single
Implémentation de Réseau de Neurones
Glissez pour afficher le menu
Vue d'ensemble d'un réseau de neurones de base
Vous avez désormais atteint un niveau où vous possédez les connaissances essentielles de TensorFlow pour créer des réseaux de neurones par vous-même. Bien que la plupart des réseaux de neurones utilisés en pratique soient complexes et généralement construits à l'aide de bibliothèques de haut niveau comme Keras, nous allons en construire un basique en utilisant les outils fondamentaux de TensorFlow. Cette méthode offre une expérience pratique de la manipulation de tenseurs à bas niveau, ce qui aide à comprendre les processus sous-jacents.
Dans des cours précédents comme Introduction to Neural Networks, vous vous souvenez peut-être du temps et des efforts nécessaires pour construire même un simple réseau de neurones, en traitant chaque neurone individuellement.

TensorFlow simplifie considérablement ce processus. En exploitant les tenseurs, il est possible d'encapsuler des calculs complexes, ce qui réduit la nécessité d'une programmation complexe. La tâche principale consiste à mettre en place un pipeline séquentiel d'opérations sur les tenseurs.
Voici un bref rappel des étapes pour lancer le processus d'entraînement d'un réseau de neurones :
Préparation des données et création du modèle
La phase initiale de l'entraînement d'un réseau de neurones consiste à préparer les données, englobant à la fois les entrées et les sorties à partir desquelles le réseau va apprendre. De plus, les hyperparamètres du modèle sont définis : ce sont les paramètres qui restent constants tout au long du processus d'entraînement. Les poids sont initialisés, généralement à partir d'une distribution normale, et les biais, qui sont souvent initialisés à zéro.
