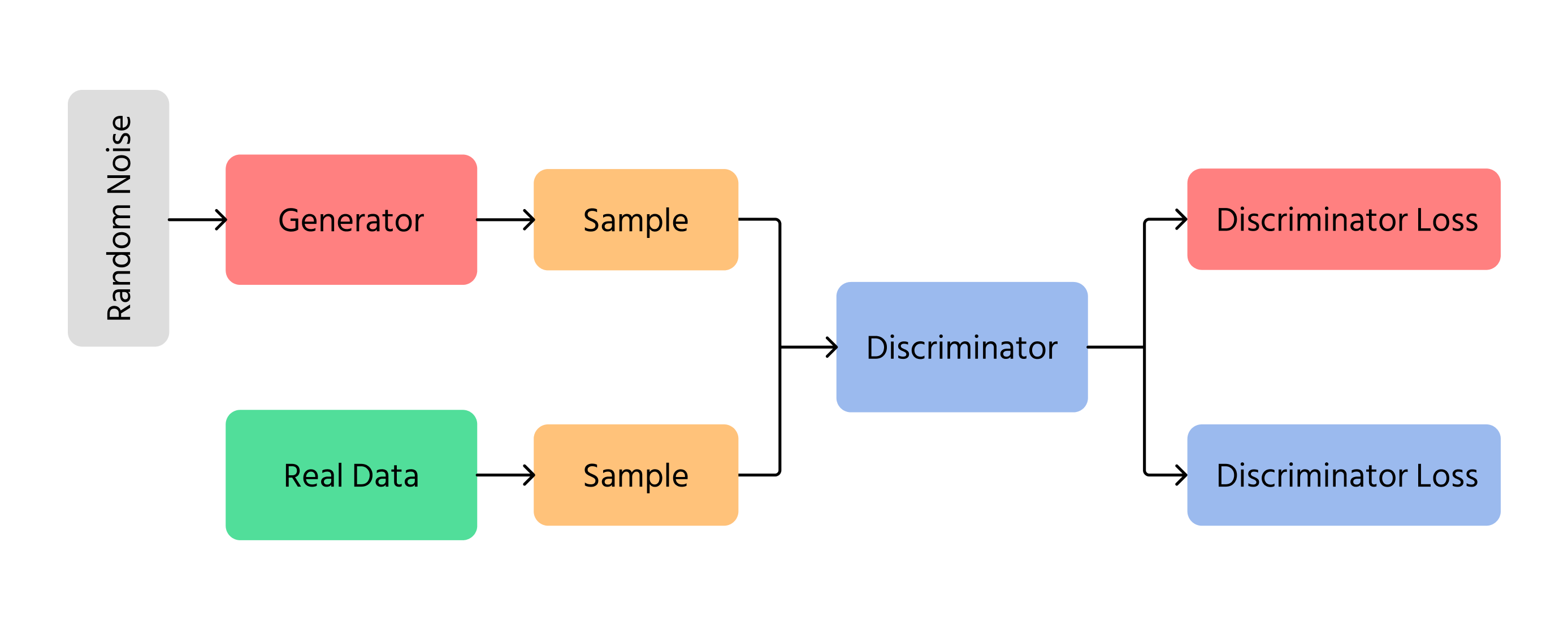
Un modèle GAN de base se compose de deux éléments principaux :
1. Générateur (G)
- Prend en entrée un vecteur de bruit aléatoire z∼pz(z) ;
- Le transforme via un réseau de neurones en un échantillon de données G(z) destiné à ressembler à des données issues de la distribution réelle.
2. Discriminateur (D)
- Prend en entrée soit un échantillon de données réelles x∼px(x), soit un échantillon généré G(z) ;
- Produit un scalaire compris entre 0 et 1, estimant la probabilité que l'entrée soit réelle.
Ces deux composants sont entraînés simultanément. Le générateur cherche à produire des échantillons réalistes pour tromper le discriminateur, tandis que le discriminateur vise à distinguer correctement les échantillons réels des échantillons générés.
