single
Graphe de Paires
Glissez pour afficher le menu
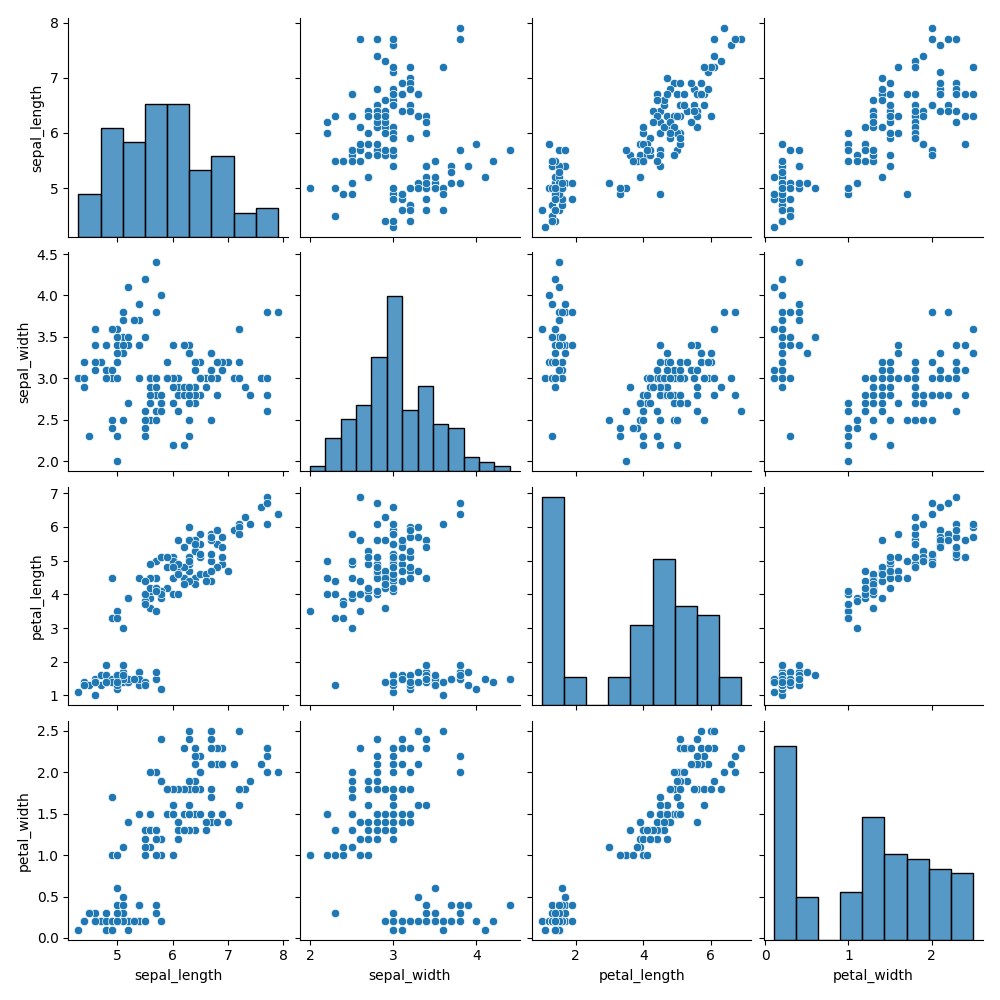
Un pair plot visualise les relations par paires entre toutes les variables numériques d’un jeu de données. Contrairement à un joint plot, il n’est pas limité à deux variables. Il crée une grille de sous-graphes de taille N×N, où N correspond au nombre de colonnes numériques dans le DataFrame.
Description du Pair Plot
Chaque colonne de la grille partage la même variable pour l’axe des x, et chaque ligne partage la même variable pour l’axe des y. La diagonale affiche les histogrammes des variables individuelles, tandis que les cellules hors diagonale présentent des nuages de points.
Création d’un Pair Plot
Vous pouvez en créer un avec seaborn.pairplot(). Son seul argument obligatoire est data, qui doit être un DataFrame. Les paramètres comme height et aspect définissent la taille (en pouces) de chaque sous-graphe.
12345678910import seaborn as sns import matplotlib.pyplot as plt # Loading the dataset with data about three different iris species iris_df = sns.load_dataset('iris') # Creating a pair plot sns.pairplot(iris_df, height=2, aspect=0.8) plt.show()
Hue
Le paramètre hue attribue des couleurs en fonction d’une colonne catégorielle spécifiée. Cela met en évidence les différences entre groupes et, dans les jeux de données de classification, montre comment les classes se séparent selon les paires de variables.
Lorsque hue est défini (par exemple sur species), les nuages de points colorient les points par classe, et les graphiques diagonaux passent des histogrammes aux KDE plots, rendant les distributions des classes plus claires.
1234567891011121314import seaborn as sns import matplotlib.pyplot as plt # Ignoring warnings import warnings warnings.filterwarnings('ignore') # Loading the dataset with data about three different iris species iris_df = sns.load_dataset('iris') # Setting the hue parameter to 'species' sns.pairplot(iris_df, hue='species', height=2, aspect=0.8) plt.show()
Modification des types de graphiques
Personnalisation possible des graphiques principaux et diagonaux.
kindcontrôle les graphiques hors diagonale (par défaut :'scatter') ;diag_kindcontrôle la diagonale (histogramme ou KDE, souvent choisi automatiquement lorsquehueest utilisé).
12345678910import seaborn as sns import matplotlib.pyplot as plt # Loading the dataset with data about three different iris species iris_df = sns.load_dataset('iris') # Setting the kind parameter and diag_kind parameters sns.pairplot(iris_df, hue='species', kind='reg', diag_kind=None, height=2, aspect=0.8) plt.show()
'scatter', 'kde', 'hist', 'reg' sont des valeurs possibles pour le paramètre kind.
diag_kind peut être défini sur l'une des valeurs suivantes :
'auto';'hist';'kde';None.
Tout cela est similaire à la fonction jointplot() à cet égard.
Explorez davantage dans la documentation de pairplot().
Glissez pour commencer à coder
- Utiliser la fonction appropriée pour créer un pair plot.
- Définir les données du graphique sur
penguins_dfvia le premier argument. - Définir
'sex'comme colonne pour mapper les aspects du graphique à différentes couleurs en spécifiant le deuxième argument. - Définir les graphiques non diagonaux pour afficher une ligne de régression (
'reg') en spécifiant le troisième argument. - Définir
heightà2. - Définir
aspectà0.8.
Solution
Merci pour vos commentaires !
single
Demandez à l'IA
Demandez à l'IA

Posez n'importe quelle question ou essayez l'une des questions suggérées pour commencer notre discussion