Propagation avant
Lors de la propagation avant, chaque couche du réseau suit généralement les étapes suivantes :
- Multiplier l'entrée de la couche par ses poids.
- Ajouter un biais au résultat.
- Appliquer une fonction d'activation à cette somme.
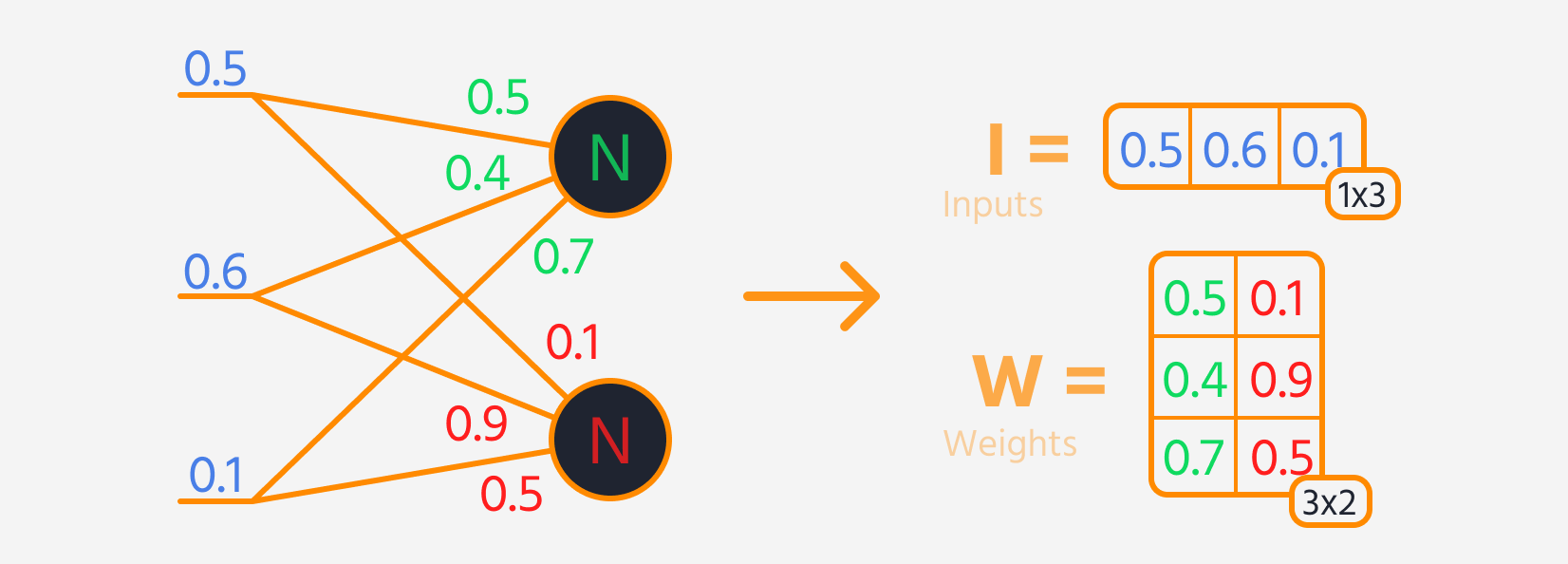
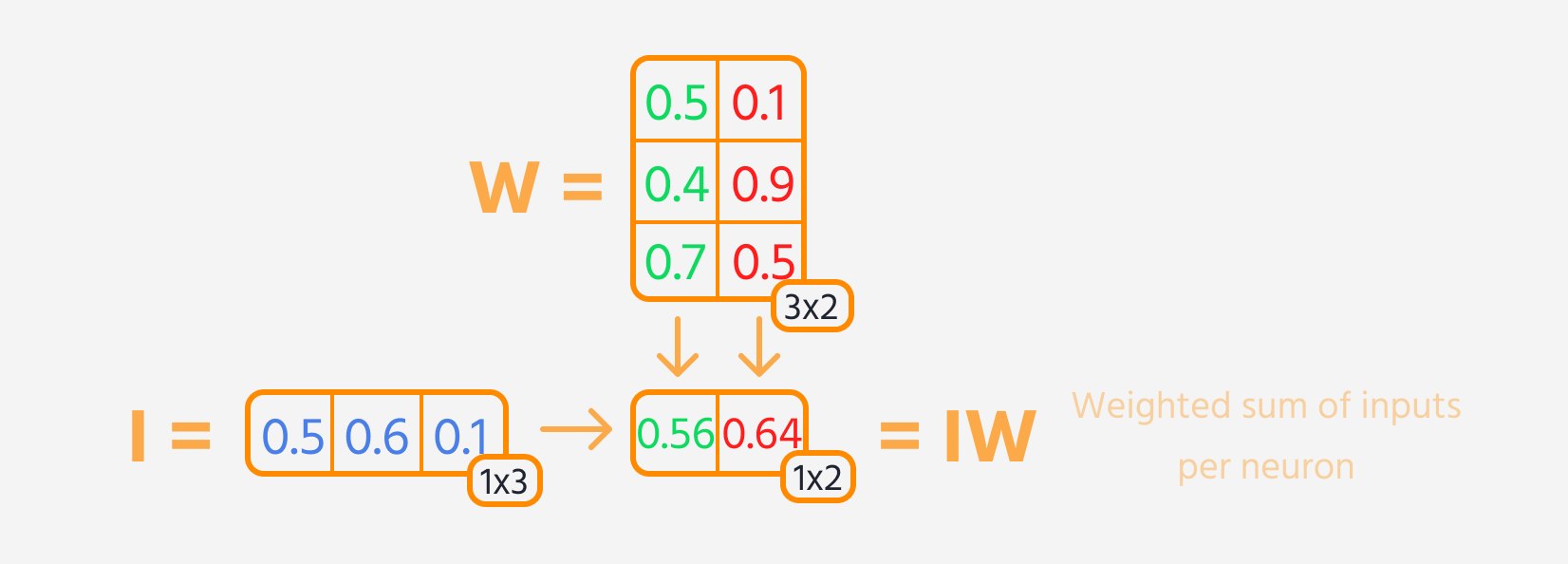
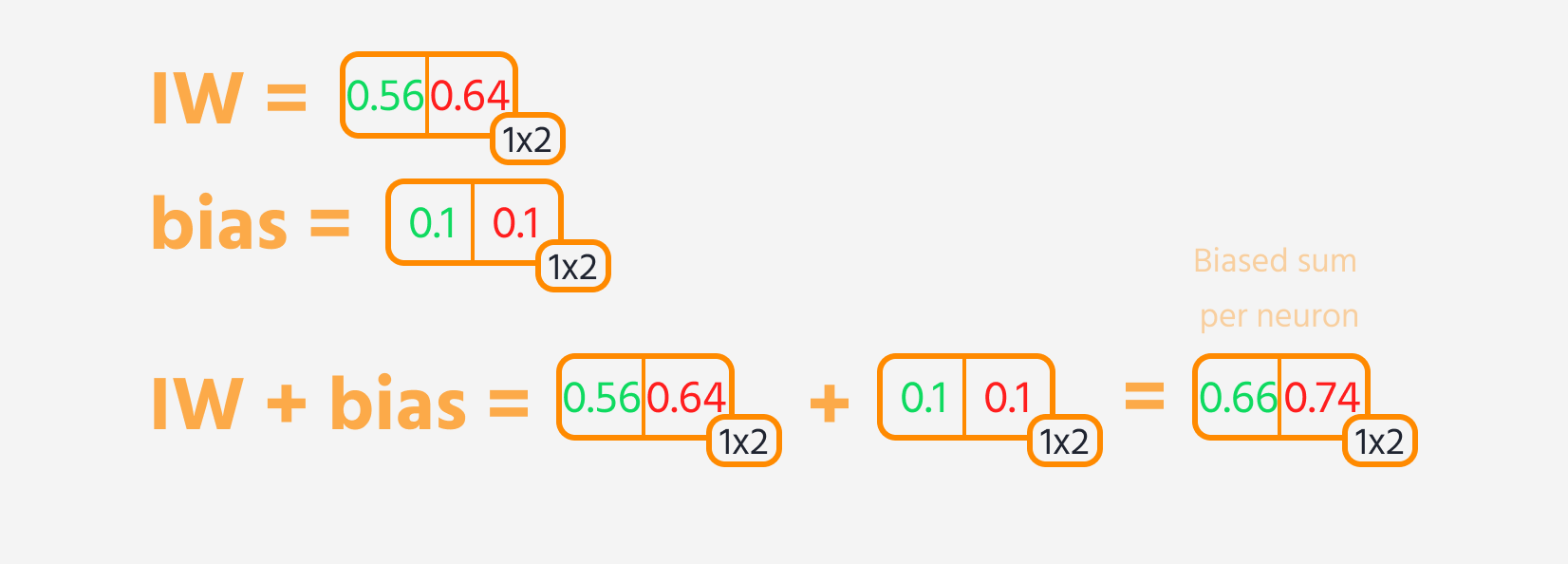


Ensuite, la perte peut être calculée.
Rétropropagation
L'étape suivante est la rétropropagation, où l'on ajuste les poids et les biais en fonction de leur influence sur la perte. Cette influence est représentée par le gradient, que le Gradient Tape de TensorFlow calcule automatiquement. Les poids et les biais sont mis à jour en soustrayant le gradient, pondéré par le taux d'apprentissage.
