Aperçu des Modèles CNN Populaires
Glissez pour afficher le menu
Les réseaux de neurones convolutifs (CNN) ont considérablement évolué, avec diverses architectures améliorant la précision, l'efficacité et l'évolutivité. Ce chapitre explore cinq modèles clés de CNN qui ont façonné l'apprentissage profond : LeNet, AlexNet, VGGNet, ResNet et InceptionNet.
LeNet : La fondation des CNN
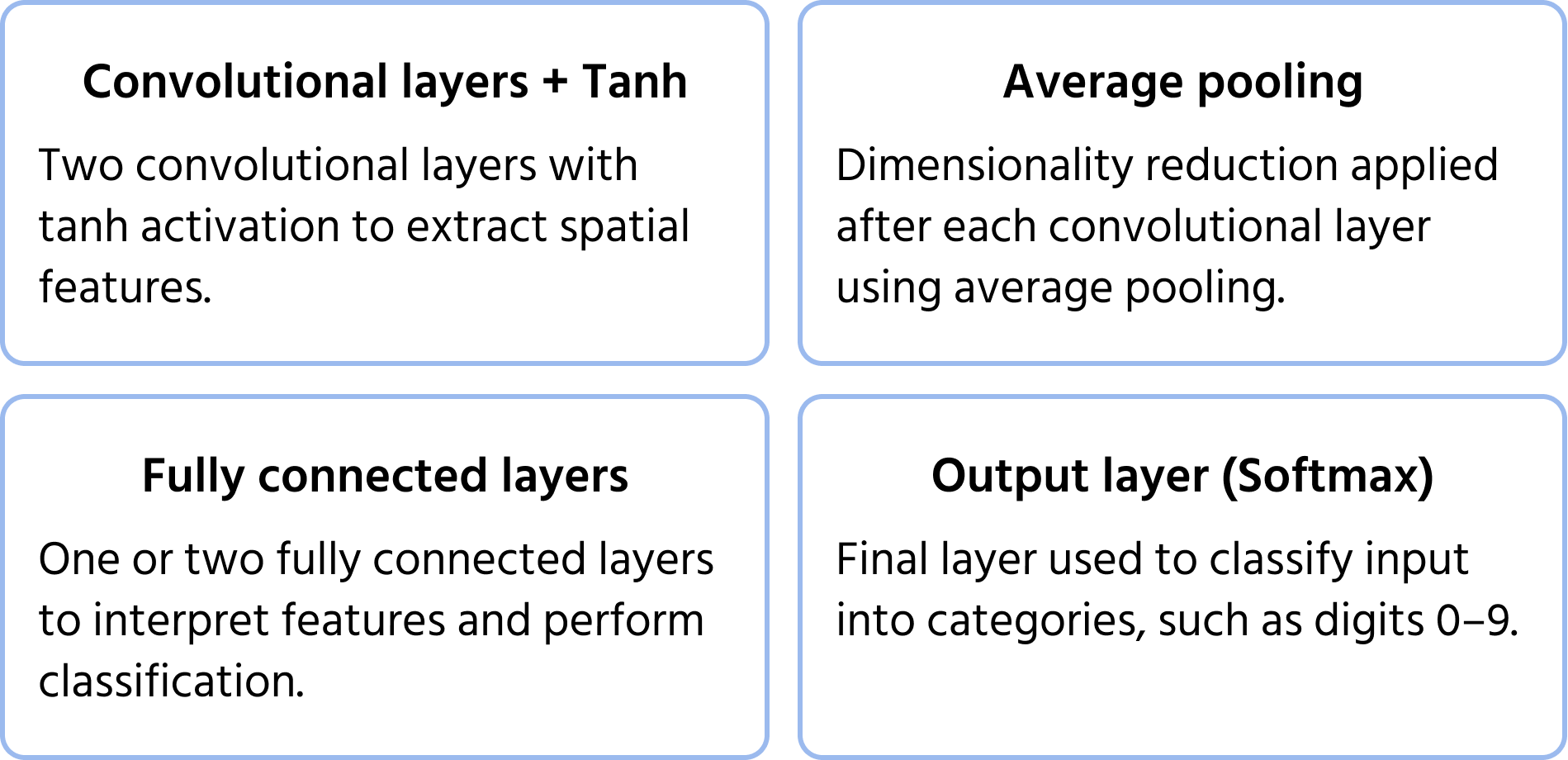
L'une des premières architectures de réseaux de neurones convolutifs, proposée par Yann LeCun en 1998 pour la reconnaissance de chiffres manuscrits. Elle a posé les bases des CNN modernes en introduisant des composants clés tels que les convolutions, le pooling et les couches entièrement connectées. Vous pouvez en apprendre davantage sur le modèle dans la documentation.
