Apprentissage par Transfert en Vision par Ordinateur
Glissez pour afficher le menu
L'apprentissage par transfert permet de réutiliser des modèles entraînés sur de grands ensembles de données pour de nouvelles tâches disposant de peu de données. Au lieu de construire un réseau de neurones à partir de zéro, on exploite des modèles pré-entraînés afin d'améliorer l'efficacité et les performances. Tout au long de ce cours, vous avez déjà rencontré des approches similaires dans les sections précédentes, qui ont posé les bases pour appliquer efficacement l'apprentissage par transfert.
Qu'est-ce que l'apprentissage par transfert ?
L'apprentissage par transfert est une technique où un modèle entraîné sur une tâche est adapté à une autre tâche connexe. En vision par ordinateur, des modèles pré-entraînés sur de grands ensembles de données comme ImageNet peuvent être ajustés pour des applications spécifiques telles que l'imagerie médicale ou la conduite autonome.
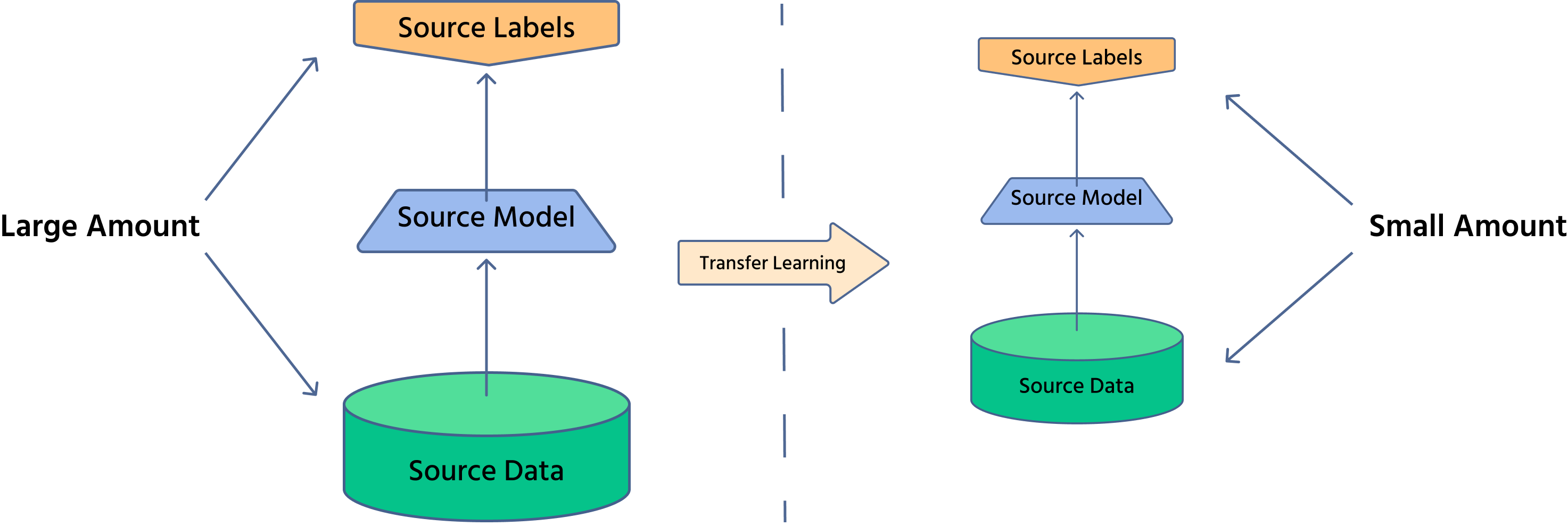
Pourquoi l'apprentissage par transfert est-il important ?
- Réduction du temps d'entraînement : le modèle a déjà appris des caractéristiques générales, seuls de légers ajustements sont nécessaires ;
- Moins de données requises : utile lorsque l'obtention de données annotées est coûteuse ;
- Amélioration des performances : les modèles pré-entraînés offrent une extraction de caractéristiques robuste, augmentant la précision.
Flux de travail de l'apprentissage par transfert
Le flux de travail typique de l'apprentissage par transfert comprend plusieurs étapes clés :
-
Sélection d'un modèle pré-entraîné :
- Choix d'un modèle entraîné sur un grand jeu de données (par exemple, ResNet, VGG, YOLO) ;
- Ces modèles ont appris des représentations utiles pouvant être adaptées à de nouvelles tâches.
