single
Graphique KDE
Glissez pour afficher le menu
Un graphique d'estimation de densité par noyau (KDE) est un type de graphique qui visualise la fonction de densité de probabilité estimée d'une variable continue. Contrairement à un histogramme, qui affiche les données à l'aide de barres discrètes regroupées en intervalles, un graphique KDE représente la distribution sous la forme d'une courbe lisse et continue basée sur l'ensemble des points de données.
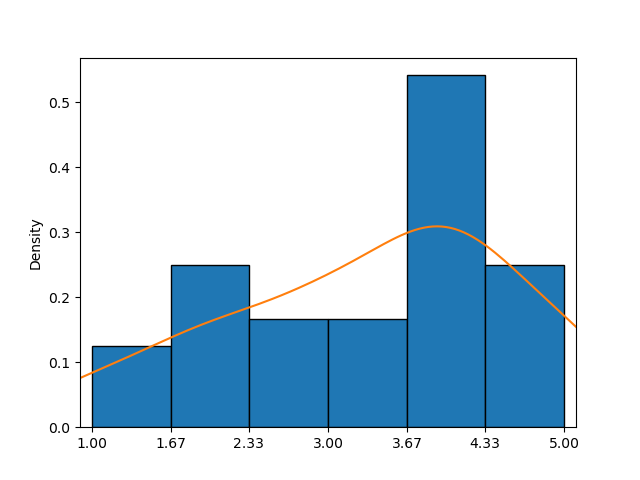
Cet exemple montre un histogramme combiné à un graphique KDE (courbe orange), offrant une approximation plus claire de la fonction de densité de probabilité que l'histogramme seul.
Dans seaborn, la fonction kdeplot() permet de créer facilement des graphiques KDE. Ses paramètres principaux—data, x et y—fonctionnent de la même manière que dans countplot().
Première option
Un seul des paramètres peut être défini en passant une séquence de valeurs, permettant une personnalisation individuelle pour chaque élément.
123456789101112import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # Loading the dataset with the average yearly temperatures in Boston and Seattle url = 'https://content-media-cdn.codefinity.com/courses/47339f29-4722-4e72-a0d4-6112c70ff738/weather_data.csv' weather_df = pd.read_csv(url, index_col=0) # Creating a KDE plot setting only the data parameter sns.kdeplot(data=weather_df['Seattle'], fill=True) plt.show()
Le paramètre data est défini en passant un objet Series, et le paramètre fill est utilisé pour remplir la zone sous la courbe, qui n'est pas remplie par défaut.
Deuxième option
Il est également possible de définir un objet 2D tel qu'un DataFrame pour data et un nom de colonne ou une clé si data est un dictionnaire pour x (orientation verticale) ou y (orientation horizontale) :
123456789101112import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # Loading the dataset with the average yearly temperatures in Boston and Seattle url = 'https://content-media-cdn.codefinity.com/courses/47339f29-4722-4e72-a0d4-6112c70ff738/weather_data.csv' weather_df = pd.read_csv(url, index_col=0) # Creating a KDE plot setting both the data and x parameters sns.kdeplot(data=weather_df, x='Seattle', fill=True) plt.show()
Les mêmes résultats ont été obtenus en passant l'intégralité du DataFrame comme paramètre data et en spécifiant le nom de la colonne pour le paramètre x.
Le graphique KDE créé présente une courbe en cloche caractéristique, ressemblant fortement à une distribution normale avec une moyenne autour de 52°F.
Si vous souhaitez approfondir la fonction KDE plot, n'hésitez pas à consulter la documentation de kdeplot().
Glissez pour commencer à coder
- Utiliser la fonction appropriée pour créer un graphique KDE.
- Utiliser
countries_dfcomme source de données pour le graphique (premier argument). - Définir
'GDP per capita'comme colonne à utiliser et l’orientation sur horizontale via le second argument. - Remplir la zone sous la courbe via le troisième (dernier) argument.
Solution
Merci pour vos commentaires !
single
Demandez à l'IA
Demandez à l'IA

Posez n'importe quelle question ou essayez l'une des questions suggérées pour commencer notre discussion