Caractéristiques architecturales clés
AlexNet : Avancée majeure en apprentissage profond
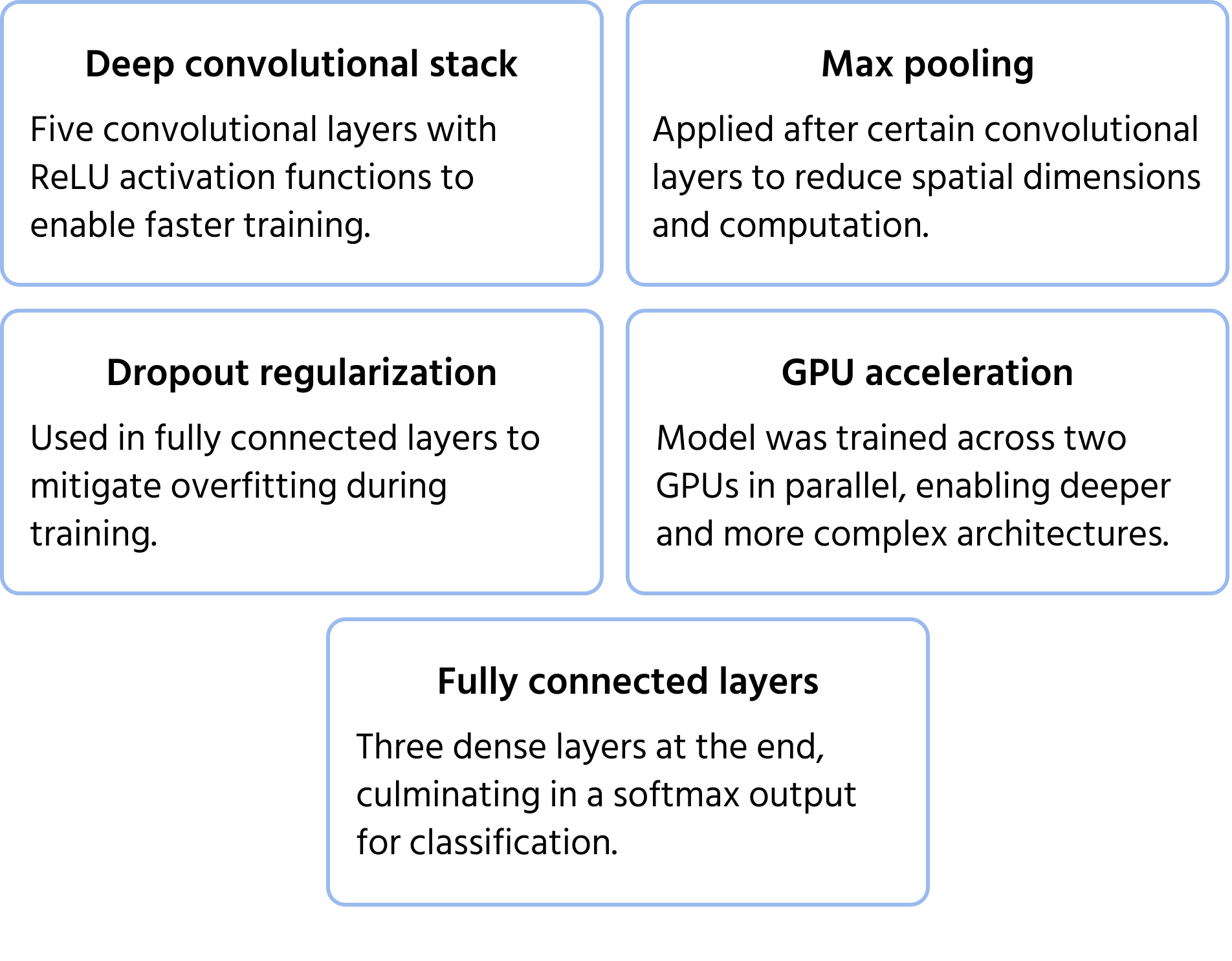
Architecture CNN emblématique ayant remporté la compétition ImageNet 2012, AlexNet a démontré que les réseaux de neurones convolutifs profonds pouvaient largement surpasser les méthodes traditionnelles d'apprentissage automatique pour la classification d'images à grande échelle. Ce modèle a introduit des innovations devenues des standards dans l'apprentissage profond moderne. Plus d'informations sur le modèle dans la documentation.