-
Modification du modèle pré-entraîné :
- Extraction de caractéristiques : geler les premières couches et n'entraîner que les couches finales pour la nouvelle tâche ;
- Ajustement fin : dégeler certaines ou toutes les couches et les réentraîner sur le nouveau jeu de données.
-
Entraînement sur le nouveau jeu de données :
- Entraînement du modèle modifié à l'aide d'un jeu de données plus petit spécifique à la tâche cible ;
- Optimisation à l'aide de techniques telles que la rétropropagation et les fonctions de perte.
-
Évaluation et itération :
- Évaluation des performances à l'aide de métriques telles que la précision, le rappel, l'exactitude et le mAP ;
- Ajustement supplémentaire si nécessaire pour améliorer les résultats.
Modèles pré-entraînés populaires
Parmi les modèles pré-entraînés les plus utilisés en vision par ordinateur, on trouve :
- ResNet : réseaux résiduels profonds permettant l'entraînement d'architectures très profondes ;
- VGG : architecture simple avec des couches de convolution uniformes ;
- EfficientNet : optimisé pour une grande précision avec moins de paramètres ;
- YOLO : détection d'objets en temps réel à la pointe de la technologie (SOTA).
Ajustement fin vs. Extraction de caractéristiques
Extraction de caractéristiques consiste à utiliser les couches d’un modèle pré-entraîné comme extracteurs de caractéristiques fixes. Dans cette approche, la couche de classification finale du modèle original est généralement supprimée et remplacée par une nouvelle couche spécifique à la tâche cible. Les couches pré-entraînées restent gelées, c’est-à-dire que leurs poids ne sont pas mis à jour pendant l’entraînement, ce qui accélère l’apprentissage et nécessite moins de données.
from tensorflow.keras.applications import VGG16
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Flatten
base_model = VGG16(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
for layer in base_model.layers:
layer.trainable = False # Freeze base model layers
x = Flatten()(base_model.output)
x = Dense(256, activation='relu')(x)
x = Dense(10, activation='softmax')(x) # Task-specific output
model = Model(inputs=base_model.input, outputs=x)
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Ajustement fin, en revanche, va plus loin en dégelant certaines ou toutes les couches pré-entraînées et en les réentraînant sur le nouveau jeu de données. Cela permet au modèle d’adapter les caractéristiques apprises plus précisément aux spécificités de la nouvelle tâche, ce qui conduit souvent à de meilleures performances—en particulier lorsque le nouveau jeu de données est suffisamment volumineux ou diffère significativement des données d’entraînement d’origine.
for layer in base_model.layers[-10:]: # Unfreeze last 10 layers
