Modèles de Diffusion et Approches Génératives Probabilistes
Glissez pour afficher le menu
Compréhension de la génération basée sur la diffusion
Les modèles de diffusion sont un type puissant de modèle d'IA qui génèrent des données – en particulier des images – en apprenant à inverser un processus d'ajout de bruit aléatoire. Imaginez regarder une image nette devenir progressivement floue, comme des parasites sur une télévision. Un modèle de diffusion apprend à faire l'inverse : il prend des images bruitées et reconstruit l'image d'origine en supprimant le bruit étape par étape.
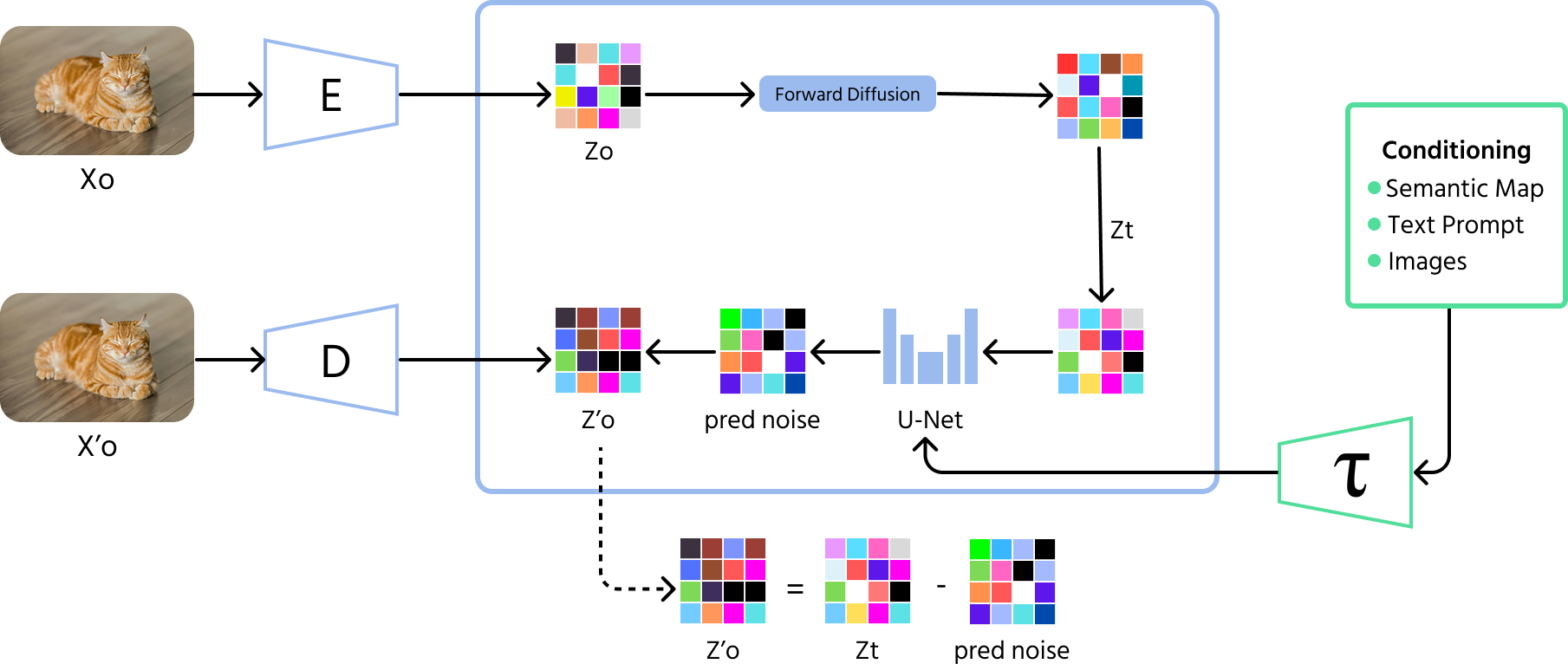
Le processus implique deux phases principales :
- Processus direct (diffusion) : ajoute progressivement du bruit aléatoire à une image sur de nombreuses étapes, la corrompant jusqu'à obtenir un bruit pur ;
- Processus inverse (dénoyautage) : un réseau de neurones apprend à supprimer le bruit étape par étape, reconstruisant l'image d'origine à partir de la version bruitée.
Les modèles de diffusion sont reconnus pour leur capacité à produire des images de haute qualité et réalistes. Leur entraînement est généralement plus stable que celui des modèles comme les GAN, ce qui les rend très attractifs dans l'IA générative moderne.