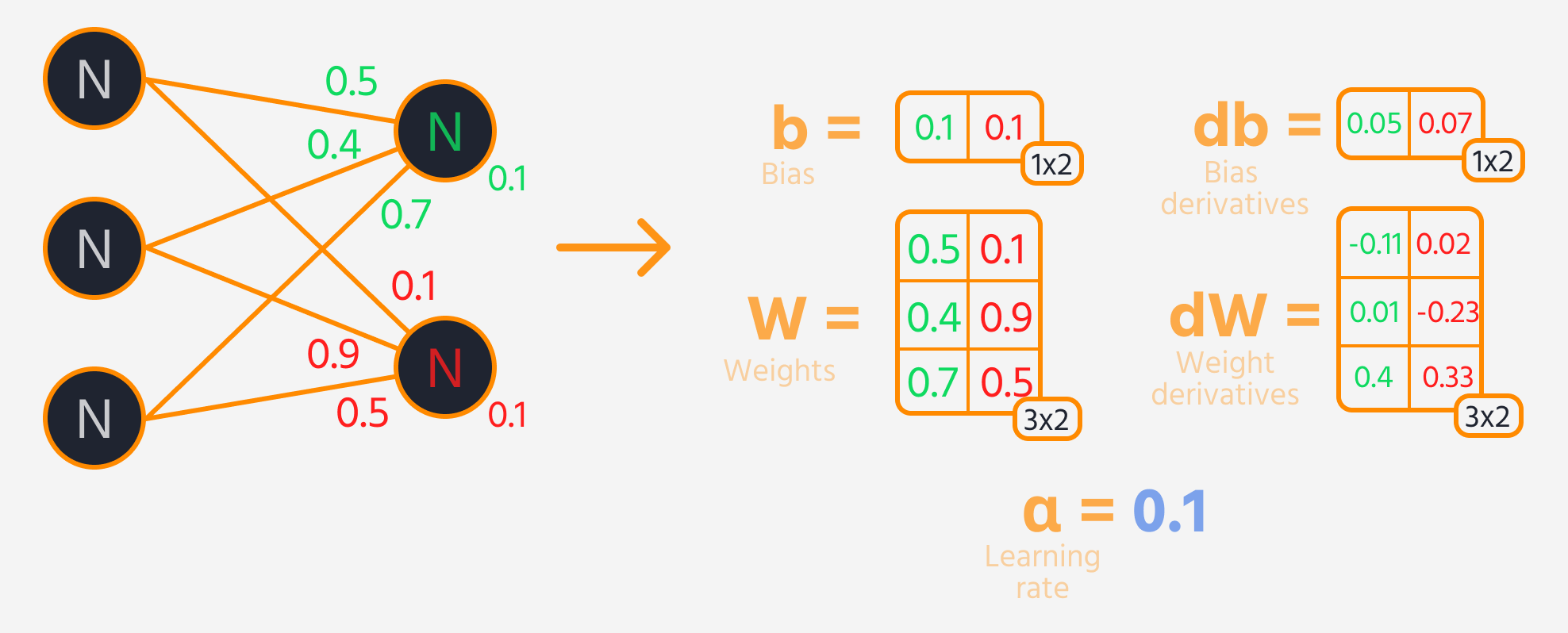
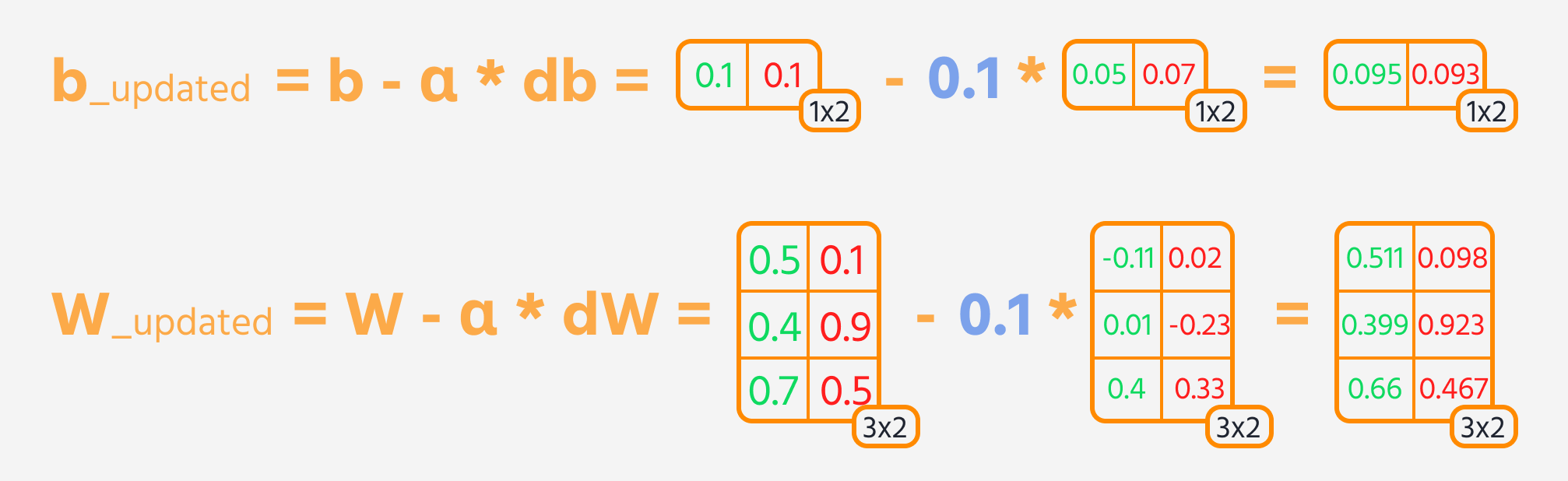
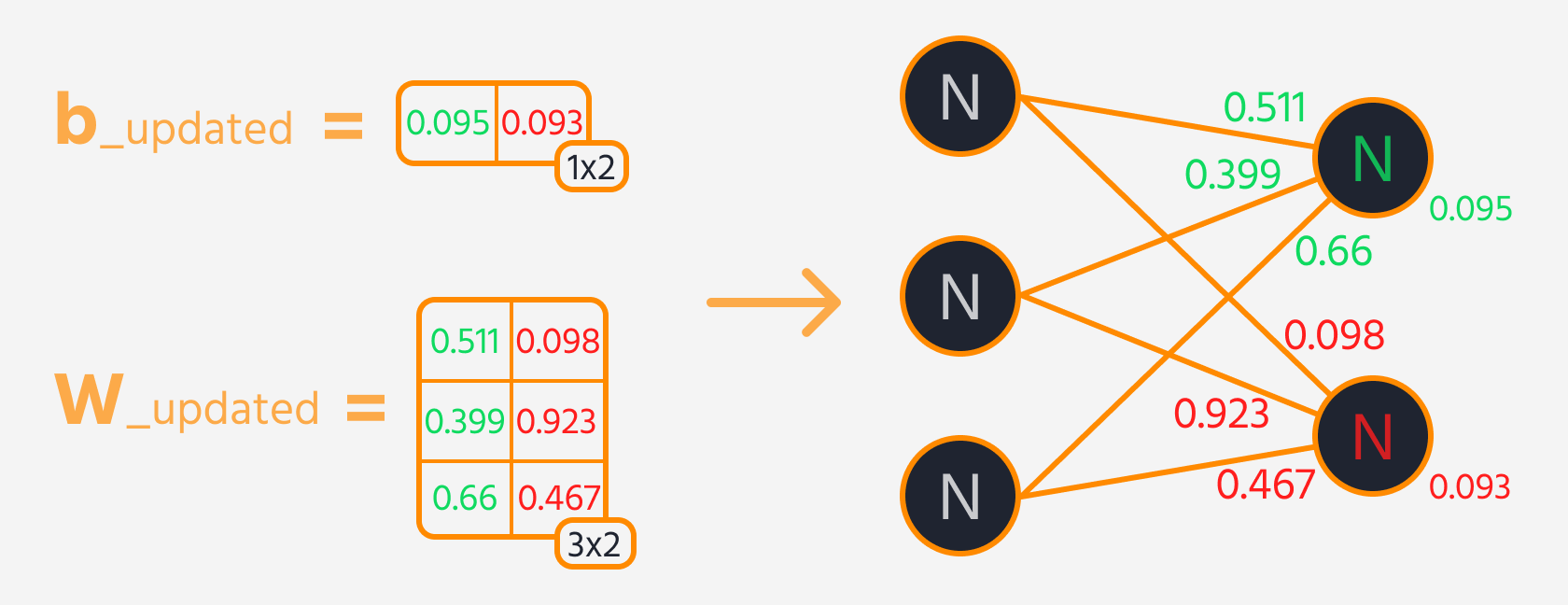
Boucle d'entraînement
Pour entraîner efficacement le réseau de neurones, les étapes d'entraînement sont répétées plusieurs fois tout en suivant les performances du modèle. Idéalement, la perte doit diminuer au fil des époques.
Glissez pour commencer à coder
Créer un réseau de neurones conçu pour prédire les résultats de l'opération XOR. Le réseau doit comporter 2 neurones d'entrée, une couche cachée avec 2 neurones, et 1 neurone de sortie.
