Aperçu de la Génération d'Images
Glissez pour afficher le menu
Les images générées par l’IA transforment la création artistique, le design et le contenu numérique. Grâce à l’intelligence artificielle, les ordinateurs peuvent désormais produire des images réalistes, enrichir les œuvres créatives et même soutenir les entreprises. Dans ce chapitre, présentation des méthodes de création d’images par l’IA, des différents types de modèles de génération d’images et de leurs applications concrètes.
Comment l’IA crée des images
La génération d’images par l’IA fonctionne en apprenant à partir d’une vaste collection de photos. L’IA analyse les motifs présents dans ces images, puis en crée de nouvelles qui leur ressemblent. Cette technologie a beaucoup progressé au fil des années, produisant des images de plus en plus réalistes et créatives. Elle est désormais utilisée dans les jeux vidéo, le cinéma, la publicité et même la mode.
Méthodes initiales : PixelRNN et PixelCNN
Avant les modèles d’IA avancés actuels, les chercheurs ont développé des méthodes de génération d’images comme PixelRNN et PixelCNN. Ces modèles créaient des images en prédisant un pixel à la fois.
- PixelRNN : utilise un réseau de neurones récurrents (RNN) pour prédire les couleurs des pixels successivement. Bien que performant, il était très lent ;
- PixelCNN : amélioration de PixelRNN grâce à l’utilisation de couches convolutionnelles, ce qui a accéléré la création d’images.
Même si ces modèles représentaient une avancée, ils n’étaient pas adaptés à la production d’images de haute qualité. Cela a conduit au développement de techniques plus performantes.
Modèles autorégressifs
Les modèles autorégressifs créent également des images pixel par pixel, en utilisant les pixels précédents pour prédire le suivant. Ces modèles étaient utiles mais lents, ce qui a réduit leur popularité avec le temps. Cependant, ils ont inspiré des modèles plus récents et plus rapides.
