Implémentation de Word2Vec
Glissez pour afficher le menu
Après avoir compris le fonctionnement de Word2Vec, passons à son implémentation en Python. La bibliothèque Gensim, un outil open-source robuste pour le traitement du langage naturel, propose une implémentation simple via sa classe Word2Vec dans gensim.models.
Préparation des données
Word2Vec nécessite que les données textuelles soient tokenisées, c'est-à-dire transformées en une liste de listes où chaque sous-liste contient les mots d'une phrase spécifique. Pour cet exemple, nous utiliserons le roman Emma de l'auteure anglaise Jane Austen comme corpus. Nous chargerons un fichier CSV contenant des phrases prétraitées, puis nous découperons chaque phrase en mots :
12345678import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') # Split each sentence into words sentences = emma_df['Sentence'].str.split() # Print the fourth sentence (list of words) print(sentences[3])
emma_df['Sentence'].str.split() applique la méthode .split() à chaque phrase de la colonne 'Sentence', produisant ainsi une liste de mots pour chaque phrase. Étant donné que les phrases ont déjà été prétraitées, avec des mots séparés par des espaces, la méthode .split() suffit pour cette tokenisation.
Entraînement du modèle Word2Vec
Concentrons-nous maintenant sur l'entraînement du modèle Word2Vec à l'aide des données tokenisées. La classe Word2Vec propose divers paramètres de personnalisation. Cependant, les paramètres les plus couramment utilisés sont les suivants :
vector_size(100 par défaut) : dimensionnalité ou taille des embeddings de mots ;window(5 par défaut) : taille de la fenêtre de contexte ;min_count(5 par défaut) : les mots apparaissant moins souvent que ce nombre seront ignorés ;sg(0 par défaut) : architecture du modèle à utiliser (1 pour Skip-gram, 0 pour CBoW).cbow_mean(1 par défaut) : spécifie si le contexte d'entrée CBoW est additionné (0) ou moyenné (1)
Concernant les architectures de modèles, CBoW convient aux ensembles de données volumineux et aux situations où l'efficacité computationnelle est essentielle. Skip-gram, en revanche, est préférable pour les tâches nécessitant une compréhension détaillée des contextes de mots, particulièrement efficace sur de petits ensembles de données ou lors du traitement de mots rares.
12345678from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() # Initialize the model model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0)
Ici, la taille de l'embedding est fixée à 200, la taille de la fenêtre de contexte à 5, et tous les mots sont inclus en définissant min_count=1. En définissant sg=0, le modèle CBoW est utilisé.
Le choix de la taille de l'embedding et de la fenêtre de contexte implique des compromis. Des embeddings plus grands capturent davantage de sens mais augmentent le coût computationnel et le risque de surapprentissage. Des fenêtres de contexte plus petites sont plus efficaces pour capturer la syntaxe, tandis que des fenêtres plus grandes sont meilleures pour capturer la sémantique.
Recherche de mots similaires
Une fois que les mots sont représentés sous forme de vecteurs, il est possible de les comparer pour mesurer leur similarité. Bien que l'utilisation de la distance soit une option, la direction d'un vecteur porte souvent plus de signification sémantique que sa magnitude, en particulier dans les embeddings de mots.