Caractéristiques principales de l'architecture
VGGNet : Réseaux Profonds avec Filtres Uniformes
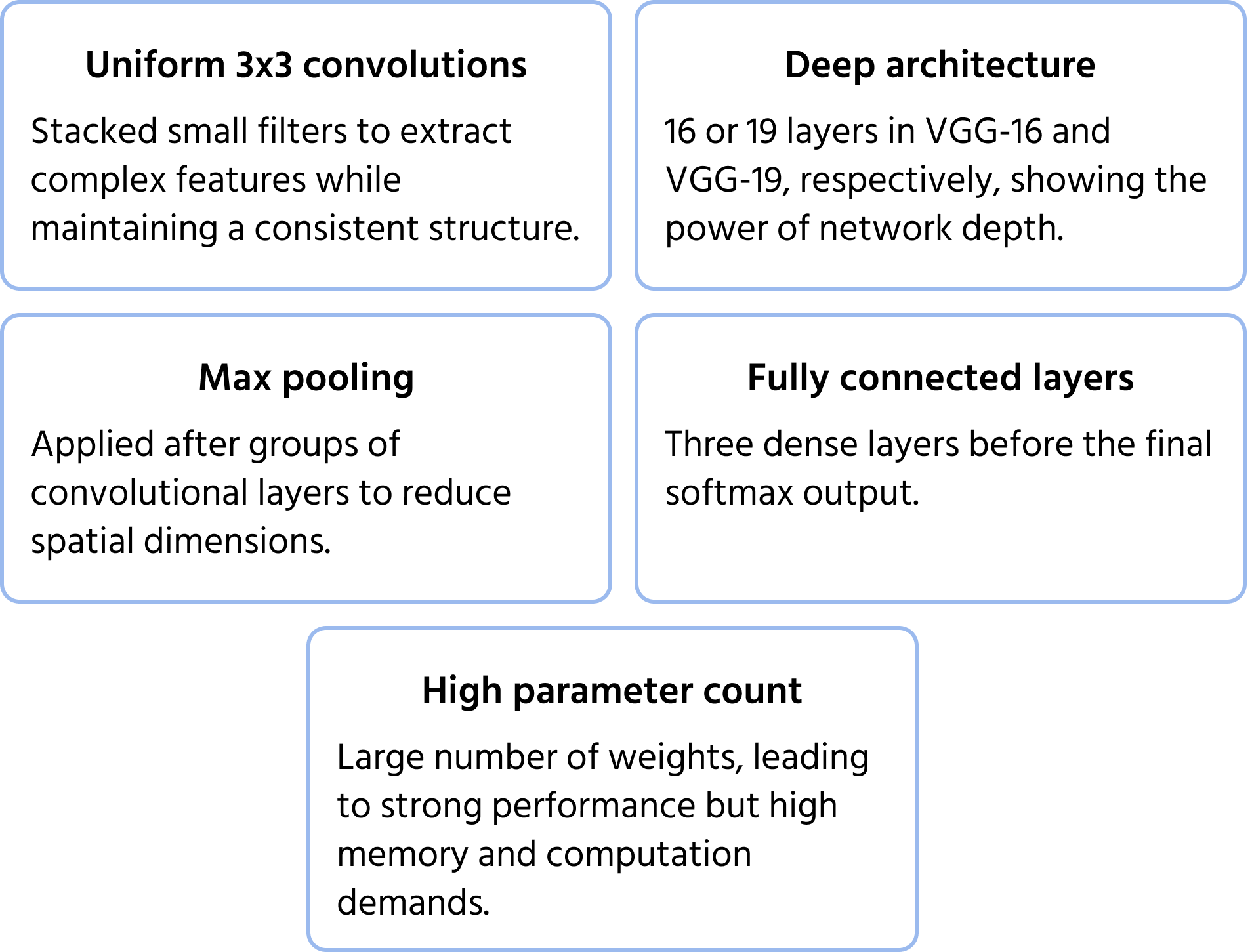
Développé par le Visual Geometry Group d'Oxford, VGGNet met l'accent sur la profondeur et la simplicité en utilisant des filtres de convolution uniformes 3×3. Il a démontré que l'empilement de petits filtres dans des réseaux profonds pouvait améliorer considérablement les performances, donnant naissance à des variantes largement utilisées comme VGG-16 et VGG-19. Vous pouvez en savoir plus sur le modèle dans la documentation.