Compréhension du texte par l’IA pour la création d’images
Certains modèles d’IA peuvent transformer des mots écrits en images. Ces modèles utilisent des grands modèles de langage (LLM) pour comprendre les descriptions et générer des images correspondantes. Par exemple, si vous tapez « un chat assis sur une plage au coucher du soleil », l’IA créera une image basée sur cette description.
Des modèles d’IA comme DALL-E d’OpenAI et Imagen de Google utilisent une compréhension avancée du langage pour améliorer la correspondance entre les descriptions textuelles et les images générées. Cela est rendu possible grâce au traitement du langage naturel (NLP), qui aide l’IA à convertir les mots en nombres servant à guider la création d’images.
Réseaux antagonistes génératifs (GANs)
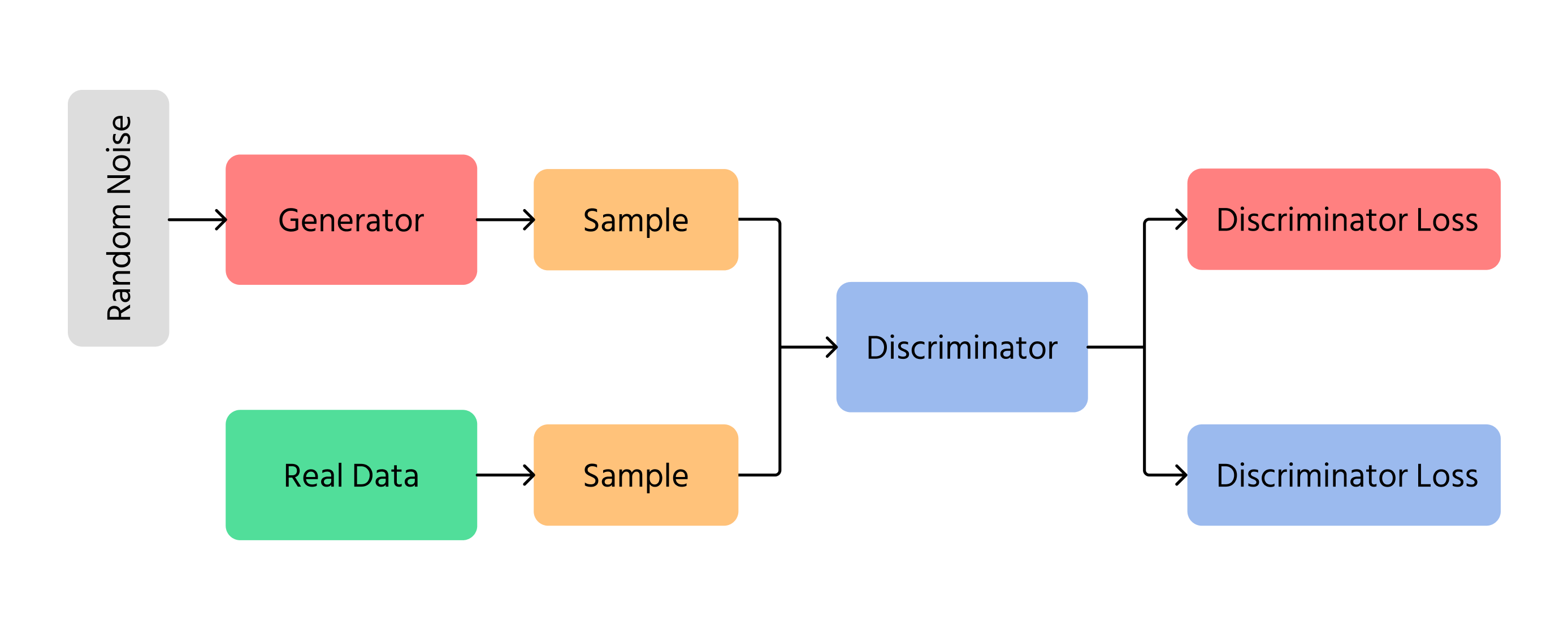
L’une des avancées majeures dans la génération d’images par l’IA a été celle des réseaux antagonistes génératifs (GANs). Les GANs fonctionnent à l’aide de deux réseaux neuronaux distincts :
- Générateur : crée de nouvelles images à partir de rien ;
- Discriminateur : vérifie si les images semblent réelles ou artificielles.
Le générateur tente de produire des images si réalistes que le discriminateur ne peut pas distinguer les fausses des vraies. Avec le temps, les images s’améliorent et ressemblent de plus en plus à des photographies réelles. Les GANs sont utilisés dans la technologie deepfake, la création artistique et l’amélioration de la qualité des images.
Autoencodeurs Variationnels (VAE)
Les VAE représentent une autre méthode permettant à l'IA de générer des images. Au lieu d'utiliser la compétition comme les GAN, les VAE encodent et décodent les images en utilisant la probabilité. Ils fonctionnent en apprenant les motifs sous-jacents d'une image, puis en la reconstruisant avec de légères variations. L'aspect probabiliste des VAE garantit que chaque image générée est légèrement différente, apportant ainsi diversité et créativité.