Cependant, utiliser directement l'angle comme métrique de similarité n'est pas très pratique. À la place, il est possible d'utiliser le cosinus de l'angle entre deux vecteurs, également appelé similarité cosinus. Cette mesure varie de -1 à 1, des valeurs plus élevées indiquant une similarité plus forte. Cette approche se concentre sur l'alignement des vecteurs, indépendamment de leur longueur, ce qui la rend idéale pour comparer le sens des mots. Voici une illustration :
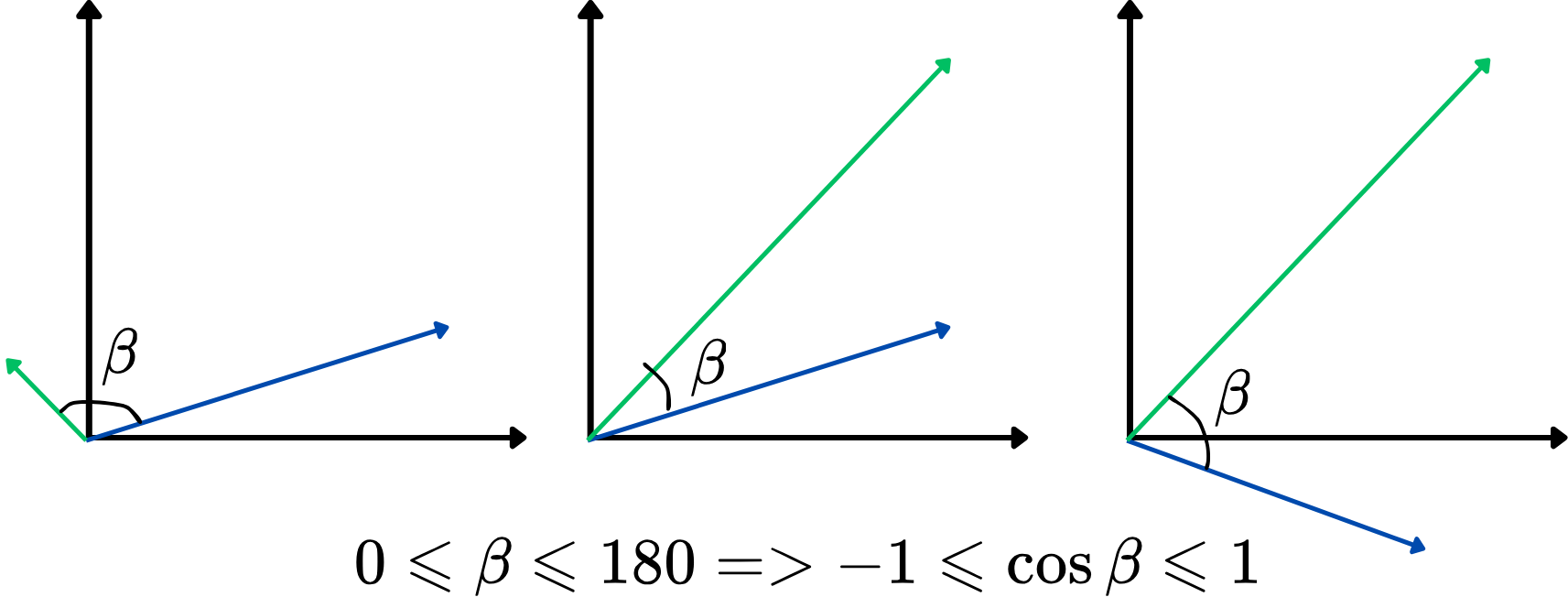
Plus la similarité cosinus est élevée, plus les deux vecteurs sont similaires, et inversement. Par exemple, si deux vecteurs de mots ont une similarité cosinus proche de 1 (l’angle proche de 0 degré), cela indique qu’ils sont étroitement liés ou similaires dans le contexte de l’espace vectoriel.
Trouvons maintenant les 5 mots les plus similaires au mot « man » en utilisant la similarité cosinus :
12345678910from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0) # Retrieve the top-5 most similar words to 'man' similar_words = model.wv.most_similar('man', topn=5) print(similar_words)
model.wv permet d’accéder aux vecteurs de mots du modèle entraîné, tandis que la méthode .most_similar() identifie les mots dont les embeddings sont les plus proches de celui du mot spécifié, selon la similarité cosinus. Le paramètre topn détermine le nombre de mots top-N similaires à retourner.
Merci pour vos commentaires !
Demandez à l'IA
Demandez à l'IA

Posez n'importe quelle question ou essayez l'une des questions suggérées pour commencer notre discussion
Implémentation de Word2Vec
Après avoir compris le fonctionnement de Word2Vec, passons à son implémentation en Python. La bibliothèque Gensim, un outil open-source robuste pour le traitement du langage naturel, propose une implémentation simple via sa classe Word2Vec dans gensim.models.