Jeu minimax des GANs
Au cœur des GANs se trouve le jeu minimax, un concept issu de la théorie des jeux. Dans cette configuration :
- Le générateur G et le discriminateur D sont des joueurs en compétition ;
- D vise à maximiser sa capacité à distinguer les données réelles des données générées ;
- G vise à minimiser la capacité de D à détecter ses fausses données.
Cette dynamique définit un jeu à somme nulle, où le gain de l’un est la perte de l’autre. L’optimisation est définie comme suit :
GminDmaxV(D,G)=Ex∼px[logD(x)]+Ez∼pz[log(1−D(G(z)))]Le générateur tente de tromper le discriminateur en générant des échantillons G(z) aussi proches que possible des données réelles.
Fonctions de perte
Bien que l’objectif initial des GANs définisse un jeu minimax, en pratique, des fonctions de perte alternatives sont utilisées pour stabiliser l’entraînement.
- Perte non saturante du générateur :
Cela aide le générateur à recevoir des gradients forts même lorsque le discriminateur fonctionne bien.
- Perte du discriminateur :
Ces fonctions de perte encouragent le générateur à produire des échantillons qui augmentent l’incertitude du discriminateur et améliorent la convergence pendant l’entraînement.
Principales variantes des architectures GAN
Plusieurs types de GANs ont émergé pour répondre à des limitations spécifiques ou pour améliorer les performances :

GAN conditionnel (cGAN)
Les GANs conditionnels étendent le cadre standard des GANs en introduisant des informations supplémentaires (généralement des étiquettes) à la fois dans le générateur et le discriminateur. Au lieu de générer des données uniquement à partir d'un bruit aléatoire, le générateur reçoit à la fois un bruit z et une condition y (par exemple, une étiquette de classe). Le discriminateur reçoit également y pour juger si l'échantillon est réaliste sous cette condition.
- Cas d'utilisation : génération d'images conditionnées par classe, traduction d'image à image, génération de texte en image.
GAN convolutionnel profond (DCGAN)
Les DCGANs remplacent les couches entièrement connectées des GANs originaux par des couches convolutionnelles et des couches convolutionnelles transposées, ce qui les rend plus efficaces pour la génération d'images. Ils introduisent également des recommandations architecturales telles que la suppression des couches entièrement connectées, l'utilisation de la normalisation par lot et l'emploi des activations ReLU/LeakyReLU.
- Cas d'utilisation : génération d'images photo-réalistes, apprentissage de représentations visuelles, apprentissage non supervisé de caractéristiques.
CycleGAN Les CycleGANs répondent au problème de la traduction d’images non appariées. Contrairement à d’autres modèles nécessitant des ensembles de données appariées (par exemple, la même photo dans deux styles différents), les CycleGANs peuvent apprendre des correspondances entre deux domaines sans exemples appariés. Ils introduisent deux générateurs et deux discriminateurs, chacun responsable de la conversion dans une direction (par exemple, photos vers peintures et inversement), et imposent une perte de cohérence cyclique pour garantir que la traduction d’un domaine à l’autre puis retour restitue l’image d’origine. Cette perte est essentielle pour préserver le contenu et la structure.
La perte de cohérence cyclique garantit :
GBA(GAB(x))≈x et GAB(GBA(y))≈yoù :
- GAB mappe les images du domaine A vers le domaine B ;
- GBA mappe du domaine B vers le domaine A.
- x∈A,y∈B.
Cas d’utilisation : conversion de photo en œuvre d’art, traduction cheval-zèbre, conversion de voix entre locuteurs.
StyleGAN
StyleGAN, développé par NVIDIA, introduit un contrôle basé sur le style dans le générateur. Au lieu d’alimenter directement le générateur avec un vecteur de bruit, celui-ci passe par un réseau de mappage pour produire des « vecteurs de style » qui influencent chaque couche du générateur. Cela permet un contrôle précis sur des caractéristiques visuelles telles que la couleur des cheveux, les expressions faciales ou l’éclairage.