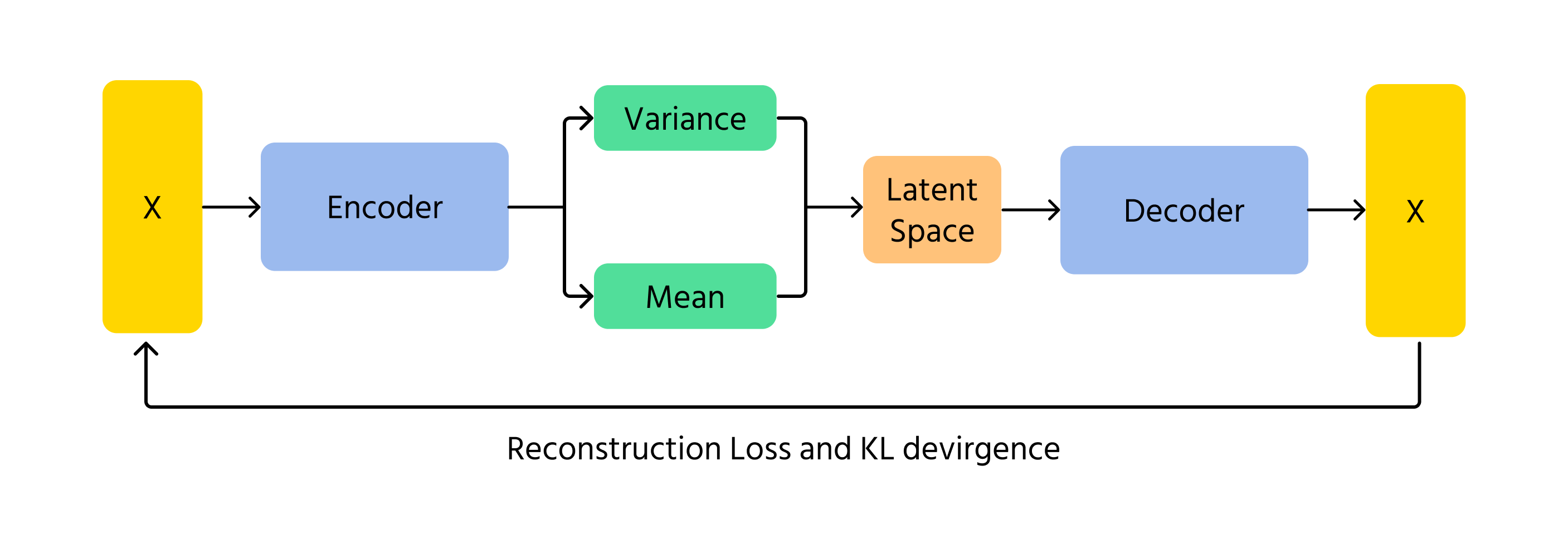
Un concept clé dans les VAE est la divergence de Kullback-Leibler (KL), qui mesure la différence entre la distribution apprise et une distribution normale standard. En minimisant la divergence KL, les VAE garantissent que les images générées restent réalistes tout en permettant des variations créatives.
Fonctionnement des VAE
- Encodage : les données d'entrée x sont transmises à l'encodeur, qui produit les paramètres de la distribution de l'espace latent q(z∣x) (moyenne μ et variance σ²) ;
- Échantillonnage dans l'espace latent : les variables latentes z sont échantillonnées à partir de la distribution q(z∣x) en utilisant des techniques comme le truc de reparamétrisation ;
- Décodage et reconstruction : le z échantillonné est passé dans le décodeur pour produire les données reconstruites x̂, qui doivent être similaires à l'entrée originale x.
Les VAE sont utiles pour des tâches telles que la reconstruction de visages, la génération de nouvelles versions d'images existantes, et la création de transitions fluides entre différentes images.
Modèles de diffusion
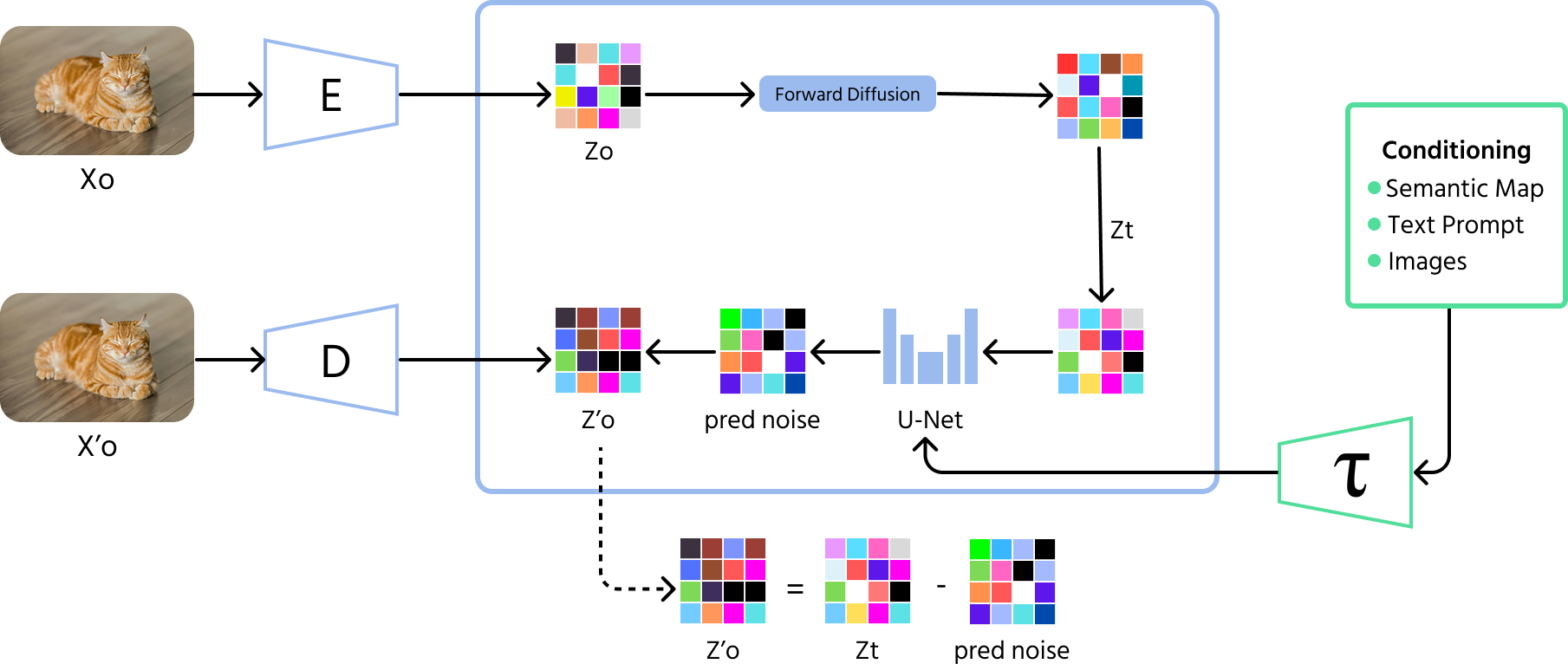
Les modèles de diffusion représentent la dernière avancée dans la génération d'images par l'IA. Ces modèles commencent avec du bruit aléatoire et améliorent progressivement l'image étape par étape, comme si l'on