Fonctions d'Activation
Glissez pour afficher le menu
Pourquoi les fonctions d’activation sont essentielles dans les CNN
Les fonctions d’activation introduisent de la non-linéarité dans les CNN, leur permettant d’apprendre des motifs complexes au-delà de ce qu’un simple modèle linéaire peut réaliser. Sans fonctions d’activation, les CNN auraient du mal à détecter des relations complexes dans les données, limitant ainsi leur efficacité en reconnaissance et classification d’images. Le choix approprié de la fonction d’activation influence la vitesse d’apprentissage, la stabilité et la performance globale.
Fonctions d’activation courantes
- ReLU (rectified linear unit) : la fonction d’activation la plus utilisée dans les CNN. Elle transmet uniquement les valeurs positives et fixe toutes les entrées négatives à zéro, ce qui la rend efficace sur le plan computationnel et prévient le problème du gradient qui disparaît. Cependant, certains neurones peuvent devenir inactifs à cause du problème du « ReLU mourant » ;

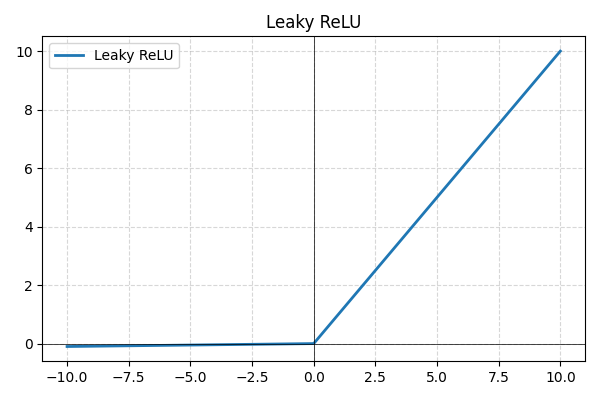
- Leaky ReLU : une variante de ReLU qui autorise de petites valeurs négatives au lieu de les fixer à zéro, évitant ainsi l'inactivation des neurones et améliorant la propagation du gradient ;
- Sigmoïde : compresse les valeurs d'entrée dans une plage comprise entre 0 et 1, ce qui le rend utile pour la classification binaire. Cependant, il présente le problème de gradients évanescents dans les réseaux profonds ;

- Tanh : fonction similaire à la sigmoïde mais produisant des valeurs comprises entre -1 et 1, ce qui centre les activations autour de zéro ;

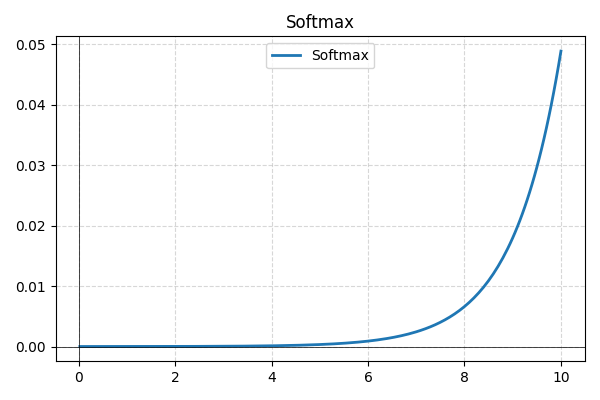
- Softmax : généralement utilisée dans la couche finale pour la classification multi-classes, la fonction Softmax convertit les sorties brutes du réseau en probabilités, garantissant que leur somme est égale à un pour une meilleure interprétabilité.
Choix de la fonction d'activation appropriée
ReLU est le choix par défaut pour les couches cachées en raison de son efficacité et de ses bonnes performances, tandis que Leaky ReLU constitue une meilleure option lorsque l'inactivité des neurones devient problématique. Sigmoid et Tanh sont généralement évités dans les CNN profonds mais peuvent rester utiles dans des applications spécifiques. Softmax demeure essentielle pour les tâches de classification multi-classes, garantissant des prédictions claires basées sur les probabilités.
La sélection de la bonne fonction d'activation est cruciale pour optimiser les performances des CNN, équilibrer l'efficacité et prévenir des problèmes tels que les gradients évanescents ou explosifs. Chaque fonction contribue de manière unique à la façon dont un réseau traite et apprend à partir des données visuelles.
1. Pourquoi ReLU est-elle préférée à Sigmoid dans les CNN profonds ?
2. Quelle fonction d'activation est couramment utilisée dans la couche finale d'un CNN pour la classification multi-classes ?
3. Quel est l'avantage principal du Leaky ReLU par rapport au ReLU standard ?
Merci pour vos commentaires !
Demandez à l'IA
Demandez à l'IA

Posez n'importe quelle question ou essayez l'une des questions suggérées pour commencer notre discussion