Principales Caractéristiques de l’Architecture
ResNet : Résolution du problème de profondeur
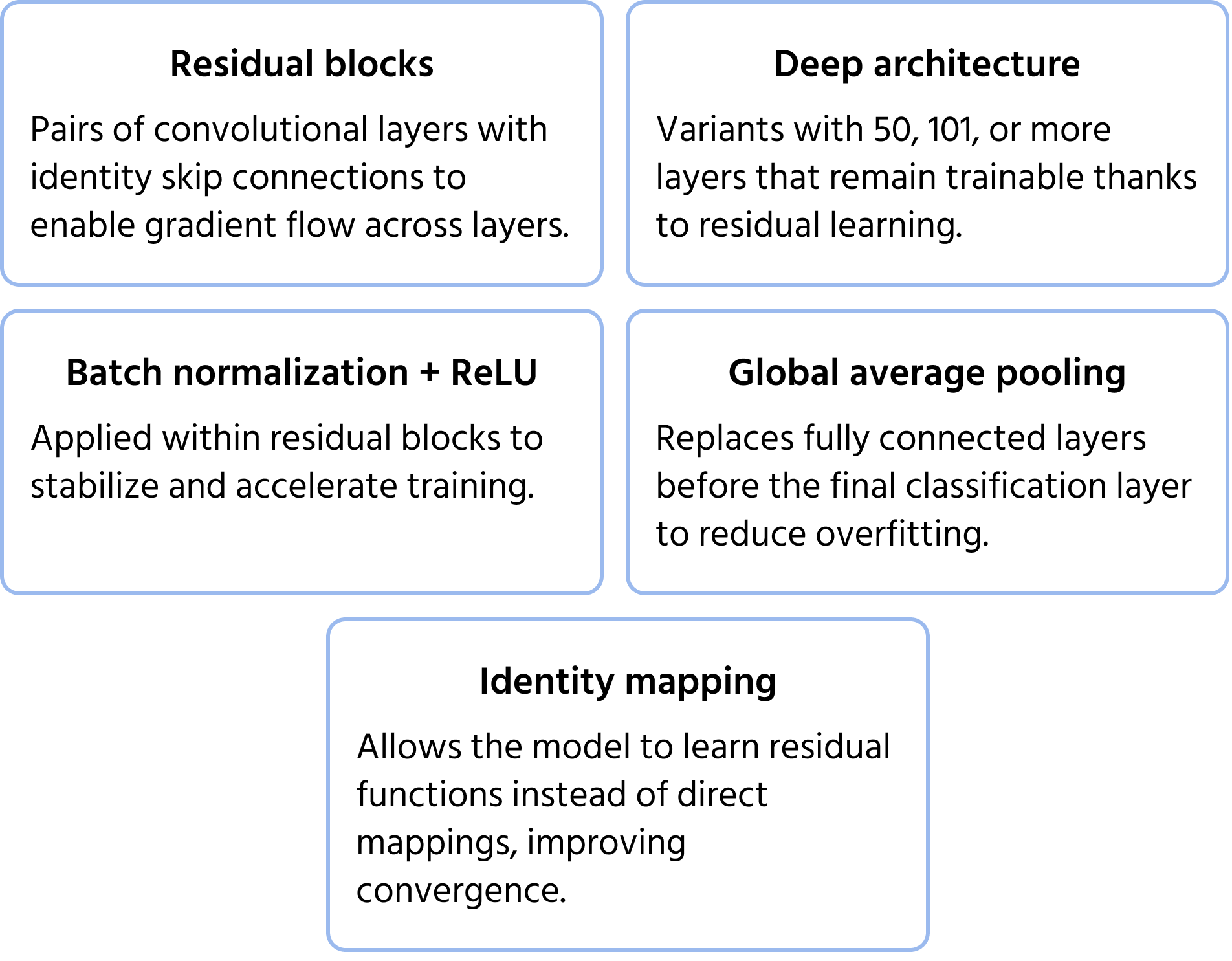
ResNet (Réseaux Résiduels), introduit par Microsoft en 2015, a résolu le problème du gradient qui disparaît, qui survient lors de l'entraînement de réseaux très profonds. Les réseaux profonds traditionnels rencontrent des difficultés en termes d'efficacité d'entraînement et de dégradation des performances, mais ResNet a surmonté ce problème grâce aux connexions de saut (apprentissage résiduel). Ces raccourcis permettent à l'information de contourner certaines couches, garantissant ainsi la propagation efficace des gradients. Les architectures ResNet, telles que ResNet-50 et ResNet-101, ont permis l'entraînement de réseaux comportant des centaines de couches, améliorant