effaçait des parasites d'une photo floue. Contrairement aux GAN, qui produisent parfois des variations limitées, les modèles de diffusion peuvent générer une plus grande diversité d'images de haute qualité.
Fonctionnement des modèles de diffusion
- Processus direct (ajout de bruit) : le modèle commence par ajouter du bruit aléatoire à une image sur de nombreuses étapes jusqu'à ce qu'elle devienne totalement méconnaissable ;
- Processus inverse (suppression du bruit) : le modèle apprend ensuite à inverser ce processus, en supprimant progressivement le bruit étape par étape pour retrouver une image significative ;
- Entraînement : les modèles de diffusion sont entraînés à prédire et à supprimer le bruit à chaque étape, ce qui leur permet de générer des images claires et de haute qualité à partir de bruit aléatoire.
Un exemple populaire est MidJourney, DALL-E et Stable Diffusion, connu pour produire des images réalistes et artistiques. Les modèles de diffusion sont largement utilisés pour l'art généré par l'IA, la synthèse d'images haute résolution et les applications de conception créative.
Exemples d'images générées par des modèles de diffusion

Image réaliste d'un joueur de basket-ball avec une barbe, portant un uniforme jaune-violet, réalisant un dunk et battant des démons lors d'un match de basket-ball, toute l'action se déroulant en enfer.