Innovations notables :
- Mélange de styles, permet de combiner plusieurs codes latents ;
- Normalisation d’instance adaptative (AdaIN), contrôle les cartes de caractéristiques dans le générateur ;
- Croissance progressive, l’entraînement commence en basse résolution et augmente progressivement.
Cas d’utilisation : génération d’images ultra haute résolution (par exemple, visages), contrôle d’attributs visuels, génération artistique.
Comparaison : GANs vs VAEs
Les GANs constituent une classe puissante de modèles génératifs capables de produire des données hautement réalistes grâce à un processus d'entraînement adversarial. Leur principe repose sur un jeu minimax entre deux réseaux, utilisant des pertes adversariales pour améliorer itérativement les deux composants. Une compréhension solide de leur architecture, de leurs fonctions de perte—y compris les variantes telles que cGAN, DCGAN, CycleGAN et StyleGAN—et de leur contraste avec d'autres modèles comme les VAE offre aux praticiens les bases nécessaires pour des applications dans des domaines tels que la génération d'images, la synthèse vidéo, l'augmentation de données, et bien plus encore.
1. Laquelle des propositions suivantes décrit le mieux les composants d'une architecture GAN de base ?
2. Quel est l'objectif du jeu minimax dans les GANs ?
3. Laquelle des affirmations suivantes est vraie concernant la différence entre les GANs et les VAEs ?
Merci pour vos commentaires !
Demandez à l'IA
Demandez à l'IA

Posez n'importe quelle question ou essayez l'une des questions suggérées pour commencer notre discussion
Réseaux Antagonistes Génératifs (GANs)
Réseaux antagonistes génératifs (GANs), une catégorie de modèles génératifs introduite par Ian Goodfellow en 2014. Ils se composent de deux réseaux de neurones — le Générateur et le Discriminateur — entraînés simultanément dans un cadre de théorie des jeux. Le générateur tente de produire des données ressemblant aux données réelles, tandis que le discriminateur cherche à distinguer les données réelles des données générées.
Les GANs apprennent à générer des échantillons de données à partir de bruit en résolvant un jeu à somme nulle. Au fil de l'entraînement, le générateur s'améliore dans la production de données réalistes, et le discriminateur devient plus performant pour différencier les données réelles des données artificielles.
Architecture d'un GAN
Un modèle GAN de base se compose de deux éléments principaux :
1. Générateur (G)
- Prend en entrée un vecteur de bruit aléatoire z∼pz(z) ;
- Le transforme via un réseau de neurones en un échantillon de données G(z) destiné à ressembler à des données issues de la distribution réelle.
2. Discriminateur (D)
- Prend en entrée soit un échantillon de données réelles x∼px(x), soit un échantillon généré G(z) ;
- Produit un scalaire compris entre 0 et 1, estimant la probabilité que l'entrée soit réelle.
Ces deux composants sont entraînés simultanément. Le générateur cherche à produire des échantillons réalistes pour tromper le discriminateur, tandis que le discriminateur vise à distinguer correctement les échantillons réels des échantillons générés.
Jeu minimax des GANs
Au cœur des GANs se trouve le jeu minimax, un concept issu de la théorie des jeux. Dans cette configuration :
- Le générateur G et le discriminateur D sont des joueurs en compétition ;
- D vise à maximiser sa capacité à distinguer les données réelles des données générées ;
- G vise à minimiser la capacité de D à détecter ses fausses données.
Cette dynamique définit un jeu à somme nulle, où le gain de l’un est la perte de l’autre. L’optimisation est définie comme suit :
GminDmaxV(D,G)=Ex∼px[logD(x)]+Ez∼pz[log(1−D(G(z)))]Le générateur tente de tromper le discriminateur en générant des échantillons G(z) aussi proches que possible des données réelles.
Fonctions de perte
Bien que l’objectif initial des GANs définisse un jeu minimax, en pratique, des fonctions de perte alternatives sont utilisées pour stabiliser l’entraînement.
- Perte non saturante du générateur :
Cela aide le générateur à recevoir des gradients forts même lorsque le discriminateur fonctionne bien.
