Boîtes d’Ancrage
Glissez pour afficher le menu
Boîte d’ancrage : boîte englobante prédéfinie avec une taille et un rapport d’aspect fixes, placée à des positions spécifiques sur une image.
Pourquoi les boîtes d’ancrage sont utilisées en détection d’objets
Les boîtes d’ancrage constituent un concept fondamental dans les modèles modernes de détection d’objets tels que Faster R-CNN et YOLO. Elles servent de boîtes de référence prédéfinies qui facilitent la détection d’objets de différentes tailles et proportions, rendant la détection plus rapide et plus fiable.
Au lieu de détecter les objets à partir de zéro, les modèles utilisent les boîtes d’ancrage comme points de départ, les ajustant pour mieux correspondre aux objets détectés. Cette approche améliore l’efficacité et la précision, en particulier pour la détection d’objets à différentes échelles.
Différence entre boîte d’ancrage et boîte englobante
- Boîte d’ancrage : modèle prédéfini servant de référence lors de la détection d’objets ;
- Boîte englobante : boîte prédite finale après ajustement d’une boîte d’ancrage pour correspondre à l’objet réel.

Contrairement aux boîtes englobantes, qui sont ajustées dynamiquement lors de la prédiction, les boîtes d'ancrage sont fixées à des positions spécifiques avant toute détection d'objet. Les modèles apprennent à affiner les boîtes d'ancrage en ajustant leur taille, leur position et leur rapport d'aspect, les transformant finalement en boîtes englobantes finales qui représentent précisément les objets détectés.
Génération des boîtes d'ancrage par un réseau
Les boîtes d'ancrage ne sont pas appliquées directement à une image, mais plutôt aux cartes de caractéristiques extraites de l'image. Après l'extraction des caractéristiques, un ensemble de boîtes d'ancrage est placé sur ces cartes, variant en taille et en rapport d'aspect. Le choix des formes des boîtes d'ancrage est crucial et implique un équilibre entre la détection des petits et des grands objets.
Pour définir les tailles des boîtes d'ancrage, les modèles utilisent généralement un mélange de sélection manuelle et d'algorithmes de regroupement comme K-Means pour analyser le jeu de données et déterminer les formes et tailles d'objets les plus courantes. Ces boîtes d'ancrage prédéfinies sont ensuite appliquées à différents emplacements sur les cartes de caractéristiques. Par exemple, un modèle de détection d'objets peut utiliser des boîtes d'ancrage de tailles (16x16), (32x32), (64x64), avec des rapports d'aspect tels que 1:1, 1:2, and 2:1.
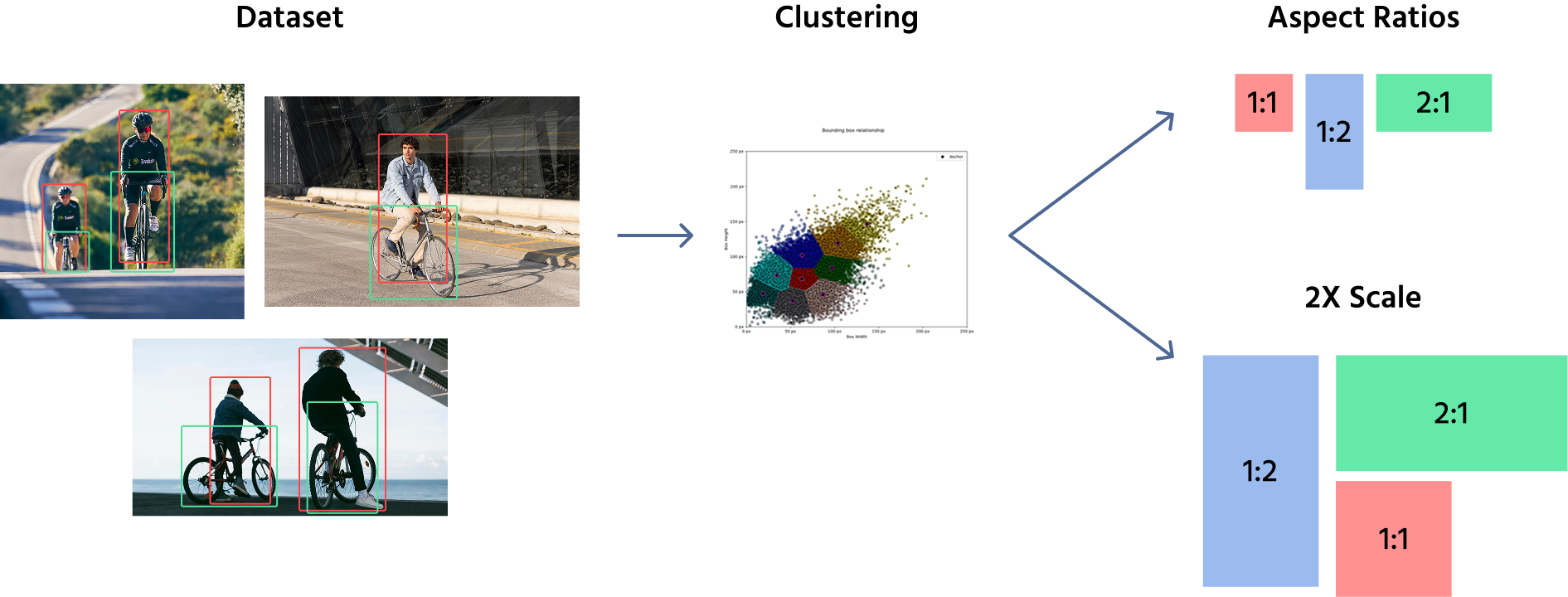
Une fois ces boîtes d'ancrage définies, elles sont appliquées aux cartes de caractéristiques, et non à l'image d'origine. Le modèle assigne plusieurs boîtes d'ancrage à chaque emplacement de la carte de caractéristiques, couvrant différentes formes et tailles. Pendant l'entraînement, le réseau ajuste les boîtes d'ancrage en prédisant des décalages, affinant ainsi leur taille et leur position pour mieux correspondre aux objets.