Modèles probabilistes de diffusion pour la suppression du bruit (DDPM)
Les modèles probabilistes de diffusion pour la suppression du bruit (DDPM) sont un type populaire de modèle de diffusion qui appliquent des principes probabilistes et l'apprentissage profond pour éliminer le bruit des images de manière progressive.
Processus direct
Dans le processus direct, on commence avec une image réelle x0 et on ajoute progressivement du bruit gaussien sur T étapes temporelles :
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)Où :
- xt : version bruitée de l'entrée à l'étape temporelle ;
- βt : planification de faible variance contrôlant la quantité de bruit ajoutée ;
- N : distribution gaussienne.
On peut également exprimer le bruit total ajouté jusqu'à l'étape comme :
q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I)Où :
- αˉt=∏s=1t(1−βs)
Processus inverse
L'objectif du modèle est d'apprendre l'inverse de ce processus. Un réseau de neurones paramétré par θ prédit la moyenne et la variance de la distribution débruitée :
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),Σθ(xt,t))où :
- xt : image bruitée à l'étape temporelle t ;
- xt−1 : image prédite moins bruitée à l'étape t−1 ;
- μθ : moyenne prédite par le réseau de neurones ;
- Σθ : variance prédite par le réseau de neurones.
Fonction de perte
L'entraînement consiste à minimiser la différence entre le bruit réel et le bruit prédit par le modèle à l'aide de l'objectif suivant :
Lsimple=Ex0,ϵ,t[∣∣ϵ−ϵ0(αˉtx0+1−αˉtϵ,t)∣∣2]où :
- xt : image d'entrée originale ;
- ϵ : bruit gaussien aléatoire ;
- t : étape temporelle pendant la diffusion ;
- ϵθ : prédiction du bruit par le réseau de neurones ;
- αˉt : produit des paramètres du planning de bruit jusqu'à l'étape t.
Cela aide le modèle à mieux débruiter, améliorant ainsi sa capacité à générer des données réalistes.
Modélisation Générative Basée sur le Score
Les modèles basés sur le score constituent une autre catégorie de modèles de diffusion. Au lieu d'apprendre directement le processus inverse du bruit, ils apprennent la fonction score :
∇xlogp(x)où :
- ∇xlogp(x) : le gradient de la densité de log-probabilité par rapport à l'entrée x. Cela indique la direction d'augmentation de la vraisemblance selon la distribution des données ;
- p(x) : la distribution de probabilité des données.
Cette fonction indique au modèle dans quelle direction l'image doit évoluer pour ressembler davantage à des données réelles. Ces modèles utilisent ensuite une méthode d'échantillonnage telle que la dynamique de Langevin pour déplacer progressivement les données bruitées vers des régions de données à forte probabilité.
Les modèles basés sur le score fonctionnent souvent en temps continu à l'aide d'équations différentielles stochastiques (EDS). Cette approche continue offre de la flexibilité et permet de générer des échantillons de haute qualité sur divers types de données.
Applications à la Génération d’Images Haute Résolution
Les modèles de diffusion ont révolutionné les tâches génératives, en particulier dans la génération visuelle haute résolution. Parmi les applications notables :
- Stable Diffusion : un modèle de diffusion latente qui génère des images à partir de descriptions textuelles. Il combine un modèle de débruitage basé sur U-Net avec un autoencodeur variationnel (VAE) pour opérer dans l’espace latent ;
- DALL·E 2 : combine des embeddings CLIP et un décodage basé sur la diffusion pour générer des images très réalistes et sémantiques à partir de texte ;
- MidJourney : une plateforme de génération d’images basée sur la diffusion, reconnue pour produire des visuels de haute qualité au style artistique à partir de requêtes abstraites ou créatives.
Ces modèles sont utilisés pour la génération artistique, la synthèse photoréaliste, l’inpainting, la super-résolution, et bien plus encore.
Résumé
Les modèles de diffusion définissent une nouvelle ère de la modélisation générative en traitant la génération de données comme un processus stochastique inversé dans le temps. Grâce aux DDPM et aux modèles basés sur le score, ils permettent un entraînement robuste, une haute qualité d’échantillons et des résultats convaincants sur diverses modalités. Leur fondement dans les principes probabilistes et thermodynamiques les rend à la fois élégants sur le plan mathématique et puissants en pratique.
1. Quelle est l'idée principale des modèles génératifs basés sur la diffusion ?
2. Qu'utilise le processus direct des DDPM pour ajouter du bruit à chaque étape ?
3. Laquelle des propositions suivantes décrit le mieux le rôle de la fonction score ∇xlogp(x) dans la modélisation générative basée sur le score ?
Merci pour vos commentaires !
Demandez à l'IA
Demandez à l'IA

Posez n'importe quelle question ou essayez l'une des questions suggérées pour commencer notre discussion