- Perte du discriminateur :
Ces fonctions de perte encouragent le générateur à produire des échantillons qui augmentent l’incertitude du discriminateur et améliorent la convergence pendant l’entraînement.
Principales variantes des architectures GAN
Plusieurs types de GANs ont émergé pour répondre à des limitations spécifiques ou pour améliorer les performances :
GAN conditionnel (cGAN)
Les GANs conditionnels étendent le cadre standard des GANs en introduisant des informations supplémentaires (généralement des étiquettes) à la fois dans le générateur et le discriminateur. Au lieu de générer des données uniquement à partir d'un bruit aléatoire, le générateur reçoit à la fois un bruit z et une condition y (par exemple, une étiquette de classe). Le discriminateur reçoit également y pour juger si l'échantillon est réaliste sous cette condition.
- Cas d'utilisation : génération d'images conditionnées par classe, traduction d'image à image, génération de texte en image.
GAN convolutionnel profond (DCGAN)
Les DCGANs remplacent les couches entièrement connectées des GANs originaux par des couches convolutionnelles et des couches convolutionnelles transposées, ce qui les rend plus efficaces pour la génération d'images. Ils introduisent également des recommandations architecturales telles que la suppression des couches entièrement connectées, l'utilisation de la normalisation par lot et l'emploi des activations ReLU/LeakyReLU.
- Cas d'utilisation : génération d'images photo-réalistes, apprentissage de représentations visuelles, apprentissage non supervisé de caractéristiques.
CycleGAN Les CycleGANs répondent au problème de la traduction d’images non appariées. Contrairement à d’autres modèles nécessitant des ensembles de données appariées (par exemple, la même photo dans deux styles différents), les CycleGANs peuvent apprendre des correspondances entre deux domaines sans exemples appariés. Ils introduisent deux générateurs et deux discriminateurs, chacun responsable de la conversion dans une direction (par exemple, photos vers peintures et inversement), et imposent une perte de cohérence cyclique pour garantir que la traduction d’un domaine à l’autre puis retour restitue l’image d’origine. Cette perte est essentielle pour préserver le contenu et la structure.
La perte de cohérence cyclique garantit :
GBA(GAB(x))≈x et GAB(GBA(y))≈yoù :
- GAB mappe les images du domaine A vers le domaine B ;
- GBA mappe du domaine B vers le domaine A.
- x∈A,y∈B.
Cas d’utilisation : conversion de photo en œuvre d’art, traduction cheval-zèbre, conversion de voix entre locuteurs.
StyleGAN
StyleGAN, développé par NVIDIA, introduit un contrôle basé sur le style dans le générateur. Au lieu d’alimenter directement le générateur avec un vecteur de bruit, celui-ci passe par un réseau de mappage pour produire des « vecteurs de style » qui influencent chaque couche du générateur. Cela permet un contrôle précis sur des caractéristiques visuelles telles que la couleur des cheveux, les expressions faciales ou l’éclairage.
Innovations notables :
- Mélange de styles, permet de combiner plusieurs codes latents ;
- Normalisation d’instance adaptative (AdaIN), contrôle les cartes de caractéristiques dans le générateur ;
- Croissance progressive, l’entraînement commence en basse résolution et augmente progressivement.
Cas d’utilisation : génération d’images ultra haute résolution (par exemple, visages), contrôle d’attributs visuels, génération artistique.
Comparaison : GANs vs VAEs
Les GANs constituent une classe puissante de modèles génératifs capables de produire des données hautement réalistes grâce à un processus d'entraînement adversarial. Leur principe repose sur un jeu minimax entre deux réseaux, utilisant des pertes adversariales pour améliorer itérativement les deux composants. Une compréhension solide de leur architecture, de leurs fonctions de perte—y compris les variantes telles que cGAN, DCGAN, CycleGAN et StyleGAN—et de leur contraste avec d'autres modèles comme les VAE offre aux praticiens les bases nécessaires pour des applications dans des domaines tels que la génération d'images, la synthèse vidéo, l'augmentation de données, et bien plus encore.
Merci pour vos commentaires !