Photo artistique surréaliste et magnifique d'une Volkswagen Golf GTI blanche de 1990 dans un champ infini de fleurs blanches en harmonie avec la nature, au milieu de collines sans fin couvertes de fleurs, botanique, lumière naturelle, artistique, brumeux, photoréaliste surréaliste ultra détaillé, film Kodak, lumière naturelle, objectif grand angle, f 1.20

Peinture d'un chien Caniche beige allongé sur un canapé vert avec un coussin rayé vert et blanc, dans le style de Fairfield Porter, expressionnisme abstrait, avec des coups de pinceau audacieux sur un fond beige

Gros plan extrême sur la peau d'une femme méditerranéenne ou latino-américaine, mettant en évidence un type de peau mixte avec une brillance visible sur le front et le nez, tandis que les joues apparaissent plus sèches et légèrement squameuses. Les pores sont plus visibles dans la zone T, et une brillance naturelle reflète la production de sébum. La peau présente un mélange de sous-tons chauds et dorés, avec une texture irrégulière due à différents niveaux d'hydratation. Un éclairage doux et naturel accentue le contraste réaliste entre les zones sèches et grasses. L'arrière-plan est flou, gardant l'attention sur le teint.
Défis et préoccupations éthiques
Même si les images générées par l'IA sont impressionnantes, elles présentent des défis :
- Manque de contrôle : l'IA ne génère pas toujours exactement ce que l'utilisateur souhaite ;
- Puissance de calcul : la création d'images IA de haute qualité nécessite des ordinateurs puissants et coûteux ;
- Biais dans les modèles IA : puisque l'IA apprend à partir d'images existantes, elle peut parfois reproduire les biais présents dans les données.
Il existe également des préoccupations éthiques :
- À qui appartient l'art généré par l'IA ? : si une IA crée une œuvre, la personne qui a utilisé l'IA en est-elle propriétaire, ou appartient-elle à l'entreprise qui a développé l'IA ?
- Images truquées et deepfakes : les GAN peuvent être utilisés pour créer de fausses images réalistes, ce qui peut entraîner de la désinformation et des problèmes de confidentialité.
Utilisations actuelles de la génération d'images par IA
Les images générées par l'IA ont déjà un impact important dans différents secteurs :
- Divertissement : les jeux vidéo, les films et l'animation utilisent l'IA pour créer des décors, des personnages et des effets ;
- Mode : les créateurs utilisent l'IA pour concevoir de nouveaux styles vestimentaires, et les boutiques en ligne proposent des essayages virtuels aux clients ;
- Design graphique : l'IA aide les artistes et designers à créer rapidement des logos, affiches et supports marketing.
L'avenir de la génération d'images par l'IA
À mesure que la génération d'images par l'IA continue de progresser, elle transforme la manière dont les images sont créées et utilisées. Que ce soit dans l'art, les affaires ou le divertissement, l'IA ouvre de nouvelles possibilités et rend le travail créatif plus accessible et stimulant.
1. Quel est le principal objectif de la génération d'images par l'IA ?
2. Comment fonctionnent les réseaux antagonistes génératifs (GAN) ?
3. Quel modèle d'IA commence avec du bruit aléatoire et améliore l'image étape par étape ?
Merci pour vos commentaires !
Demandez à l'IA
Demandez à l'IA

Posez n'importe quelle question ou essayez l'une des questions suggérées pour commencer notre discussion
Aperçu de la Génération d'Images
Les images générées par l’IA transforment la création artistique, le design et le contenu numérique. Grâce à l’intelligence artificielle, les ordinateurs peuvent désormais produire des images réalistes, enrichir les œuvres créatives et même soutenir les entreprises. Dans ce chapitre, présentation des méthodes de création d’images par l’IA, des différents types de modèles de génération d’images et de leurs applications concrètes.
Comment l’IA crée des images
La génération d’images par l’IA fonctionne en apprenant à partir d’une vaste collection de photos. L’IA analyse les motifs présents dans ces images, puis en crée de nouvelles qui leur ressemblent. Cette technologie a beaucoup progressé au fil des années, produisant des images de plus en plus réalistes et créatives. Elle est désormais utilisée dans les jeux vidéo, le cinéma, la publicité et même la mode.
Méthodes initiales : PixelRNN et PixelCNN
Avant les modèles d’IA avancés actuels, les chercheurs ont développé des méthodes de génération d’images comme PixelRNN et PixelCNN. Ces modèles créaient des images en prédisant un pixel à la fois.