layer.trainable = True
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Applications de l’apprentissage par transfert
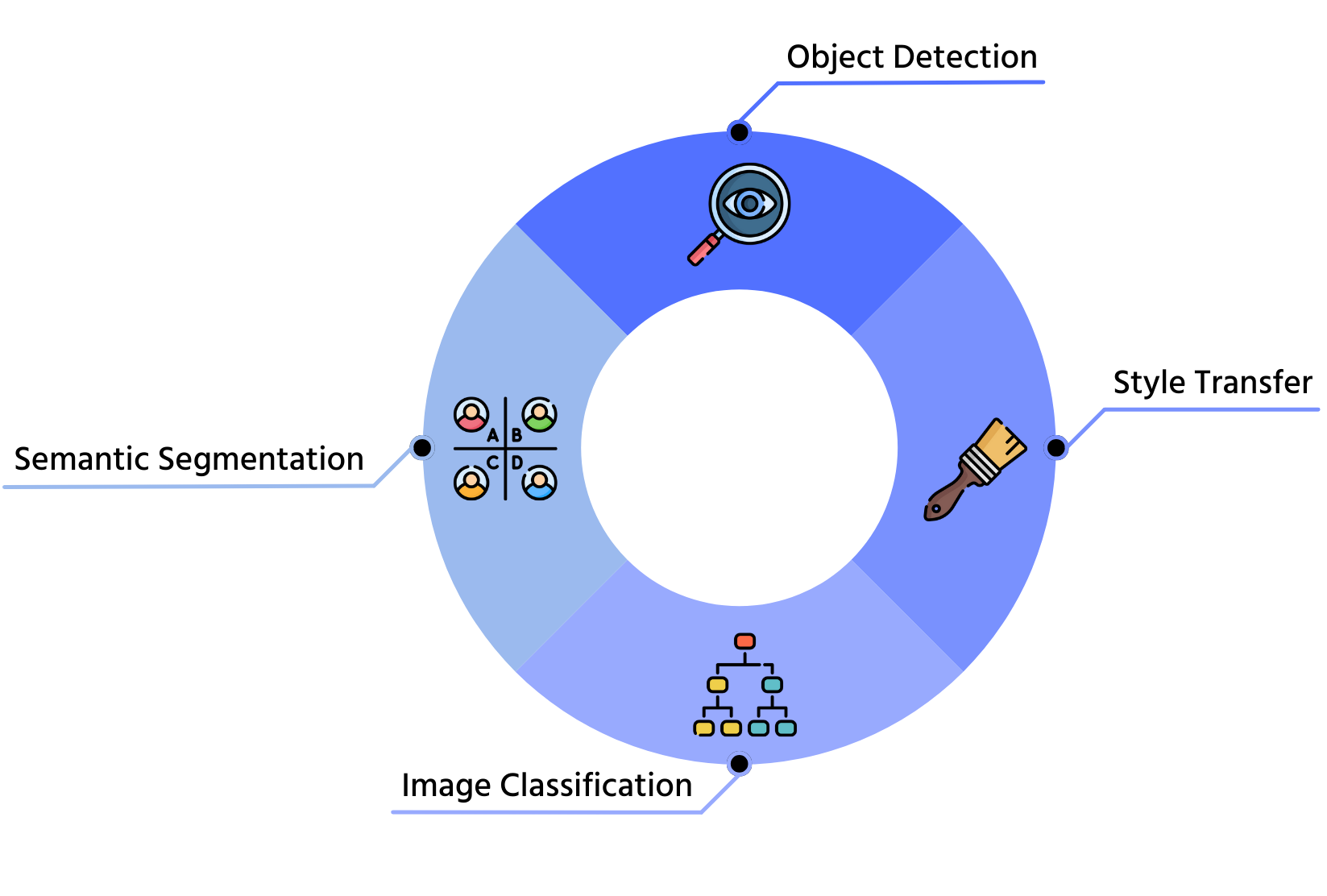
1. Classification d’images
La classification d’images consiste à attribuer des étiquettes aux images en fonction de leur contenu visuel. Des modèles pré-entraînés comme ResNet et EfficientNet peuvent être adaptés à des tâches spécifiques telles que l’imagerie médicale ou la classification de la faune.
Exemple :
- Sélection d’un modèle pré-entraîné (par exemple, ResNet) ;
- Modification de la couche de classification pour correspondre aux classes cibles ;
- Ajustement fin avec un taux d’apprentissage plus faible.
2. Détection d’objets
La détection d’objets consiste à identifier et localiser des objets dans une image. L’apprentissage par transfert permet à des modèles comme Faster R-CNN, SSD et YOLO de détecter efficacement des objets spécifiques dans de nouveaux jeux de données.
Exemple :
- Utilisation d’un modèle de détection d’objets pré-entraîné (par exemple, YOLOv8) ;
- Ajustement fin sur un jeu de données personnalisé avec de nouvelles classes d’objets ;
- Évaluation des performances et optimisation en conséquence.
3. Segmentation sémantique
La segmentation sémantique classe chaque pixel d’une image dans des catégories prédéfinies. Des modèles comme U-Net et DeepLab sont largement utilisés dans des applications telles que la conduite autonome et l’imagerie médicale.
Exemple :
- Utilisation d’un modèle de segmentation pré-entraîné (par exemple, U-Net) ;
- Entraînement sur un jeu de données spécifique au domaine ;
- Ajustement des hyperparamètres pour une meilleure précision.
4. Transfert de style
Le transfert de style applique le style visuel d’une image à une autre tout en préservant son contenu original. Cette technique est couramment utilisée dans l’art numérique et l’amélioration d’images, en exploitant des modèles pré-entraînés comme VGG.
Exemple :
- Sélection d’un modèle de transfert de style (par exemple, VGG) ;
- Saisie d’images de contenu et de style ;
- Optimisation pour des résultats visuellement attrayants.
1. Quel est l’avantage principal de l’utilisation de l’apprentissage par transfert en vision par ordinateur ?
2. Quelle approche est utilisée dans l'apprentissage par transfert lorsque seule la dernière couche d'un modèle pré-entraîné est modifiée tandis que les couches précédentes restent inchangées ?
3. Lequel des modèles suivants est couramment utilisé pour l'apprentissage par transfert en détection d'objets ?
Merci pour vos commentaires !
Demandez à l'IA
Demandez à l'IA

Posez n'importe quelle question ou essayez l'une des questions suggérées pour commencer notre discussion