- Commencer par initialiser les poids et les biais. Les poids doivent être initialisés à l'aide d'une distribution normale, et tous les biais doivent être initialisés à zéro. Utiliser les hyperparamètres
input_size,hidden_sizeetoutput_sizepour définir les dimensions appropriées de ces tenseurs. - Utiliser un décorateur de fonction pour transformer la fonction
train_step()en un graphe TensorFlow. - Effectuer la propagation avant à travers les couches cachée et de sortie du réseau. Utiliser la fonction d'activation sigmoïde.
- Déterminer les gradients afin de comprendre l'impact de chaque poids et biais sur la perte. S'assurer que les gradients sont calculés dans le bon ordre, correspondant aux noms des variables de sortie.
- Modifier les poids et les biais en fonction de leurs gradients respectifs. Incorporer le
learning_ratedans ce processus d'ajustement pour contrôler l'ampleur de chaque mise à jour.
Solution
Préparation des données
X_data: données d'entrée pour la fonction XOR. Tableau NumPy de forme (4, 2), représentant les quatre combinaisons possibles des entrées XOR (0,0), (0,1), (1,0) et (1,1) ;Y_data: sortie cible pour chaque combinaison d'entrée dansX_data. Également un tableau NumPy mais de forme (4, 1), représentant la sortie XOR pour chaque paire d'entrées.
Paramètres du réseau
input_size: taille de la couche d'entrée, fixée à 2, correspondant aux deux nœuds d'entrée (pour les deux entrées de la fonction XOR) ;hidden_size: taille de la couche cachée, également fixée à 2. Ce choix est quelque peu arbitraire mais suffit pour apprendre la fonction XOR ;output_size: taille de la couche de sortie, fixée à 1, correspondant à l'unique nœud de sortie (le résultat de l'opération XOR) ;learning_rate: taux d'apprentissage pour l'algorithme d'optimisation, contrôlant l'ajustement des poids lors de l'entraînement.
Poids et biais
W1etb1: poids (W1) et biais (b1) pour les connexions de la couche d'entrée à la couche cachée.W1est une variable TensorFlow initialisée avec des valeurs aléatoires et de forme(input_size, hidden_size), c'est-à-dire(2, 2).b1est une variable TensorFlow initialisée à zéro et de forme(hidden_size), c'est-à-dire(2);W2etb2: poids (W2) et biais (b2) pour les connexions de la couche cachée à la couche de sortie.W2est initialisé avec des valeurs aléatoires et de forme(hidden_size, output_size), c'est-à-dire(2, 1).b2est initialisé à zéro et de forme(output_size), c'est-à-dire(1).
Fonction d'entraînement
train_step(): fonction principale d'entraînement. Utilisetf.GradientTape()pour la différenciation automatique. Lors du passage avant, elle calcule les activations de la couche cachée (a1) et les prédictions de sortie (Y_pred). La perte est calculée comme l'erreur quadratique moyenne entreY_predetY. La fonction calcule ensuite les gradients et met à jour les poids et biais ;tf.sigmoid(): fonction d'activation sigmoïde utilisée, qui transforme l'entrée en une valeur comprise entre0et1. Utilisée pour la couche cachée et la couche de sortie.
Boucle d'entraînement
- Le réseau est entraîné pendant
2500époques. À chaque époque, la fonctiontrain_step()est appelée et les poids sont mis à jour. La perte est affichée toutes les500époques pour suivre la progression de l'entraînement.
Conclusion
Comme la fonction XOR est une tâche relativement simple, il n'est pas nécessaire d'utiliser des techniques avancées telles que l'ajustement d'hyperparamètres, la division du jeu de données ou la création de pipelines de données complexes à ce stade. Cet exercice constitue une étape vers la construction de réseaux de neurones plus sophistiqués pour des applications réelles.
La maîtrise de ces bases est essentielle avant d'aborder les techniques avancées de construction de réseaux de neurones dans les prochains cours, où la bibliothèque Keras sera utilisée et où des méthodes pour améliorer la qualité des modèles avec les fonctionnalités avancées de TensorFlow seront explorées.
Merci pour vos commentaires !
single
Demandez à l'IA
Demandez à l'IA

Posez n'importe quelle question ou essayez l'une des questions suggérées pour commencer notre discussion