Préparation des données
Word2Vec nécessite que les données textuelles soient tokenisées, c'est-à-dire transformées en une liste de listes où chaque sous-liste contient les mots d'une phrase spécifique. Pour cet exemple, nous utiliserons le roman Emma de l'auteure anglaise Jane Austen comme corpus. Nous chargerons un fichier CSV contenant des phrases prétraitées, puis nous découperons chaque phrase en mots :
12345678import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') # Split each sentence into words sentences = emma_df['Sentence'].str.split() # Print the fourth sentence (list of words) print(sentences[3])
emma_df['Sentence'].str.split() applique la méthode .split() à chaque phrase de la colonne 'Sentence', produisant ainsi une liste de mots pour chaque phrase. Étant donné que les phrases ont déjà été prétraitées, avec des mots séparés par des espaces, la méthode .split() suffit pour cette tokenisation.
Entraînement du modèle Word2Vec
Concentrons-nous maintenant sur l'entraînement du modèle Word2Vec à l'aide des données tokenisées. La classe Word2Vec propose divers paramètres de personnalisation. Cependant, les paramètres les plus couramment utilisés sont les suivants :
vector_size(100 par défaut) : dimensionnalité ou taille des embeddings de mots ;window(5 par défaut) : taille de la fenêtre de contexte ;min_count(5 par défaut) : les mots apparaissant moins souvent que ce nombre seront ignorés ;sg(0 par défaut) : architecture du modèle à utiliser (1 pour Skip-gram, 0 pour CBoW).cbow_mean(1 par défaut) : spécifie si le contexte d'entrée CBoW est additionné (0) ou moyenné (1)
Concernant les architectures de modèles, CBoW convient aux ensembles de données volumineux et aux situations où l'efficacité computationnelle est essentielle. Skip-gram, en revanche, est préférable pour les tâches nécessitant une compréhension détaillée des contextes de mots, particulièrement efficace sur de petits ensembles de données ou lors du traitement de mots rares.
12345678from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() # Initialize the model model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0)
Ici, la taille de l'embedding est fixée à 200, la taille de la fenêtre de contexte à 5, et tous les mots sont inclus en définissant min_count=1. En définissant sg=0, le modèle CBoW est utilisé.
Le choix de la taille de l'embedding et de la fenêtre de contexte implique des compromis. Des embeddings plus grands capturent davantage de sens mais augmentent le coût computationnel et le risque de surapprentissage. Des fenêtres de contexte plus petites sont plus efficaces pour capturer la syntaxe, tandis que des fenêtres plus grandes sont meilleures pour capturer la sémantique.
Recherche de mots similaires
Une fois que les mots sont représentés sous forme de vecteurs, il est possible de les comparer pour mesurer leur similarité. Bien que l'utilisation de la distance soit une option, la direction d'un vecteur porte souvent plus de signification sémantique que sa magnitude, en particulier dans les embeddings de mots.
Cependant, utiliser directement l'angle comme métrique de similarité n'est pas très pratique. À la place, il est possible d'utiliser le cosinus de l'angle entre deux vecteurs, également appelé similarité cosinus. Cette mesure varie de -1 à 1, des valeurs plus élevées indiquant une similarité plus forte. Cette approche se concentre sur l'alignement des vecteurs, indépendamment de leur longueur, ce qui la rend idéale pour comparer le sens des mots. Voici une illustration :
Plus la similarité cosinus est élevée, plus les deux vecteurs sont similaires, et inversement. Par exemple, si deux vecteurs de mots ont une similarité cosinus proche de 1 (l’angle proche de 0 degré), cela indique qu’ils sont étroitement liés ou similaires dans le contexte de l’espace vectoriel.
Trouvons maintenant les 5 mots les plus similaires au mot « man » en utilisant la similarité cosinus :
12345678910from gensim.models import Word2Vec import pandas as pd emma_df = pd.read_csv( 'https://content-media-cdn.codefinity.com/courses/c68c1f2e-2c90-4d5d-8db9-1e97ca89d15e/section_4/chapter_3/emma.csv') sentences = emma_df['Sentence'].str.split() model = Word2Vec(sentences, vector_size=200, window=5, min_count=1, sg=0) # Retrieve the top-5 most similar words to 'man' similar_words = model.wv.most_similar('man', topn=5) print(similar_words)
model.wv permet d’accéder aux vecteurs de mots du modèle entraîné, tandis que la méthode .most_similar() identifie les mots dont les embeddings sont les plus proches de celui du mot spécifié, selon la similarité cosinus. Le paramètre topn détermine le nombre de mots top-N similaires à retourner.
Merci pour vos commentaires !