significativement la précision de la classification d'images. Vous pouvez en apprendre davantage sur le modèle dans la documentation.
Principales caractéristiques de l'architecture
InceptionNet : Extraction de caractéristiques multi-échelle
InceptionNet (également appelé GoogLeNet) s'appuie sur le module inception pour créer une architecture profonde mais efficace. Au lieu d'empiler les couches de manière séquentielle, InceptionNet utilise des chemins parallèles pour extraire des caractéristiques à différents niveaux. Vous pouvez en apprendre davantage sur le modèle dans la documentation.
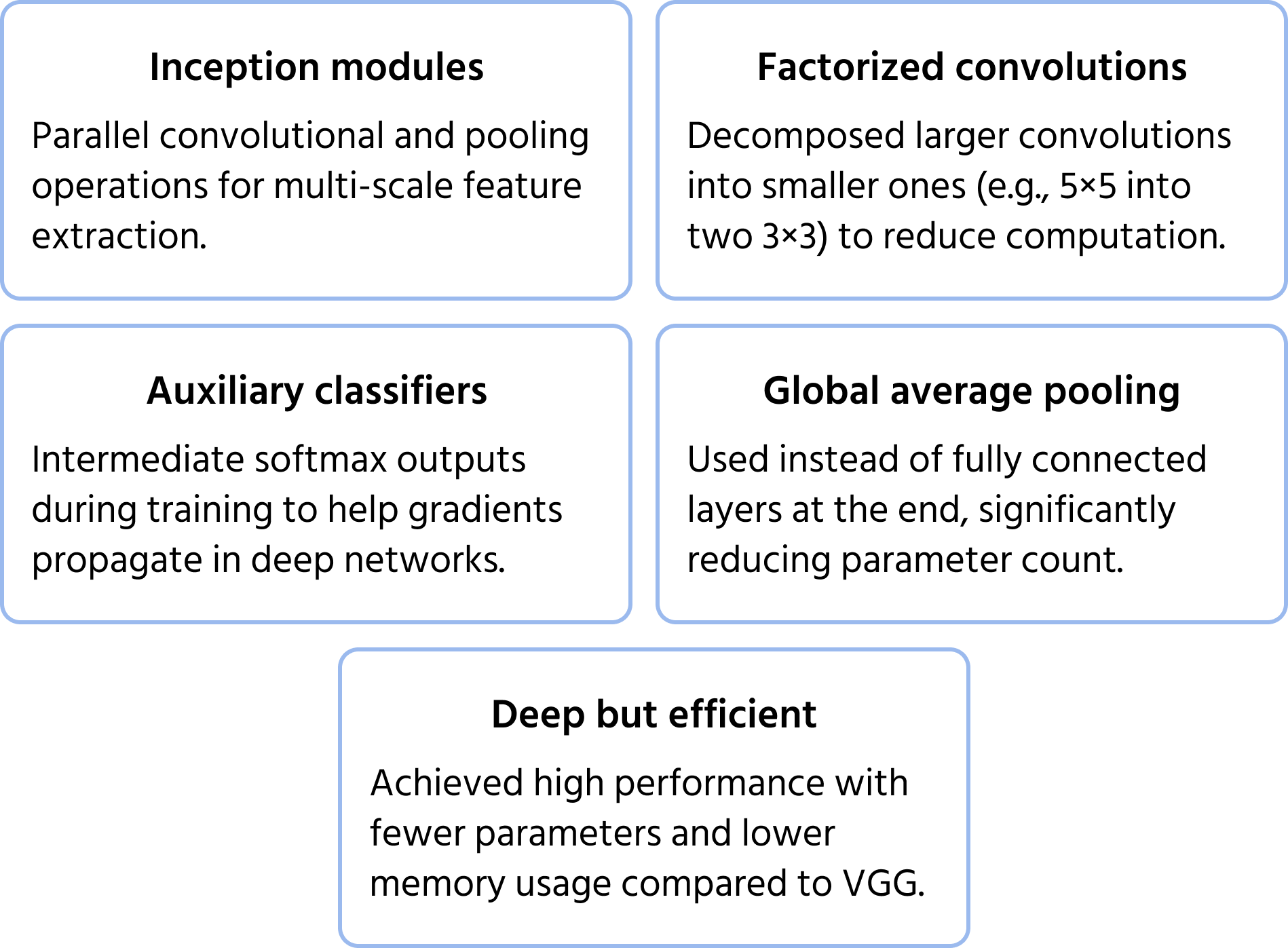
Les principales optimisations incluent :
- Convolutions factorisées pour réduire le coût computationnel ;
- Classifieurs auxiliaires dans les couches intermédiaires pour améliorer la stabilité de l'entraînement ;