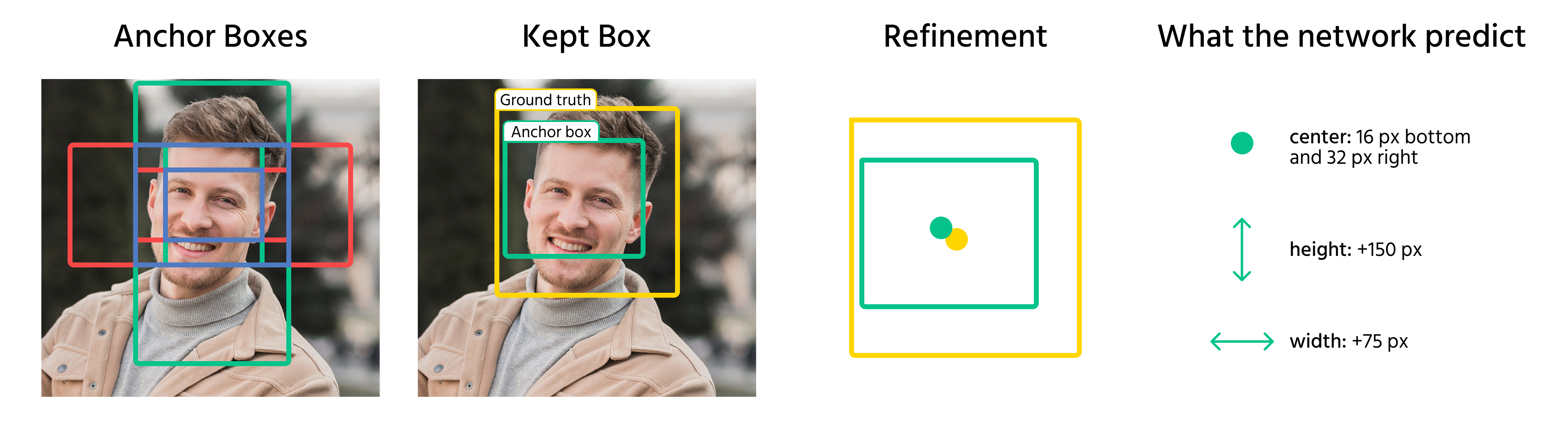
De la boîte d'ancrage à la boîte englobante
Une fois les boîtes d'ancrage assignées aux objets, le modèle prédit des décalages pour les affiner. Ces décalages incluent :
- L'ajustement des coordonnées du centre de la boîte ;
- La mise à l'échelle de la largeur et de la hauteur ;
- Le déplacement de la boîte pour mieux s'aligner avec l'objet.
En appliquant ces transformations, le modèle convertit les boîtes d'ancrage en boîtes englobantes finales qui correspondent précisément aux objets dans une image.
Approches sans ancres ou avec un nombre réduit d’ancres
Bien que les anchor boxes soient largement utilisées, certains modèles cherchent à réduire leur dépendance ou à les éliminer complètement :
- Méthodes sans ancre : des modèles comme
CenterNetetFCOSprédisent directement la localisation des objets sans ancres prédéfinies, ce qui réduit la complexité ; - Approches à nombre d’ancres réduit :
EfficientDetetYOLOv4optimisent le nombre d’anchor boxes utilisées, équilibrant vitesse de détection et précision.
Ces approches visent à améliorer l’efficacité de la détection d’objets tout en maintenant des performances élevées, en particulier pour les applications en temps réel.
En résumé, les anchor boxes constituent un élément essentiel de la détection d’objets, permettant aux modèles de détecter efficacement des objets de différentes tailles et proportions. Cependant, de nouvelles avancées explorent des moyens de réduire ou d’éliminer les anchor boxes pour une détection encore plus rapide et flexible.
1. Quel est le rôle principal des anchor boxes dans la détection d'objets ?
2. En quoi les anchor boxes diffèrent-elles des bounding boxes ?
3. Quelle méthode est couramment utilisée pour déterminer les tailles optimales des anchor boxes ?
Merci pour vos commentaires !
Demandez à l'IA
Demandez à l'IA

Posez n'importe quelle question ou essayez l'une des questions suggérées pour commencer notre discussion