- PixelRNN : utilise un réseau de neurones récurrents (RNN) pour prédire les couleurs des pixels successivement. Bien que performant, il était très lent ;
- PixelCNN : amélioration de PixelRNN grâce à l’utilisation de couches convolutionnelles, ce qui a accéléré la création d’images.
Même si ces modèles représentaient une avancée, ils n’étaient pas adaptés à la production d’images de haute qualité. Cela a conduit au développement de techniques plus performantes.
Modèles autorégressifs
Les modèles autorégressifs créent également des images pixel par pixel, en utilisant les pixels précédents pour prédire le suivant. Ces modèles étaient utiles mais lents, ce qui a réduit leur popularité avec le temps. Cependant, ils ont inspiré des modèles plus récents et plus rapides.
Compréhension du texte par l’IA pour la création d’images
Certains modèles d’IA peuvent transformer des mots écrits en images. Ces modèles utilisent des grands modèles de langage (LLM) pour comprendre les descriptions et générer des images correspondantes. Par exemple, si vous tapez « un chat assis sur une plage au coucher du soleil », l’IA créera une image basée sur cette description.
Des modèles d’IA comme DALL-E d’OpenAI et Imagen de Google utilisent une compréhension avancée du langage pour améliorer la correspondance entre les descriptions textuelles et les images générées. Cela est rendu possible grâce au traitement du langage naturel (NLP), qui aide l’IA à convertir les mots en nombres servant à guider la création d’images.
Réseaux antagonistes génératifs (GANs)
L’une des avancées majeures dans la génération d’images par l’IA a été celle des réseaux antagonistes génératifs (GANs). Les GANs fonctionnent à l’aide de deux réseaux neuronaux distincts :
- Générateur : crée de nouvelles images à partir de rien ;
- Discriminateur : vérifie si les images semblent réelles ou artificielles.
Le générateur tente de produire des images si réalistes que le discriminateur ne peut pas distinguer les fausses des vraies. Avec le temps, les images s’améliorent et ressemblent de plus en plus à des photographies réelles. Les GANs sont utilisés dans la technologie deepfake, la création artistique et l’amélioration de la qualité des images.
Autoencodeurs Variationnels (VAE)
Les VAE représentent une autre méthode permettant à l'IA de générer des images. Au lieu d'utiliser la compétition comme les GAN, les VAE encodent et décodent les images en utilisant la probabilité. Ils fonctionnent en apprenant les motifs sous-jacents d'une image, puis en la reconstruisant avec de légères variations. L'aspect probabiliste des VAE garantit que chaque image générée est légèrement différente, apportant ainsi diversité et créativité.
Un concept clé dans les VAE est la divergence de Kullback-Leibler (KL), qui mesure la différence entre la distribution apprise et une distribution normale standard. En minimisant la divergence KL, les VAE garantissent que les images générées restent réalistes tout en permettant des variations créatives.
Fonctionnement des VAE
- Encodage : les données d'entrée x sont transmises à l'encodeur, qui produit les paramètres de la distribution de l'espace latent q(z∣x) (moyenne μ et variance σ²) ;
- Échantillonnage dans l'espace latent : les variables latentes z sont échantillonnées à partir de la distribution q(z∣x) en utilisant des techniques comme le truc de reparamétrisation ;
- Décodage et reconstruction : le z échantillonné est passé dans le décodeur pour produire les données reconstruites x̂, qui doivent être similaires à l'entrée originale x.
Les VAE sont utiles pour des tâches telles que la reconstruction de visages, la génération de nouvelles versions d'images existantes, et la création de transitions fluides entre différentes images.
Modèles de diffusion
Les modèles de diffusion représentent la dernière avancée dans la génération d'images par l'IA. Ces modèles commencent avec du bruit aléatoire et améliorent progressivement l'image étape par étape, comme si l'on effaçait des parasites d'une photo floue. Contrairement aux GAN, qui produisent parfois des variations limitées, les modèles de diffusion peuvent générer une plus grande diversité d'images de haute qualité.