- Global average pooling au lieu de couches entièrement connectées, réduisant le nombre de paramètres tout en maintenant la performance.
Cette structure permet à InceptionNet d'être plus profond que les CNN précédents comme VGG, sans augmenter drastiquement les besoins en calcul.
Principales caractéristiques de l'architecture
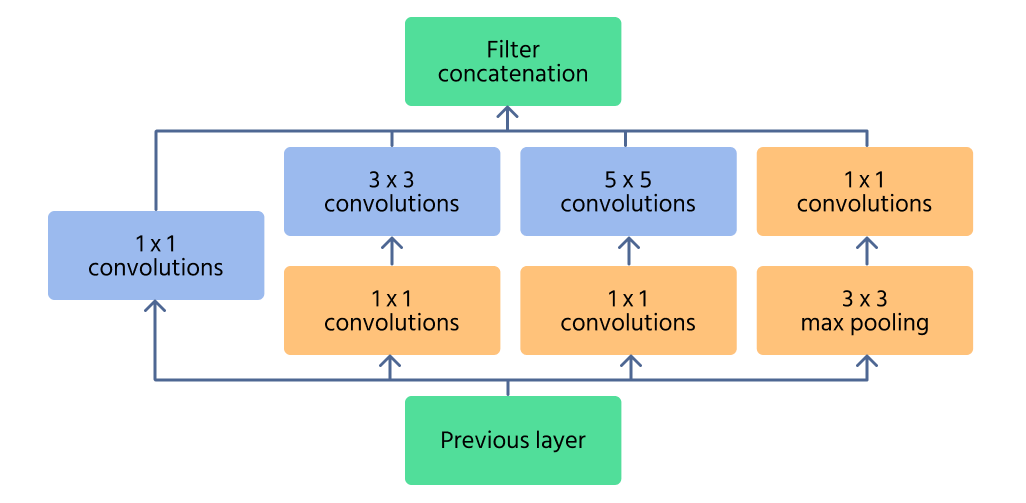
Module Inception
Le module Inception constitue l’élément central d’InceptionNet, conçu pour capturer efficacement des caractéristiques à plusieurs échelles. Au lieu d’appliquer une seule opération de convolution, le module traite l’entrée avec plusieurs tailles de filtres (1×1, 3×3, 5×5) en parallèle. Cela permet au réseau de reconnaître à la fois les détails fins et les grands motifs dans une image.