Fonctionnement des modèles de diffusion
- Processus direct (ajout de bruit) : le modèle commence par ajouter du bruit aléatoire à une image sur de nombreuses étapes jusqu'à ce qu'elle devienne totalement méconnaissable ;
- Processus inverse (suppression du bruit) : le modèle apprend ensuite à inverser ce processus, en supprimant progressivement le bruit étape par étape pour retrouver une image significative ;
- Entraînement : les modèles de diffusion sont entraînés à prédire et à supprimer le bruit à chaque étape, ce qui leur permet de générer des images claires et de haute qualité à partir de bruit aléatoire.
Un exemple populaire est MidJourney, DALL-E et Stable Diffusion, connu pour produire des images réalistes et artistiques. Les modèles de diffusion sont largement utilisés pour l'art généré par l'IA, la synthèse d'images haute résolution et les applications de conception créative.
Exemples d'images générées par des modèles de diffusion
Image réaliste d'un joueur de basket-ball avec une barbe, portant un uniforme jaune-violet, réalisant un dunk et battant des démons lors d'un match de basket-ball, toute l'action se déroulant en enfer.
Photo artistique surréaliste et magnifique d'une Volkswagen Golf GTI blanche de 1990 dans un champ infini de fleurs blanches en harmonie avec la nature, au milieu de collines sans fin couvertes de fleurs, botanique, lumière naturelle, artistique, brumeux, photoréaliste surréaliste ultra détaillé, film Kodak, lumière naturelle, objectif grand angle, f 1.20
Peinture d'un chien Caniche beige allongé sur un canapé vert avec un coussin rayé vert et blanc, dans le style de Fairfield Porter, expressionnisme abstrait, avec des coups de pinceau audacieux sur un fond beige
Gros plan extrême sur la peau d'une femme méditerranéenne ou latino-américaine, mettant en évidence un type de peau mixte avec une brillance visible sur le front et le nez, tandis que les joues apparaissent plus sèches et légèrement squameuses. Les pores sont plus visibles dans la zone T, et une brillance naturelle reflète la production de sébum. La peau présente un mélange de sous-tons chauds et dorés, avec une texture irrégulière due à différents niveaux d'hydratation. Un éclairage doux et naturel accentue le contraste réaliste entre les zones sèches et grasses. L'arrière-plan est flou, gardant l'attention sur le teint.
Défis et préoccupations éthiques
Même si les images générées par l'IA sont impressionnantes, elles présentent des défis :
- Manque de contrôle : l'IA ne génère pas toujours exactement ce que l'utilisateur souhaite ;
- Puissance de calcul : la création d'images IA de haute qualité nécessite des ordinateurs puissants et coûteux ;
- Biais dans les modèles IA : puisque l'IA apprend à partir d'images existantes, elle peut parfois reproduire les biais présents dans les données.
Il existe également des préoccupations éthiques :
- À qui appartient l'art généré par l'IA ? : si une IA crée une œuvre, la personne qui a utilisé l'IA en est-elle propriétaire, ou appartient-elle à l'entreprise qui a développé l'IA ?
- Images truquées et deepfakes : les GAN peuvent être utilisés pour créer de fausses images réalistes, ce qui peut entraîner de la désinformation et des problèmes de confidentialité.
Utilisations actuelles de la génération d'images par IA
Les images générées par l'IA ont déjà un impact important dans différents secteurs :
- Divertissement : les jeux vidéo, les films et l'animation utilisent l'IA pour créer des décors, des personnages et des effets ;
- Mode : les créateurs utilisent l'IA pour concevoir de nouveaux styles vestimentaires, et les boutiques en ligne proposent des essayages virtuels aux clients ;
- Design graphique : l'IA aide les artistes et designers à créer rapidement des logos, affiches et supports marketing.
L'avenir de la génération d'images par l'IA
À mesure que la génération d'images par l'IA continue de progresser, elle transforme la manière dont les images sont créées et utilisées. Que ce soit dans l'art, les affaires ou le divertissement, l'IA ouvre de nouvelles possibilités et rend le travail créatif plus accessible et stimulant.
Merci pour vos commentaires !