Pour réduire le coût computationnel, des 1×1 convolutions sont utilisées avant l’application de filtres plus grands. Celles-ci réduisent le nombre de canaux d’entrée, rendant le réseau plus efficace. De plus, des couches de max pooling à l’intérieur du module permettent de conserver les caractéristiques essentielles tout en contrôlant la dimensionnalité.
Exemple
Considérer un exemple pour illustrer comment la réduction des dimensions diminue la charge de calcul. Supposons que l'on doive convoluer des 28 × 28 × 192 input feature maps avec des 5 × 5 × 32 filters. Cette opération nécessiterait environ 120,42 millions de calculs.

Number of operations = (2828192) * (5532) = 120,422,400 operations
Répétons les calculs, mais cette fois, insérons une 1×1 convolutional layer avant d'appliquer la 5×5 convolution sur les mêmes cartes de caractéristiques d'entrée.

Number of operations for 1x1 convolution = (2828192) * (1116) = 2,408,448 operations
Number of operations for 5x5 convolution = (282816) * (5532) = 10,035,200 operations
Total number of operations 2,408,448 + 10,035,200 = 12,443,648 operations
Chacune de ces architectures CNN a joué un rôle déterminant dans l'avancement de la vision par ordinateur, influençant des applications dans les domaines de la santé, des systèmes autonomes, de la sécurité et du traitement d'images en temps réel. Des principes fondamentaux de LeNet à l'extraction de caractéristiques multi-échelles d'InceptionNet, ces modèles ont continuellement repoussé les limites de l'apprentissage profond, ouvrant la voie à des architectures encore plus avancées à l'avenir.
1. Quelle a été l'innovation principale introduite par ResNet qui a permis d'entraîner des réseaux extrêmement profonds ?
2. Comment InceptionNet améliore-t-il l'efficacité computationnelle par rapport aux CNN traditionnels ?
3. Quelle architecture CNN a introduit pour la première fois le concept d'utilisation de petits filtres de convolution 3×3 dans tout le réseau ?
Merci pour vos commentaires !
Demandez à l'IA
Demandez à l'IA

Posez n'importe quelle question ou essayez l'une des questions suggérées pour commencer notre discussion
Aperçu des Modèles CNN Populaires
Les réseaux de neurones convolutifs (CNN) ont considérablement évolué, avec diverses architectures améliorant la précision, l'efficacité et l'évolutivité. Ce chapitre explore cinq modèles clés de CNN qui ont façonné l'apprentissage profond : LeNet, AlexNet, VGGNet, ResNet et InceptionNet.
LeNet : La fondation des CNN
L'une des premières architectures de réseaux de neurones convolutifs, proposée par Yann LeCun en 1998 pour la reconnaissance de chiffres manuscrits. Elle a posé les bases des CNN modernes en introduisant des composants clés tels que les convolutions, le pooling et les couches entièrement connectées. Vous pouvez en apprendre davantage sur le modèle dans la documentation.
Caractéristiques architecturales clés
AlexNet : Avancée majeure en apprentissage profond
Architecture CNN emblématique ayant remporté la compétition ImageNet 2012, AlexNet a démontré que les réseaux de neurones convolutifs profonds pouvaient largement surpasser les méthodes traditionnelles d'apprentissage automatique pour la classification d'images à grande échelle. Ce modèle a introduit des innovations devenues des standards dans l'apprentissage profond moderne. Plus d'informations sur le modèle dans la documentation.
Caractéristiques principales de l'architecture
VGGNet : Réseaux Profonds avec Filtres Uniformes
Développé par le Visual Geometry Group d'Oxford, VGGNet met l'accent sur la profondeur et la simplicité en utilisant des filtres de convolution uniformes 3×3. Il a démontré que l'empilement de petits filtres dans des réseaux profonds pouvait améliorer considérablement les performances, donnant naissance à des variantes largement utilisées comme VGG-16 et VGG-19. Vous pouvez en savoir plus sur le modèle dans la documentation.
Principales Caractéristiques de l’Architecture
ResNet : Résolution du problème de profondeur
ResNet (Réseaux Résiduels), introduit par Microsoft en 2015, a résolu le problème du gradient qui disparaît, qui survient lors de l'entraînement de réseaux très profonds. Les réseaux profonds traditionnels rencontrent des difficultés en termes d'efficacité d'entraînement et de dégradation des performances, mais ResNet a surmonté ce problème grâce aux connexions de saut (apprentissage résiduel). Ces raccourcis permettent à l'information de contourner certaines couches, garantissant ainsi la propagation efficace des gradients. Les architectures ResNet, telles que ResNet-50 et ResNet-101, ont permis l'entraînement de réseaux comportant des centaines de couches, améliorant significativement la précision de la classification d'images. Vous pouvez en apprendre davantage sur le modèle dans la documentation.
Principales caractéristiques de l'architecture
InceptionNet : Extraction de caractéristiques multi-échelle
InceptionNet (également appelé GoogLeNet) s'appuie sur le module inception pour créer une architecture profonde mais efficace. Au lieu d'empiler les couches de manière séquentielle, InceptionNet utilise des chemins parallèles pour extraire des caractéristiques à différents niveaux. Vous pouvez en apprendre davantage sur le modèle dans la documentation.
Les principales optimisations incluent :
- Convolutions factorisées pour réduire le coût computationnel ;
- Classifieurs auxiliaires dans les couches intermédiaires pour améliorer la stabilité de l'entraînement ;
- Global average pooling au lieu de couches entièrement connectées, réduisant le nombre de paramètres tout en maintenant la performance.
Cette structure permet à InceptionNet d'être plus profond que les CNN précédents comme VGG, sans augmenter drastiquement les besoins en calcul.
Principales caractéristiques de l'architecture
Module Inception
Le module Inception constitue l’élément central d’InceptionNet, conçu pour capturer efficacement des caractéristiques à plusieurs échelles. Au lieu d’appliquer une seule opération de convolution, le module traite l’entrée avec plusieurs tailles de filtres (1×1, 3×3, 5×5) en parallèle. Cela permet au réseau de reconnaître à la fois les détails fins et les grands motifs dans une image.
Pour réduire le coût computationnel, des 1×1 convolutions sont utilisées avant l’application de filtres plus grands. Celles-ci réduisent le nombre de canaux d’entrée, rendant le réseau plus efficace. De plus, des couches de max pooling à l’intérieur du module permettent de conserver les caractéristiques essentielles tout en contrôlant la dimensionnalité.
Exemple
Considérer un exemple pour illustrer comment la réduction des dimensions diminue la charge de calcul. Supposons que l'on doive convoluer des 28 × 28 × 192 input feature maps avec des 5 × 5 × 32 filters. Cette opération nécessiterait environ 120,42 millions de calculs.
Number of operations = (2828192) * (5532) = 120,422,400 operations
Répétons les calculs, mais cette fois, insérons une 1×1 convolutional layer avant d'appliquer la 5×5 convolution sur les mêmes cartes de caractéristiques d'entrée.
Number of operations for 1x1 convolution = (2828192) * (1116) = 2,408,448 operations
Number of operations for 5x5 convolution = (282816) * (5532) = 10,035,200 operations
Total number of operations 2,408,448 + 10,035,200 = 12,443,648 operations
Chacune de ces architectures CNN a joué un rôle déterminant dans l'avancement de la vision par ordinateur, influençant des applications dans les domaines de la santé, des systèmes autonomes, de la sécurité et du traitement d'images en temps réel. Des principes fondamentaux de LeNet à l'extraction de caractéristiques multi-échelles d'InceptionNet, ces modèles ont continuellement repoussé les limites de l'apprentissage profond, ouvrant la voie à des architectures encore plus avancées à l'avenir.
Merci pour vos commentaires !
